
In this section all historic news regarding the Collaborative Research Center SFB 876 can be explored.

The Collaborative Research Center 876 has investigated machine learning in the interplay of learning theory, algorithms, implementation, and computer architecture. Innovative methods combine high performance with low resource consumption. De Gruyter has now published the results of this new field of research in three comprehensive open access books.
The first volume establishes the foundations of this new field. It goes through all the steps from data collection, their summary and clustering, to the different aspects of resource-aware learning. These aspects include hardware, memory, energy, and communication awareness.
The second volume comprehensively presents machine learning in astroparticle and particle physics. Here, machine learning is necessary not only to process the vast amounts of data and to detect the relevant examples efficiently. It is also a part of the physics knowledge discovery process itself.
The third volume compiles applications in medicine and engineering. Applications of resource-aware machine learning are presented in detail for medicine, industrial production, traffic for smart cities, and communication networks.
All volumes are made for research, but are also excellent textbooks for teaching.
Reliable AI: Successes, Challenges, and Limitations

Abstract - Artificial intelligence is currently leading to one breakthrough after the other, both in public life with, for instance, autonomous driving and speech recognition, and in the sciences in areas such as medical diagnostics or molecular dynamics. However, one current major drawback is the lack of reliability of such methodologies.
In this lecture we will take a mathematical viewpoint towards this problem, showing the power of such approaches to reliability. We will first provide an introduction into this vibrant research area, focussing specifically on deep neural networks. We will then survey recent advances, in particular, concerning generalization guarantees and explainability. Finally, we will discuss fundamental limitations of deep neural networks and related approaches in terms of computability, which seriously affects their reliability.
Bio - Gitta Kutyniok currently holds a Bavarian AI Chair for Mathematical Foundations of Artificial Intelligence at the Ludwig-Maximilians Universität München. She received her Diploma in Mathematics and Computer Science as well as her Ph.D. degree from the Universität Paderborn in Germany, and her Habilitation in Mathematics in 2006 at the Justus-Liebig Universität Gießen. From 2001 to 2008 she held visiting positions at several US institutions, including Princeton University, Stanford University, Yale University, Georgia Institute of Technology, and Washington University in St. Louis, and was a Nachdiplomslecturer at ETH Zurich in 2014. In 2008, she became a full professor of mathematics at the Universität Osnabrück, and moved to Berlin three years later, where she held an Einstein Chair in the Institute of Mathematics at the Technische Universität Berlin and a courtesy appointment in the Department of Computer Science and Engineering until 2020. In addition, Gitta Kutyniok holds an Adjunct Professorship in Machine Learning at the University of Tromso since 2019.
Gitta Kutyniok has received various awards for her research such as an award from the Universität Paderborn in 2003, the Research Prize of the Justus-Liebig Universität Gießen and a Heisenberg-Fellowship in 2006, and the von Kaven Prize by the DFG in 2007. She was invited as the Noether Lecturer at the ÖMG-DMV Congress in 2013, a plenary lecturer at the 8th European Congress of Mathematics (8ECM) in 2021, the lecturer of the London Mathematical Society (LMS) Invited Lecture Series in 2022, and an invited lecturer at both the International Congress of Mathematicians 2022 and the International Congress on Industrial and Applied Mathematics 2023. Moreover, she became a member of the Berlin-Brandenburg Academy of Sciences and Humanities in 2017, a SIAM Fellow in 2019, and a member of the European Academy of Sciences in 2022. In addition, she was honored by a Francqui Chair of the Belgian Francqui Foundation in 2020. She was Chair of the SIAM Activity Group on Imaging Sciences from 2018-2019 and Vice Chair of the new SIAM Activity Group on Data Science in 2021, and currently serves as Vice President-at-Large of SIAM. She is also the spokesperson of the Research Focus "Next Generation AI" at the Center for Advanced Studies at LMU, and serves as LMU-Director of the Konrad Zuse School of Excellence in Reliable AI.
Gitta Kutyniok's research work covers, in particular, the areas of applied and computational harmonic analysis, artificial intelligence, compressed sensing, deep learning, imaging sciences, inverse problems, and applications to life sciences, robotics, and telecommunication.
Graphs in Space: Graph Embeddings for Machine Learning on Complex Data
https://tu-dortmund.zoom.us/j/97562861334?pwd=akg0RTNXZFZJTmlNZE1kRk01a3AyZz09

Abstract - In today’s world, data in graph and tabular form are being generated at astonishing rates, with algorithms for machine learning (ML) and data mining (DM) applied to such data being established as drivers of modern society. The field of graph embedding is concerned with bridging the “two worlds” of graph data (represented with nodes and edges) and tabular data (represented with rows and columns) by providing means for mapping graphs to tabular data sets, thus unlocking the use of a wide range of tabular ML and DM techniques on graphs. Graph embedding enjoys increased popularity in recent years, with a plethora of new methods being proposed. However, up to now none of them addressed the dimensionality of the new data space with any sort of depth, which is surprising since it is widely known that dimensionalities greater than 10–15 can lead to adverse effects on tabular ML and DM methods, collectively termed the “curse of dimensionality.” In this talk we will present the most interesting results of our project Graphs in Space: Graph Embeddings for Machine Learning on Complex Data (GRASP) where we investigated the impact of the curse of dimensionality on graph-embedding methods by using two well-studied artifacts of high-dimensional tabular data: (1) hubness (highly connected nodes in nearest-neighbor graphs obtained from tabular data) and (2) local intrinsic dimensionality (LID – number of dimensions needed to express the complexity around particular points in the data space based on properties of surrounding distances). After exploring the interactions between existing graph-embedding methods (focusing on node2vec), and hubness and LID, we will describe new methods based on node2vec that take these factors into account, achieving improved accuracy in at least one of two aspects: (1) graph reconstruction and community preservation in the new space, and (2) success of applications of the produced tabular data to the tasks of clustering and classification. Finally, we will discuss the potential for future research, including applications to similarity search and link prediction, as well as extensions to graphs that evolve over time.
Bio - Miloš Radovanović is Professor of Computer Science at the Department of Mathematics and Informatics, Faculty of Sciences, University of Novi Sad, Serbia. His research interests span many areas of data mining and machine learning, with special focus on problems related to high data dimensionality, complex networks, time-series analysis, and text mining, as well as techniques for classification, clustering, and outlier detection. He is Managing Editor of the journal Computer Science and Information Systems (ComSIS) and served as PC member for a large number of international conferences including KDD, ICDM, SDM, AAAI and SISAP.
more...
Rethinking of Computing - Memory-Centric or In-Memory Computing

Abstract - Flash memory opens a window of opportunities to a new world of computing over 20 years ago. Since then, storage devices gain their momentum in performance, energy, and even access behaviors. With over 1000 times in performance improvement over storage in recent years, there is another wave of adventure in removing traditional I/O bottlenecks in computer designs. In this talk, I shall first address the opportunities of new system architectures in computing. In particular, hybrid modules of DRAM and non-volatile memory (NVM) and all NVM-based main memory will be considered. I would also comment on a joint management framework of host/CPU and a hybrid memory module to break down the great memory wall by bridging the process information gap between host/CPU and a hybrid memory module. I will then present some solutions in neuromorphic computing which empower memory chips to own new capabilities in computing. In particular, I shall address challenges in in-memory computing in application co-designs and show how to utilize special characteristics of non-volatile memory in deep learning.
Bio - Prof. Kuo received his B.S.E. and Ph.D. degrees in Computer Science from National Taiwan University and University of Texas at Austin in 1986 and 1994, respectively. He is now Distinguished Professor of Department of Computer Science and Information Engineering of National Taiwan University, where he was an Interim President (2017.10-2019.01) and an Executive Vice President for Academics and Research (2016.08-2019.01). Between August 2019 and July 2022, Prof. Kuo took a leave to join City University of Hong Kong as Lee Shau Kee Chair Professor of Information Engineering, Advisor to President (Information Technology), and Founding Dean of College of Engineering. His research interest includes embedded systems, non-volatile-memory software designs, neuromorphic computing, and real-time systems.
Dr. Kuo is Fellow of ACM, IEEE, and US National Academy of Inventors. He is also a Member of European Academy of Sciences and Arts. He is Vice Chair of ACM SIGAPP and Chair of ACM SIGBED Award Committee. Prof. Kuo received numerous awards and recognition, including Humboldt Research Award (2021) from Alexander von Humboldt Foundation (Germany), Outstanding Technical Achievement and Leadership Award (2017) from IEEE Technical Committee on Real-Time Systems, and Distinguished Leadership Award (2017) from IEEE Technical Committee on Cyber-Physical Systems. Prof. Kuo is the founding Editor-in-Chief of ACM Transactions on Cyber-Physical Systems (2015-2021) and a program committee member of many top conferences. He has over 300 technical papers published in international journals and conferences and received many best paper awards, including the Best Paper Award from ACM/IEEE CODES+ISSS 2019 and 2022 and ACM HotStorage 2021.
more...
The interdisciplinary research area FAIR (together with members of project C4) organizes a two-day workshop on Sequence and Streaming Data Analysis.
This will take place
The goal of the workshop is to provide a basic understanding of similarity measures and classification and clustering algorithms for sequence data and data streams.
We welcome as presenting guests:
Registration is required. More information at:
more...
Data Considerations for Responsible Data-Driven Systems

Abstract - Data-driven systems collect, process and generate data from user interactions. To ensure these processes are responsible, we constrain them with a variety of social, legal, and ethical norms. In this talk, I will discuss several considerations for responsible data governance. I will show how responsibility concepts can be operationalized and highlight the computational and normative challenges that arise when these principles are implemented in practice.
Short bio - Asia J. Biega is a tenure-track faculty member at the Max Planck Institute for Security and Privacy (MPI-SP) leading the Responsible Computing group. Her research centers around developing, examining and computationally operationalizing principles of responsible computing, data governance & ethics, and digital well-being. Before joining MPI-SP, Asia worked at Microsoft Research Montréal in the Fairness, Accountability, Transparency, and Ethics in AI (FATE) Group. She completed her PhD in Computer Science at the MPI for Informatics and the MPI for Software Systems, winning the DBIS Dissertation Award of the German Informatics Society. In her work, Asia engages in interdisciplinary collaborations while drawing from her traditional CS education and her industry experience including stints at Microsoft and Google.
more...

At the SISAP 2022 conference at the University of Bologna, Lars Lenssen (SFB876, Project A2) won the "best student paper" award for the contribution "Lars Lenssen, Erich Schubert. Clustering by Direct Optimization of the Medoid Silhouette. In: Similarity Search and Applications. SISAP 2022. https://doi.org/10.1007/978-3-031-17849-8_15".
The publisher Springer donates a monetary prize for the awards, and the best contributions are invited to submit an extended version to a special issue of the A* journal "Information Systems".
In this paper, we introduce a new clustering method that directly optimizes the Medoid Silhouette, a variant of the popular Silhouette measure of clustering quality. As the new variant is O(k²) times faster than previous approaches, we can cluster data sets larger by orders of magnitude, where large values of k are desirable. The implementation is available in the Rust "kmedoids" crate and the Python module "kmedoids", the code is open source on Github.
The group is successful for the second time: In 2020, Erik Thordsen won the award with the contribution "Erik Thordsen, Erich Schubert. ABID: Angle Based Intrinsic Dimensionality. In: Similarity Search and Applications. SISAP 2020. https://doi.org/10.1007/978-3-030-60936-8_17".
This paper introduced a new angle-based estimator of the intrinsic dimensionality – a measure of local data complexity – traditionally estimated solely from distances.
Causal and counterfactual views of missing data models

Abstract - Modern cryptocurrencies, which are based on a public permissionless blockchain (such as Bitcoin), face tremendous scalability issues: With their broader adoption, conducting (financial) transactions within these systems becomes slow, costly, and resource-intensive. The source of these issues lies in the proof-of-work consensus mechanism that - by design - limits the throughput of transactions in a blockchain-based cryptocurrency. In the last years, several different approaches emerged to improve blockchain scalability. Broadly, these approaches can be categorized into solutions that aim at changing the underlying consensus mechanism (so-called layer-one solutions), and such solutions that aim to minimize the usage of the expensive blockchain consensus by off-loading blockchain computation to cryptographic protocols operating on top of the blockchain (so-called layer-two solutions). In this talk, I will overview the different approaches to improving blockchain scalability and discuss in more detail the workings of layer-two solutions, such as payment channels and payment channel networks.
Short bio - Clara Schneidewind is a Research Group Leader at the Max Planck Institute for Security and Privacy in Bochum. In her research, she aims to develop solutions for the meaningful, secure, resource-saving, and privacy-preserving usage of blockchain technologies. She completed her Ph.D. at the Technical University of Vienna in 2021. In 2019, she was a visiting scholar at the University of Pennsylvania. Since 2021 she leads the Heinz Nixdorf research group for Cryptocurrencies and Smart Contracts at the Max Planck Institute for Security and Privacy funded by the Heinz Nixdorf Foundation.
more...
Causal and counterfactual views of missing data models

Abstract - It is often said that the fundamental problem of causal inference is a missing data problem -- the comparison of responses to two hypothetical treatment assignments is made difficult because for every experimental unit only one potential response is observed. In this talk, we consider the implications of the converse view: that missing data problems are a form of causal inference. We make explicit how the missing data problem of recovering the complete data law from the observed data law can be viewed as identification of a joint distribution over counterfactual variables corresponding to values had we (possibly contrary to fact) been able to observe them. Drawing analogies with causal inference, we show how identification assumptions in missing data can be encoded in terms of graphical models defined over counterfactual and observed variables. We note interesting similarities and differences between missing data and causal inference theories. The validity of identification and estimation results using such techniques rely on the assumptions encoded by the graph holding true. Thus, we also provide new insights on the testable implications of a few common classes of missing data models, and design goodness-of-fit tests around them.
Short bio - Razieh Nabi is a Rollins Assistant Professor in the Department of Biostatistics and Bioinformatics at Emory Rollins School of Public Health. Her research is situated at the intersection of machine learning and statistics, focusing on causal inference and its applications in healthcare and social justice. More broadly, her work spans problems in causal inference, mediation analysis, algorithmic fairness, semiparametric inference, graphical models, and missing data. She has received her PhD (2021) in Computer Science from Johns Hopkins University.
Relevant papers:

At this year's ECML-PKDD (European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases), Andreas Roth and Thomas Liebig (both SFB 876 - B4) received the "Best Paper Award". In their paper "Transforming PageRank into an Infinite-Depth Graph Neural Network" they addressed a weakness of graph neural networks (GNNs). In GNNs, graph convolutions are used to determine appropriate representations for nodes that are supposed to link node features to context within a graph. If graph convolutions are performed multiple times in succession, the individual nodes within the graph lose information instead of benefiting from increased complexity. Since PageRank itself exhibits a similar problem, a long-established variant of PageRank is transformed into a Graph Neural Network. The intuitive derivation brings both theoretical and empirical advantages over several variants that have been widely used so far.
more...
Managing Large Knowledge Graphs: Techniques for Completion and Federated Querying

Abstract - Knowledge Graphs (KGs) allow for modeling inter-connected facts or statements annotated with semantics, in a semi-structured way. Typical applications of KGs include knowledge discovery, semantic search, recommendation systems, question answering, expert systems, and other AI tasks. In KGs, concepts and entities correspond to labeled nodes, while directed, labeled edges model their connections, creating a graph. Following the Linked Open Data initiatives, thousands of KGs have been published on the web represented with the Resource Description Framework (RDF) and queryable with the SPARQL language through different web services or interfaces. In this talk, we will address two relevant problems when managing large KGs. First, we will address the problem of KG completion, which is concerned with completing missing statements in the KG. We will focus on the task of entity type prediction and present an approach using Restricted Boltzmann Machines to learn the latent distribution of labeled edges for the entities in the KG. The solution implements a neural network architecture to predict entity types based on the learned representation. Experimental evidence shows that resulting representations of entities are much more separable with respect to their associations with classes in the KG, compared to existing methods. In the second part of this talk, we will address the problem of federated querying, which requires access to multiple, decentralized and autonomous KG sources. Due to advancements in technologies for publishing KGs on the web, sources can implement different interfaces which differ in their querying expressivity. I will present an interface-aware framework that exploits the capabilities of the member of the federations to speed up the query execution. The results over the FedBench benchmark with large KGs show a substantial improvement in performance by devising our interface-aware approach that exploits the capabilities of heterogeneous interfaces in federations. Finally, this talk will summarize further contributions of our work related to the problem of managing large KGs and conclude with an outlook to future work.
Short bio - Maribel Acosta is an Assistant Professor at the Ruhr-University Bochum, Germany, where she is the Head of the Database and Information Systems Group and a member of the Institute for Neural Computation (INI). Her research interests include query processing over decentralized knowledge graphs and knowledge graph quality with a special focus on completeness. More recently, she has applied Machine Learning approaches to these research topics. Maribel conducted her bachelor and master studies in Computer Science at the Universidad Simon Bolivar, Venezuela. In 2017, she finished her Ph.D. at the Karlsruhe Institute of Technology, Germany, where she was also a Postdoc and Lecturer until 2020. She is an active member of the (Semantic) Web and AI communities, and has acted as Research Track Co-chair (ESWC, SEMANTiCS) and reviewer of top conferences (WWW, AAAI, ICML, NEURIPS, ISWC, ESWC).
https://tu-dortmund.zoom.us/j/91486020936?pwd=bkxEdVZoVE5JMXNzRDJTdDdDZDRrZz09
more...
From September 12-16, 2022, the Collaborative Research Center 876 (CRC 876) at TU Dortmund University hosted its 6th International Summer School 2022 on Resource-aware Machine Learning. In 14 different lectures, the hybrid event allowed the approximately 70 participants present on site and more than 200 registered remote participants to enhance their skills in data analysis (machine learning, data mining, statistics), embedded systems, and applications of the demonstrated analysis techniques. The lectures were given by international experts in these research fields and covered topics such as Deep Learning on FPGAs, efficient Federated Learning, Machine Learning without power consumption, or generalization in Deep Learning.

The on-site participants of the Summer School were CRC 876 members and international guests from eleven different countries. In the Student's Corner of the Summer School - an extended coffee break with poster presentations - they presented their research to each other, exchanged ideas and networked with each other. The Summer School’s hackathon put the participants' practical knowledge of machine learning to the test. In light of the current COVID-19 pandemic, participants were tasked with identifying virus-like nanoparticles using a plasmon-based microscopy sensor in a real-world data analysis scenario. The sensor and the analysis of its data are part of the research work of CRC 876. The goal of the analysis task was to detect samples with virus-like particles and to determine the viral load on an embedded system under resource constraints.
Details and information about the Summer School can be found at: https://sfb876.tu-dortmund.de/summer-school-2022/
Detection and validation of circular DNA fragments by finding plausible paths in a graph representation
Abstract - The presence of extra-chromosomal circular DNA in tumor cells has been acknowledged to be a marker of adverse effects across various cancer types. Detection of such circular fragments is potentially useful for disease monitoring.
Here we present a graph-based approach to detecting circular fragments from long-read sequencing data.
We demonstrate the robustness of the approach by recovering both known circles (such as the mitochondrion) as well as simulated ones.


Biographies:
Alicia Isabell Tüns did her bachelor's degree in biomedical engineering at the University of Applied Sciences Hamm-Lippstadt in 2016. She finished her master's degree in medical biology at the University of Duisburg-Essen in 2018. Since March 2019, she has been working as a Ph.D. student in the biology faculty at the University of Duisburg-Essen. Her research focuses on detecting molecular markers of relapse in lung cancer using nanopore sequencing technology.
Till Hartmann obtained his master's degree in computer science at TU Dortmund in 2017 and has been working as a Ph.D. student in the Genome Informatics group at the Institute of Human Genetics, University Hospital of Essen since then.
more...
CRC 876 Board member, Head of the Research Training Group, and Project Leader in Subproject C3, Prof. Dr. Dr. Wolfgang Rhode, will receive an honorary professorship from the Ruhr University Bochum (RuB) on May 30, 2022. The open event as part of the Physics Colloquium, organized by the Faculty of Physics and Astronomy at RuB, will take place in a hybrid format starting at 12 pm (CEST). The awarding of the honorary professorship will be accompanied by a laudation by Prof. Dr. Reinhard Schlickeiser (RuB). Registration is not required.

The event at a glance:
When: May 30, 2022, 12 pm (CEST) c.t.
Where: Ruhr University Bochum, Faculty of Physics and Astronomy
Universitätsstraße 150
Lecture hall H-NB
Online: Zoom
Prof. Dr. Dr. Wolfgang Rhode holds the professorship for Experimental Physics - Astroparticle Physics at TU Dortmund University. He is involved in the astroparticle experiments AMANDA, IceCube, MAGIC, FACT and CTA and does research in radio astronomy. His focus is on data analysis and the development of Monte Carlo methods as developed in CRC 876. Building on a long-standing collaboration with Katharina Morik on Machine Learning in astroparticle physics within CRC 876, both became co-founders of the DPG working group "Physics, Modern Information Technology and Artificial Intelligence" in 2017. Wolfgang Rhode is deputy speaker of the Collaborative Research Center 1491 - Cosmic Interacting Matters at the Ruhr University Bochum.
more...
The next step of energy-driven computer architecture devoment: In- and near-memory computing

Abstract - The development in the last two decades on the computer architecture side was primarily driven by energy aspects. Of course, the primary goal was to provide more compute performance but since the end of Dennard scaling this was only achievable by reducing the energy requirements in processing, moving and storing of data. This leaded to the development from single-core to multi-core, many-core processors, and increased use of heterogeneous architectures in which multi-core CPUs are co-operating with specialized accelerator cores. The next in this development are near- and in-memory computing concepts, which reduce energy-intensive data movements.
New non-volatile, so-called memristive, memory elements like Resistive RAMs (ReRAMs), Phase Change Memories (PCMs), Spin-torque Magnetic RAMS (STT-MRAMs) or devices with ferroelectric tunnel junctions (FTJs) play a decisive role in this context. They are not only predestined for low power reading but also for processing. In this sense they are devices which can be used in principle for storing and processing. Furthermore, such elements offer multi-bit capability that supports known but due to a so far lack of appropriate technology not realised ternary arithmetic. Furthermore, they are attractive for the use in low-power quantized neural networks. These benefits are opposed by difficulties in writing such elements expressed by low endurance and higher power requirements in writing compared to conventional SRAM or DRAM technology.
These pro and cons have to be carefully weighed against each other during computer design. In the talk wil be presented corresponding architectures examples which were developed by the group of the author and in collaboration work with others. The result of this research brought, e.g. mixed-signal neuromorphic architectures as well as ternary compute circuits for future low-power near- and in-memory computing architectures.
Biographie - Dietmar Fey is a Full Professor of Computer Science with Friedrich-Alexander-University Erlangen-Nürnberg (FAU). After his study in computer science at FAU he received his doctorate with a thesis in the field of Optical Computing in 1992 also at FAU. He was an Associate Professor from 2001 to 2009 for Computer Engineering with University Jena. Since 2009 he leads the Chair for Computer Architecture at FAU. His research interests are in parallel computer architectures, memristive computing, and embedded systems. He authored or co-authored more than 160 papers in proceedings and journals and published three books. Recently, he was involved in the establishing of a DFG priority program about memristive computing and in a research competition project awarded by the BMBF using memristive technology in deep neural networks.
Project C3 is proud to announce their "Workshop on Machine Learning for Astroparticle Physics and Astronomy" (ml.astro), co-located with INFORMATIK 2022.
The workshop will be held on September 26th 2022 in Hamburg, Germany and include invited as well as contributed talks. Contributions should be submitted as full papers of 6 to 10 pages until April 30th 2022 and may include, without being limited to, the following topics:
 Machine learning applications in astroparticle physics and astronomy; Unfolding / deconvolution / quantification; Neural networks and graph neural networks (GNNs); Generative adversarial networks (GANs); Ensemble Methods; Unsupervised learning; Unsupervised domain adaptation; Active class selection; Imbalanced learning; Learning with domain knowledge; Particle reconstruction, tracking, and classification; Monte Carlo simulations Further information on the timeline and the submission of contributions is provided via the workshop website: https://sfb876.tu-dortmund.de/ml.astro/
Machine learning applications in astroparticle physics and astronomy; Unfolding / deconvolution / quantification; Neural networks and graph neural networks (GNNs); Generative adversarial networks (GANs); Ensemble Methods; Unsupervised learning; Unsupervised domain adaptation; Active class selection; Imbalanced learning; Learning with domain knowledge; Particle reconstruction, tracking, and classification; Monte Carlo simulations Further information on the timeline and the submission of contributions is provided via the workshop website: https://sfb876.tu-dortmund.de/ml.astro/
Predictability, a predicament?

Abstract - In the context of AI in general and Machine Learning in particular, predictability is usually considered a blessing. After all – that is the goal: build the model that has the highest predictive performance. The rise of ‘big data’ has in fact vastly improved our ability to predict human behavior thanks to the introduction of much more fine grained and informative features. However, in practice things are more complicated. For many applications, the relevant outcome is observed for very different reasons. In such mixed scenarios, the model will automatically gravitate to the one that is easiest to predict at the expense of the others. This even holds if the more predictable scenario is by far less common or relevant. We present a number of applications across different domains where the availability of highly informative features can have significantly negative impacts on the usefulness of predictive modeling and potentially create second order biases in the predictions. Neither model transparency nor first order data de-biases are ultimately able to mitigate those concerns. The moral imperative of those effects is that as creators of machine learning solutions it is our responsibility to pay attention to the often subtle symptoms and to let our human intuition be the gatekeeper when deciding whether models are ready to be released 'into the wild'.
Short bio - Claudia Perlich started her career at the IBM T.J. Watson Research Center, concentrating on research and application of Machine Learning for complex real-world domains and applications. From 2010 to 2017 she acted as the Chief Scientist at Dstillery where she designed, developed, analyzed, and optimized machine learning that drives digital advertising to prospective customers of brands. Her latest role is Head of Strategic Data Science at TwoSigma where she is creating quantitative strategies for both private and public investments. Claudia continues to be an active public speaker, has over 50 scientific publications, as well as numerous patents in the area of machine learning. She has won many data mining competitions and best paper awards at Knowledge Discovery and Data Mining (KDD) conference, where she served as the General Chair in 2014. Claudia is the past winner of the Advertising Research Foundation’s (ARF) Grand Innovation Award and has been selected for Crain’s New York’s 40 Under 40 list, Wired Magazine’s Smart List, and Fast Company’s 100 Most Creative People. She acts as an advisor to a number of philanthropic organizations including AI for Good, Datakind, Data and Society and others. She received her PhD in Information Systems from the NYU Stern School of Business where she continues to teach as an adjunct professor.
more...
The Chair VIII of the Faculty of Computer Science has an immediate vacancy for a student assistant (SHK / WHF). The number of hours can be discussed individually. The offer is aimed at students of computer science who have completed their studies with very good results.
You can find more information about the positions and your application when clicking "mehr".
more...
Reconciling knowledge-based and data-driven AI for human-in-the-loop machine learning

Abstract - For many practical applications of machine learning it is appropriate or even necessary to make use of human expertise to compensate a too small amount or low quality of data. Taking into account knowledge which is available in explicit form reduces the amount of data needed for learning. Furthermore, even if domain experts cannot formulate knowledge explicitly, they typically can recognize and correct erroneous decisions or actions. This type of implicit knowledge can be injected into the learning process to guide model adapation. In the talk, I will introduce inductive logic programming (ILP) as a powerful interpretable machine learning approach which allows to combine logic and learning. In ILP domain theories, background knowledge, training examples, and the learned model are represented in the same format, namely Horn theories. I will present first ideas how to combine CNNS and ILP into a neuro-symbolic framework. Afterwards, I will address the topic of explanatory AI. I will argue that, although ILP-learned models are symbolic (white-box), it might nevertheless be necessary to explain system decisions. Depending on who needs an explanation for what goal in which situation, different forms of explanations are necessary. I will show how ILP can be combined with different methods for explanation generation and propose a framework for human-in-the-loop learning. There, explanations are designed to be mutual -- not only from the AI system for the human but also the other way around. The presented approach will be illustrated with different application domains from medical diagnostics, file management, and quality control in manufacturing.
Short CV - Ute Schmid is a professor of Applied Computer Science/Cognitive Systems at University of Bamberg since 2004. She received university diplomas both in psychology and in computer science from Technical University Berlin (TUB). She received her doctoral degree (Dr.rer.nat.) in computer science in 1994 and her habilitation in computer science in 2002 from TUB. From 1994 to 2001 she was assistant professor at the Methods of AI/Machine Learning group, Department of Computer Science, TUB. After a one year stay as DFG-funded researcher at Carnegie Mellon University, she worked as lecturer for Intelligent Systems at the Department of Mathematics and Computer Science at University Osnabrück and was member of the Cognitive Science Institute. Ute Schmid is member of the board of directors of the Bavarian Insistute of Digital Transformation (bidt) and a member of the Bavarian AI Council (Bayerischer KI-Rat). Since 2020 she is head of the Fraunhofer IIS project group Comprehensible AI (CAI). Ute Schmid dedicates a significant amount of her time to measures supporting women in computer science and to promote computer science as a topic in elementary, primary, and secondary education. She won the Minerva Award of Informatics Europe 2018 for her university. Since many years, Ute Schmid is engaged in educating the public about artificial intelligence in general and machine learning and she gives workshops for teachers as well as high-school students about AI and machine learning. For her outreach activities she has been awarded with the Rainer-Markgraf-Preis 2020.
more...
Trustworthy Federated Learning

Abstract - Data science is taking the world by storm, but its confident application in practice requires that the methods used are effective and trustworthy. This was already a difficult task when data fit onto a desktop computer, but becomes even harder now that data sources are ubiquitous and inherently distributed. In many applications (such as autonomous driving, industrial machines, or healthcare) it is impossible or hugely impractical to gather all their data into one place, not only because of the sheer size but also because of data privacy. Federated learning offers a solution: models are trained only locally and combined to create a well-performing joint model - without sharing data. However, this comes at a cost: unlike classical parallelizations, the result of federated learning is not the same as centralized learning on all data. To make this approach trustworthy, we need to guarantee high model quality (as well as robustness to adversarial examples); this is challenging in particular for deep learning where satisfying guarantees cannot even be given for the centralized case. Simultaneously ensuring data privacy and maintaining effective and communication-efficient training is a huge undertaking. In my talk I will present practically useful and theoretically sound federated learning approaches, and show novel approaches to tackle the exciting open problems on the path to trustworthy federated learning.
Biographie - I am leader of the research group "Trustworthy Machine Learning" at the Institut für KI in der Medizin (IKIM), located at the Ruhr-University Bochum. In 2021 I was a postdoctoral researcher at the CISPA Helmholtz Center for Information Security in the Exploratory Data Analysis group of Jilles Vreeken. From 2019 to 2021 I was a postdoctoral research fellow at Monash University, where I am still an affiliated researcher. From 2011 to 2019 I was a data scientist at Fraunhofer IAIS, where I lead Fraunhofer’s part in the EU project DiSIEM, managing a small research team. Moreover, I was a project-specific consultant and researcher, e.g., for Volkswagen, DHL, and Hussel, and I designed and gave industrial trainings. Since 2014 I was simultaneously a doctoral researcher at the University of Bonn, teaching graduate labs and seminars, and supervising Master’s and Bachelor’s theses. Before that, I worked for 10 years as a software developer.
more...

We are pleased to announce that Dr. Andrea Bommert has received the TU Dortmund University Dissertation Award. She completed her dissertation entitled "Integration of Feature Selection Stability in Model Fitting", with distinction (summa cum laude) earlier this year on January 20, 2021. The dissertation award would have been presented to her on Dec. 16, 2021, during this year's annual academic celebration, but the annual celebration had to be cancelled due to the Corona pandemic.
In her work, Andrea Bommert developed measures for assessing variable selection stability as well as strategies for fitting good models using variable selection stability and successfully applied them. She is a research associate at the Department of Statistics and a member of the Collaborative Research Center 876 (Project A3).
We congratulate her on this year's dissertation award of the TU Dortmund University!

Bernhard Spaan, 25.04.1960 - 9.12.2021, Professor for Experimental Physics at TU Dortmund University since 2004, part of the LHCb collaboration at CERN since the beginning, member of the board of the Dortmund Data Science Center, from the beginning project leader in SFB 876 "C5 Real-Time Analysis and Storage for High-Volume Data from Particle Physics" together with Jens Teubner.
The data acquisition of the large experiments, such as LHCb, is done with devices. And hence Bernhard Spaan even realized data analysis with devices at first. The algorithmic side in addition to statistics and physical experimentation was added by machine learning. He was always concerned with the fundamental questions about the universe, especially about antimatter. He once told me that I could achieve something important with my methods after all, namely physical knowledge. He advanced this knowledge with many collaborations and also pursued it in the SFB 876.
Bernhard Spaan has also championed physics and data analysis in collegial cooperation across faculty boundaries. Together we wrote down a credo on interdisciplinary "Big Volume Data Driven Science" at TU Dortmund. His warm-hearted solidarity with all those who are committed to the university has made the free exchange of ideas among colleagues easy. The long evening of Ursula Gather's election as rector was also very impressive: we stood in the stairwell and Bernhard had a tablet on which we could watch the BVB game that was taking place. When DoDSC was founded, we went to the stadium to celebrate and were lucky enough to see a sensational 4-0 BVB victory. Bernhard exuded so much joie de vivre, combining academics, good wine, sports, and creating academic life together. It is hard to comprehend that his life has now already come to an end.
His death is a great loss for the whole SFB 876, he is missed.
In deep mourning
Katharina Morik
We are pleased to announce that Pierre Haritz (TU Dortmund), Helena Kotthaus (ML2R), Thomas Liebig (SFB 876 - B4) and Lukas Pfahler (SFB 876 - A1) have received the "Best Paper Award" for the paper "Self-Supervised Source Code Annotation from Related Research Papers" at the IEEE ICDM PhD Forum 2021.

To increase the understanding and reusability of third-party source code, the paper proposes a prototype tool based on BERT models. The underlying neural network learns common structures between scientific publications and their implementations based on variables occurring in the text and source code, and will be used to annotate scientific code with information from the respective publication.
more...
Responsible continual learning

Abstract - Lifelong learning from non-stationary data streams remains a long-standing challenge for machine learning as incremental learning might lead to catastrophic forgetting or interference. Existing works mainly focus on how to retain valid knowledge learned thus far without hindering learning new knowledge and refining existing knowledge when necessary. Despite the strong interest on responsible AI, including aspects like fairness, explainability etc, such aspects are not yet addressed in the context of continual learning.
Biographie - Eirini Ntoutsi is a professor for Artificial Intelligence at the Free University (FU) Berlin. Prior to that, she was an associate professor of Intelligent Systems at the Leibniz University of Hanover (LUH), Germany. Before that, she was a post-doctoral researcher at the Ludwig-Maximilians-University (LMU) in Munich. She holds a Ph.D. from the University of Piraeus, Greece, and a master's and diploma in Computer Engineering and Informatics from the University of Patras, Greece. Her research lies in the fields of Artificial Intelligence (AI) and Machine Learning (ML) and aims at designing intelligent algorithms that learn from data continuously following the cumulative nature of human learning while mitigating the risks of the technology and ensuring long-term positive social impact. However responsibility aspects are even more important in such a setting. In this talk, I will cover some of these aspects, namely fairness w.r.t. some protected attribute(s), explainability of model decisions and unlearning due to e.g., malicious instances.
more...
Algorithmic recourse: from theory to practice

Abstract - In this talk I will introduce the concept of algorithmic recourse, which aims to help individuals affected by an unfavorable algorithmic decision to recover from it. First, I will show that while the concept of algorithmic recourse is strongly related to counterfactual explanations, existing methods for the later do not directly provide practical solutions for algorithmic recourse, as they do not account for the causal mechanisms governing the world. Then, I will show theoretical results that prove the need of complete causal knowledge to guarantee recourse and show how algorithmic recourse can be useful to provide novel fairness definitions that short the focus from the algorithm to the data distribution. Such novel definition of fairness allows us to distinguish between situations where unfairness can be better addressed by societal intervention, as opposed to changes on the classifiers. Finally, I will show practical solutions for (fairness in) algorithmic recourse, in realistic scenarios where the causal knowledge is only limited.
Biographie - I am a full Professor on Machine Learning at the Department of Computer Science of Saarland University in Saarbrücken (Germany), and Adjunct Faculty at MPI for Software Systems in Saarbrücken (Germany). I am a fellow of the European Laboratory for Learning and Intelligent Systems ( ELLIS), where I am part of the Robust Machine Learning Program and of the Saarbrücken Artificial Intelligence & Machine learning (Sam) Unit. Prior to this, I was an independent group leader at the MPI for Intelligent Systems in Tübingen (Germany) until the end of the year. I have held a German Humboldt Post-Doctoral Fellowship, and a “Minerva fast track” fellowship from the Max Planck Society. I obtained my PhD in 2014 and MSc degree in 2012 from the University Carlos III in Madrid (Spain), and worked as postdoctoral researcher at the MPI for Software Systems (Germany) and at the University of Cambridge (UK).
more...
Resource-Constrained and Hardware-Accelerated Machine Learning
Abstract - The resource and energy consumption of machine learning is the major topic of the collaborative research center. We are often concerned with the runtime and resource consumption of model training, but little focus is set on the application of trained ML models. However, the continuous application of ML models can quickly outgrow the resources required for its initial training and also inference accuracy. This seminar presents the recent research activities in the A1 project in the context of resource-constrained and hardware-accelerated machine learning. It consists of three parts contributed by Sebastian Buschjaeger (est. 30 min), Christian Hakert (est. 15 min), and Mikail Yayla (est. 15 min).



Talks:
FastInference - Applying Large Models on Small Devices
Speaker: Sebastian Buschjaeger
Abstract: In the first half of my talk I will discuss ensemble pruning and leaf-refinement as approaches to improve the accuracy-resource trade-off of Random Forests. In the second half I will discuss the FastInference tool which combines these optimizations with the execution of models into a single framework.
Gardening Random Forests: Planting, Shaping, BLOwing, Pruning, and Ennobling
Speaker: Christian Hakert
Abstract: While keeping the tree structure untouched, we reshape the memory layout of random forest ensembles. By exploiting architectural properties, as for instance CPU registers, caches or NVM latencies, we multiply the speed for random forest inference without changing their accuracy.
Error Resilient and Efficient BNNs on the Cutting Edge
Speaker: Mikail Yayla
Abstract: BNNs can be optimized for high error resilience. We explore how this can be exploited in the design of efficient hardware for BNNs, by using emerging computing paradigms, such as in-memory and approximate computing.
AI for Processes: Powered by Process Mining

Abstract - Process mining has quickly become a standard way to analyze performance and compliance issues in organizations. Professor Wil van der Aalst, also known as “the godfather of process mining”, will explain what process mining is and reflect on recent developments in process and data science. The abundance of event data and the availability of powerful process mining tools make it possible to remove operational friction in organizations. Process mining reveals how processes behave "in the wild". Seemingly simple processes like Order-to-Cash (OTC) and Purchase-to-Pay (P2P), turn out to be much more complex than anticipated, and process mining software can be used to dramatically improve such processes. This requires a different kind of Artificial Intelligence (AI) and Machine Learning (ML). Germany is world-leading in process mining with the research done at RWTH and software companies such as Celonis. Process mining is also a beautiful illustration how scientific research can lead to innovations and new economic activity.
Biographie - Prof.dr.ir. Wil van der Aalst is a full professor at RWTH Aachen University, leading the Process and Data Science (PADS) group. He is also the Chief Scientist at Celonis, part-time affiliated with the Fraunhofer FIT, and a member of the Board of Governors of Tilburg University. He also has unpaid professorship positions at Queensland University of Technology (since 2003) and the Technische Universiteit Eindhoven (TU/e). Currently, he is also a distinguished fellow of Fondazione Bruno Kessler (FBK) in Trento, deputy CEO of the Internet of Production (IoP) Cluster of Excellence, co-director of the RWTH Center for Artificial Intelligence. His research interests include process mining, Petri nets, business process management, workflow automation, simulation, process modeling, and model-based analysis. Many of his papers are highly cited (he is one of the most-cited computer scientists in the world and has an H-index of 159 according to Google Scholar with over 119,000 citations), and his ideas have influenced researchers, software developers, and standardization committees working on process support. He previously served on the advisory boards of several organizations, including Fluxicon, Celonis, ProcessGold/UiPath, and aiConomix. Van der Aalst received honorary degrees from the Moscow Higher School of Economics (Prof. h.c.), Tsinghua University, and Hasselt University (Dr. h.c.). He is also an IFIP Fellow, IEEE Fellow, ACM Fellow, and an elected member of the Royal Netherlands Academy of Arts and Sciences, the Royal Ho
more...
We are very happy to announce that Pascal Jörke and Christian Wietfeld from project A4 have received the "2nd Place Best Paper Award" for the paper "How Green Networking May Harm Your IoT Network: Impact of Transmit Power Reduction at Night on NB-IoT Performance" at the IEEE World Forum on Internet of Things (WF-IoT) 2021.


The paper is a joint work of the Collaborative Research Center (SFB 876) and PuLS project. Longterm measurements of NB-IoT signal strength in public cellular networks have shown that at night in some cases base stations reduce their transmit power, which leads to a significant performance decrease in latency and energy efficiency by up to a factor of 4, having a substantial impact on battery-powered IoT devices and therefore should be avoided.
While green networking saves energy and money on base station sites, the impact on IoT devices must also be studied. Signal strength measurements show that in NB-IoT networks base stations reduce the transmit power at night or even shut-off, forcing NB-IoT devices to switch in remaining cells with worse signal strength. Therefore, this paper analyses the impact of downlink transmission power reduction at night on the latency, energy consumption, and battery lifetime of NB-IoT devices. For this purpose, extensive latency and energy measurements of acknowledged NB-IoT uplink data transmissions have been performed for various signal strength values. The results show that devices experience increased latency by up to a factor of 3.5 when transmitting at night, depending on signal strength. In terms of energy consumption, a single data transmission uses up to 3.2 times more energy. For a 5 Wh battery, a weak downlink signal at night reduces the device battery lifetime by up to 4 years on a single battery. Devices at the cell edge may even lose the cell connectivity and enter a high power cell search state, reducing the average battery lifetime of these devices to as low as 1 year. Therefore, transmit power reduction at night and cell shut-offs should be minimized or avoided for NB-IoT networks.
Reference: P. Jörke, C. Wietfeld, "How Green Networking May Harm Your IoT Network: Impact of Transmit Power Reduction at Night on NB-IoT Performance", In 2021 IEEE 7th World Forum on Internet of Things (WF-IoT), New Orleans, USA, Juni 2021. [pdf][video]
more...
Using Logic to Understand Learning

Abstract - A fundamental question in Deep Learning today is the following: Why do neural networks generalize when they have sufficient capacity to memorize their training set. In this talk, I will describe how ideas from logic synthesis can help answer this question. In particular, using the idea of small lookup tables, such as those used in FPGAs, we will see if memorization alone can lead to generalization; and then using ideas from logic simulation, we will see if neural networks do in fact behave like lookup tables. Finally, I’ll present a brief overview of a new theory of generalization for deep learning that has emerged from this line of work.
Biography - Sat Chatterjee is an Engineering Leader and Machine Learning Researcher at Google AI. His current research focuses on fundamental questions in deep learning (such as understanding why neural networks generalize at all) as well as various applications of ML (such as hardware design and verification). Before Google, he was a Senior Vice President at Two Sigma, a leading quantitative investment manager, where he founded one of the first successful deep learning-based alpha research groups on Wall Street and led a team that built one of the earliest end-to-end FPGA-based trading systems for general-purpose ultra-low latency trading. Prior to that, he was a Research Scientist at Intel where he worked on microarchitectural performance analysis and formal verification for on-chip networks. He did his undergraduate studies at IIT Bombay, has a PhD in Computer Science from UC Berkeley, and has published in the top machine learning, design automation, and formal verification conferences.

SFB board member and co-project leader of SFB subprojects A1 and A3 Prof. Dr. Jian Jia Chen is General Chair of this year's IEEE Real-Time Systems Symposium (RTSS) from December 7 to 10. The RTSS is the leading conference in the field of real-time systems and provides a forum of exchange and collaboration for researchers and practitioners. The focus hereby lies on theory, design, analysis, implementation, evaluation, and experience concerning real-time systems. This year, the four-day hybrid event, which includes scientific presentations, an Industry Session, a Hot Topic Day, and an Open Demo Session, will be held in Dortmund, Germany.
more...
Learning a Fair Distance Function for Situation Testing

Abstract - Situation testing is a method used in life sciences to prove discrimination. The idea is to put similar testers, who only differ in their membership to a protected-by-law group, in the same situation such as applying for a job. If the instances of the protected-by-law group are consistently treated less favorably than their non-protected counterparts, we assume discrimination occurred. Recently, data-driven equivalents of this practice were proposed, based on finding similar instances with significant differences in treatment between the protected and unprotected ones. A crucial and highly non-trivial component in these approaches, however, is finding a suitable distance function to define similarity in the dataset. This distance function should disregard attributes irrelevant for the classification, and weigh the other attributes according to their relevance for the label. Ideally, such a distance function should not be provided by the analyst but should be learned from the data without depending on external resources like Causal Bayesian Networks. In this paper, we show how to solve this problem based on learning a Weighted Euclidean distance function. We demonstrate how this new way of defining distances improves the performance of current situation testing algorithms, especially in the presence of irrelevant attributes.
Short bio - Daphne Lenders is a PhD researcher at the University of Antwerp where she, under the supervision of prof. Toon Calders studies fairness in Machine Learning. Daphne is especially interested in the requirements of fair ML algorithms, not just from a technical-, but also from a legal and usability perspective. Her interest in ethical AI applications already developed in her Masters, where she dedicated her thesis to the topic of explainable AI.

Sebastian Buschjäger has published the software "Fastinference". It is a model optimizer and model compiler that generates the optimal implementation for a model and a hardware architecture. It supports classical machine learning methods like decision trees and random forests as well as modern deep learning architectures.
more...
Bayesian Data Analysis for quantitative Magnetic Resonance Fingerprinting
Abstract - Magnetic Resonance Imaging (MRI) is a medical imaging technique which is widely used in clinical practice. Usually, only qualitative images are obtained. The goal in quantitative MRI (qMRI) is a quantitative determination of tissue- related parameters. In 2013, Magnetic Resonance Fingerprinting (MRF) was introduced as a fast method for qMRI which simultaneously estimates the parameters of interest. In this talk, I will present main results of my PhD thesis in which I applied Bayesian methods for the data analysis of MRF. A novel, Bayesian uncertainty analysis for the conventional MRF method is introduced as well as a new MRF approach in which the data are modelled directly in the Fourier domain. Furthermore, results from both MRF approaches will be compared with regard to various aspects.
Biographie - Selma Metzner studied Mathematics at Friedrich-Schiller-University in Jena. She then started her PhD at PTB Berlin and successfully defended her thesis in September 2021. Currently she is working on a DFG project with the title: Bayesian compressed sensing for nanoscale chemical mapping in the mid- infrared regime.
GraphAttack+MAPLE: Optimizing Data Supply for Graph Applications on In-Order Multicore Architectures
Abstract - Graph structures are a natural representation for data generated by a wide range of sources. While graph applications have significant parallelism, their pointer indirect accesses to neighbor data hinder scalability. A scalable and efficient system must tolerate latency while leveraging data parallelism across millions of vertices. Existing solutions have shortcomings; modern OoO cores are area- and energy-inefficient, while specialized accelerator and memory hierarchy designs cannot support diverse application demands.In this talk we will describe a full-stack data supply approach, GraphAttack, that accelerates graph applications on in-order multi-core architectures by mitigating latency bottlenecks. GraphAttack's compiler identifies long-latency loads and slices programs along these loads into Producer/Consumer threads to map onto pairs of parallel cores. A specialized hardware unit shared by each core pair, called Memory Access Parallel-Load Engine (MAPLE), allows tracking and buffering of asynchronous loads issued by the Producer whose data are used by the Consumer. In equal-area comparisons via simulation, GraphAttack outperforms OoO cores, do-all parallelism, prefetching, and prior decoupling approaches, achieving a 2.87x speedup and 8.61x gain in energy efficiency across a range of graph applications. These improvements scale; GraphAttack achieves a 3x speedup over 64 parallel cores. Our approach has been further validated on a dual-core FPGA prototype running applications with full SMP Linux, where we have demonstrated speedups of 2.35x and 2.27x over software-based prefetching and decoupling, respectively. Lastly, this approach has been taped out in silicon as part of a manycore chip design.
Short bio



Esin Tureci is an Associate Research Scholar in the Department of Computer Science at Princeton University, working with Professor Margaret Martonosi. Tureci works on a range of research problems in computer architecture design and verification including hardware-software co-design of heterogeneous systems targeting efficient data movement, design of efficient memory consistency model verification tools and more recently, optimization of hybrid classical-quantum computing approaches. Tureci has a PhD in Biophysics from Cornell University and has worked as a high-frequency algorithmic trader prior to her work in Computer Science.
www.cs.princeton.edu/
Aninda Manocha is currently a Computer Science PhD student at Princeton University advised by Margaret Martonosi. Her broad area of research is computer architecture, with specific interests in data supply techniques across the computing stack for graph and other emerging applications with sparse memory access patterns. These techniques span hardware-software co-designs and memory systems. She received her B.S. degrees in Electrical and Computer Engineering and Computer Science from Duke University in 2018 and is a recipient of the NSF Graduate Research Fellowship.
Marcelo Orenes Vera is a PhD candidate in the Department of Computer Science at Princeton University advised by Margaret Martonosi and David Wentzlaff. He received his BSE from University of Murcia. Marcelo is interested in hardware innovations that are modular, to make SoC integration practical. His research focuses on Computer Architecture, from hardware RTL design and verification to software programming models of novel architectures.He has previously worked in the hardware industry at Arm, contributing to the design and verification of three GPU projects. At Princeton, he has contributed in two academic chip tapeouts that aims to improve the performance, power and programmability of several emerging workflows in the broad areas of Machine Learning and Graph Analytics.
more...

The Stanford Graph Learning Workshop on September 16, 2021 will feature two talks from SFB 876. Matthias Fey and Jan Eric Lenssen, from subprojects A6 and B2, will each give a talk about their work on Graph Neural Networks (GNNs). Matthias Fey will talk about his now widely known and used GNN software library PyG (PyTorch Geometric) and its new functionalities in the area of heterogeneous graphs. Jan Eric Lenssen gives an overview of applications of Graph Neural Networks in the areas of computer vision and computer graphics.
Registration to participate in the livestream is available at the following link:
https://www.eventbrite.com/e/stanford-graph-learning-workshop-tickets-167490286957

In a discussion on the topic "Artificial Intelligence: Cutting-edge Research and Applications from NRW", Prof. Dr. Katharina Morik, Head of the Chair of Artificial Intelligence and speaker of the Collaborative Research Center 876, reported live at TU Dortmund University on the research field of Artificial Intelligence and, among other things, on the CRC 876. She hereby explained why Machine Learning is important for securing Germany's future. Participants of the virtual event were able to join in on the live discussion.
A recording of the event is available online!
more...
Runtime and Power-Demand Estimation for Inference on Embedded Neural Network Accelerators
Abstract - Deep learning is an important method and research area in science in general and in computer science in particular. Following the same trend, big companies such as Google implement neural networks in their products, while many new startups dedicate themselves to the topic. The ongoing development of new techniques, caused by the successful use of deep learning methods in many application areas, has led to neural networks becoming more and more complex. This leads to the problem that applications of deep learning are often associated with high computing costs, high energy consumption, and memory requirements. General-purpose hardware can no longer adapt to these growing demands, while cloud-based solutions can not meet the high bandwidth, low power, and real-time requirements of many deep learning applications. In the search for embedded solutions, special purpose hardware is designed to accelerate deep learning applications in an efficient manner, many of which are tailored for applications on the edge. But such embedded devices have typically limited resources in terms of computation power, on-chip memory, and available energy. Therefore, neural networks need to be designed to not only be accurate but to leverage such limited resources carefully. Developing neural networks with their resource consumption in mind requires knowledge about these non-functional properties, so methods for estimating the resource requirements of a neural network execution must be provided. Featuring this idea, the presentation presents an approach to create resource models using common machine learning methods like random forest regression. Those resource models aim at the execution time and power requirements of artificial neural networks which are executed on an embedded deep learning accelerator hardware. In addition, measurement-based evaluation results are shown, using an Edge Tensor Processing Unit as a representative of the emerging hardware for embedded deep learning acceleration.

Judith about herself - I am one of the students who studied at the university for a long time and with pleasure. The peaceful humming cips of Friedrich-Alexander University Erlangen-Nuremberg were my home for many years (2012-2020). During this time, I took advantage of the university's rich offerings by participating in competitions (Audi Autonomous Driving Cup 2018, RuCTF 2020, various ICPCs), working at 3 different chairs (Cell Biology, Computer Architecture, Operating Systems) as a tutor/research assistant, not learning two languages (Spanish, Swahili), and enjoying the culinary delights of the Südmensa. I had many enjoyable experiences at the university, but probably one of the best was presenting part of my master's thesis in Austin, Texas during the 'First International Workshop on Benchmarking Machine Learning Workloads on Emerging Hardware' in 2020. After graduation, however, real-life caught up with me and now I am working as a software developer at a company with the pleasant name 'Dr. Schenk GmBH' in Munich where I write fast and modern C++ code.
Github: Inesteem
LinkedIn: judith-hemp-b1bab11b2

Learning in Graph Neural Networks
Abstract - Graph Neural Networks (GNNs) have become a popular tool for learning representations of graph-structured inputs, with applications in computational chemistry, recommendation, pharmacy, reasoning, and many other areas. In this talk, I will show some recent results on learning with message-passing GNNs. In particular, GNNs possess important invariances and inductive biases that affect learning and generalization. We relate these properties and the choice of the “aggregation function” to predictions within and outside the training distribution.
This talk is based on joint work with Keyulu Xu, Jingling Li, Mozhi Zhang, Simon S. Du, Ken-ichi Kawarabayashi, Vikas Garg and Tommi Jaakkola.
Short bio - Stefanie Jegelka is an Associate Professor in the Department of EECS at MIT. She is a member of the Computer Science and AI Lab (CSAIL), the Center for Statistics, and an affiliate of IDSS and the ORC. Before joining MIT, she was a postdoctoral researcher at UC Berkeley, and obtained her PhD from ETH Zurich and the Max Planck Institute for Intelligent Systems. Stefanie has received a Sloan Research Fellowship, an NSF CAREER Award, a DARPA Young Faculty Award, a Google research award, a Two Sigma faculty research award, the German Pattern Recognition Award and a Best Paper Award at the International Conference for Machine Learning (ICML). Her research interests span the theory and practice of algorithmic machine learning.
Fighting Temperature: The Unseen Enemy for Neural processing units (NPUs)
Abstract - Neural processing units (NPUs) are becoming an integral part in all modern computing systems due to their substantial role in accelerating neural networks. In this talk, we will discuss the thermal challenges that NPUs bring, demonstrating how multiply-accumulate (MAC) arrays, which form the heart of any NPU, impose serious thermal bottlenecks to any on-chip systems due to their excessive power densities. We will also discuss how elevated temperatures severely degrade the reliability of on-chip memories, especially when it comes to emerging non-volatile memories, leading to bit errors in the neural network parameters (e.g., weights, activations, etc.). In this talk, we will also discuss: 1) the effectiveness of precision scaling and frequency scaling (FS) in temperature reductions for NPUs and 2) how advanced on-chip cooling using superlattice thin-film thermoelectric (TE) open doors for new tradeoffs between temperature, throughput, cooling cost, and inference accuracy in NPU chips.

Short bio - Dr. Hussam Amrouch is a Junior Professor at the University of Stuttgart heading the Chair of Semiconductor Test and Reliability (STAR) as well as a Research Group Leader at the Karlsruhe Institute of Technology (KIT), Germany. He earned in 06.2015 his Ph.D. degree in Computer Science (Dr.-Ing.) from KIT, Germany with distinction (summa cum laude). After which, he has founded and led the “Dependable Hardware” research group at KIT. Dr. Amrouch has published so far 115+ multidisciplinary publications, including 43 journals, covering several major research areas across the computing stack (semiconductor physics, circuit design, computer architecture, and computer-aided design). His key research interests are emerging nanotechnologies and machine learning for CAD. Dr. Amrouch currently serves as Associate Editor in Integration, the VLSI Journal as well as a guest and reviewer Editor in Frontiers in Neuroscience.
more...
Improving Automatic Speech Recognition for People with Speech Impairment
Abstract - The accuracy of Automatic Speech Recognition (ASR) systems has improved significantly over recent years due to increased computational power of deep learning systems and the availability of large training datasets. Recognition accuracy benchmarks for commercial systems are now as high as 95% for many (mostly typical) speakers and some applications. Despite these improvements, however, recognition accuracy of non-typical and especially disordered speech is still unacceptably low, rendering the technology unusable for the many speakers who could benefit the most from this technology.
Google’s Project Euphonia aims at helping people with atypical speech be better understood. I will give an overview to our large-scale data collection initiative, and present our research on both effective and efficient adaptation of standard-speech ASR models to work well for a large variety and severity of speech impairments.

Short bio - Katrin earned her Ph.D. from University of Dortmund, supervised by Prof Katharina Morik and Prof Udo Hahn (FSU Jena), in 2010. She has since worked on a variety of NLP, Text Mining, and Speech Processing projects, including eg Automated Publication Classification and Keywording for the German National Library, Large-Scale Patent Classification for the European Patent Office, Sentiment Analysis and Recommender Systems at OpenTable, Neural Machine Translation at Google Translate. Since 2019, Katrin leads the research efforts on Automated Speech Recognition for impaired speech within Project Euphonia, an AI4SG initiative within Google Research.
In her free time, Katrin can be found exploring the beautiful outdoors of the Bay Area by bike or kayak.

Random and Adversarial Bit Error Robustness for Energy-Efficient and Secure DNN Accelerators
Abstract - Deep neural network (DNN) accelerators received considerable attention in recent years due to the potential to save energy compared to mainstream hardware. Low-voltage operation of DNN accelerators allows to further reduce energy consumption significantly, however, causes bit-level failures in the memory storing the quantized DNN weights. Furthermore, DNN accelerators have been shown to be vulnerable to adversarial attacks on voltage controllers or individual bits. In this paper, we show that a combination of robust fixed-point quantization, weight clipping, as well as random bit error training (RandBET) or adversarial bit error training (AdvBET) improves robustness against random or adversarial bit errors in quantized DNN weights significantly. This leads not only to high energy savings for low-voltage operation as well as low-precision quantization, but also improves security of DNN accelerators. Our approach generalizes across operating voltages and accelerators, as demonstrated on bit errors from profiled SRAM arrays, and achieves robustness against both targeted and untargeted bit-level attacks. Without losing more than 0.8%/2% in test accuracy, we can reduce energy consumption on CIFAR10 by 20%/30% for 8/4-bit quantization using RandBET. Allowing up to 320 adversarial bit errors, AdvBET reduces test error from above 90% (chance level) to 26.22% on CIFAR10.
References:
https://arxiv.org/abs/2006.13977
https://arxiv.org/abs/2104.08323
Short bio -David Stutz is a PhD student at the Max Planck Institute for Informatics supervised by Prof. Bernt Schiele and co-supervised by Prof. Matthias Hein from the University of Tübingen. He obtained his bachelor and master degrees in computer science from RWTH Aachen University. During his studies, he completed an exchange program with the Georgia Institute of Technology as well as several internships at Microsoft, Fyusion and Hyundai MOBIS, among others. He wrote his master thesis at the Max Planck Institute for Intelligent Systems supervised by Prof. Andreas Geiger. His PhD research focuses on obtaining "robust" deep neural networks, e.g., considering adversarial examples, corrupted examples or out-of-distribution examples. In a collaboration with IBM Research, his recent work improves robustness against bit errors in (quantized) weights to enable energy-efficient and secure accelerators. He received several awards and scholarships including a Qualcomm Innovation Fellowship, RWTH Aachen University's Springorum Denkmünze and the STEM Award IT sponsored by ZF Friedrichshafen. His work has been published at top venues in computer vision and machine learning including CVPR, IJCV, ICML and MLSys.
Please follow the link below to register to attend the presentation.
more...

Andrea Bommert successfully defended her dissertation entitled "Integration of Feature Selection Stability in Model Fitting" on January 20, 2021. She developed measures for assessing variable selection stability as well as strategies for fitting good models using variable selection stability and applied them successfully.
The members of the doctoral committee were Prof. Dr. Jörg Rahnenführer (supervisor and first reviewer), Prof. Dr. Claus Weihs (second reviewer), Prof. Dr. Katja Ickstadt (examination chair), and Dr. Uwe Ligges ( minutes).
Andrea Bommert is a research assistant at the Faculty of Statistics and a member of the Collaborative Research Center 876 (Project A3).
We cordially congratulate her on completing her doctorate!
Jacqueline Schmitt from project B3 successfully defended her dissertation titled "Methodology for process-integrated inspection of product quality by using predictive data mining techniques" on February 04, 2021. The verbal examination took place in digital form. The results of the dissertation were presented in a public 45-minute lecture on Zoom. The examination committee was formed by Prof. Dr.-Ing. Andreas Menzel (examination chairman), Prof. Dr.-Ing. Jochen Deuse (rapporteur), Dr.-Ing. Ralph Richter (co-rapporteur) and Prof. Dr. Claus Weihs (co-examiner).
We cordially congratulate her on completing her doctorate!
Abstract of the thesis -- In the conflicting areas of productivity and customer satisfaction, product quality is becoming increasingly important as a competitive factor for long-term market success. In order to simultaneously counter the steadily increasing cost pressure on the market, this means the consistent concentration on internal company processes that influence quality, in particular to reduce technology-related output losses as well as defect and inspection costs. An essential prerequisite for this, in addition to defect prevention and avoidance, is the early detection of deviations as the basis for process-integrated quality control. Increasingly, growing demands for safety, accuracy and robustness are counteracting the speed and flexibility required in the production process, so that a process-integrated inspection of quality-relevant characteristics can only be carried out to a limited extent using conventional methods of production measurement technology. This implies that quality deviations are not immediately recognised and considerable productivity losses can occur.
In the present work, a holistic methodology for process-integrated inspection of product quality by using predictive data mining algorithms is developed. The core of the methodology is a new, data-based procedure for the conformity assessment of product characteristics by predictive data mining models. In order to integrate this procedure into the existing quality assurance and to guarantee a reliability of the inspection equivalent to conventional measuring and inspection procedures, a holistic methodology for the planning and design of the process-integrated inspection is also developed. While analytical modelling approaches are used at the core of the methodology, the structure is decisively characterised by the integration of expert knowledge. This combination of data- and expert-based modelling enables the functional and plausible mapping of causal, quality-related relationships, so that a contribution is made to reliable quality assurance in industrial production.
The developed method was empirically validated using selected industrial case studies. The results of the validation show that the developed method can generate shortened quality control loops and identify savings and optimisation potentials of the inspection and production processes. The use of predictive quality inspection thus leads to an increase in productivity and a reduction in quality costs.
In January, Tim Ruhe, PI in project C3 was elected spokesperson of the working group on Physics, modern IT and Artificial Intelligence (AKPIK) within the German Physical Society (DPG). The AKPIK is an interdisciplinary forum of scientists, which addresses current questions in the intersection of data-intense analyses in physics and machine learning.

Chances and risks in the application of state-of-the-art machine learning algorithms is discussed in a close collaboration with Computer Scientists and representatives from industry 4.0. Furthermore, suggestions for the competences and profiles of Data Scientists are worked out. Together with Katharina Morik, Tim Ruhe is the second member of the CRC joining the board of the AKPIK. As the successor of Prof. Dr. Martin Erdmann (RWTH Aachen), Tim Ruhe will initially hold the position as spokesperson for one year.
more...
The Competence Center Machine Learning Rhine-Ruhr (ML2R) has launched its new blog: https://machinelearning-blog.de. In the categories Application, Research and Foundations, researchers of the Competence Center and renowned guest authors provide exciting insights into scientific results, interdisciplinary projects and industry-related findings surrounding Machine Learning (ML) and Artificial Intelligence (AI). The Competence Center ML2R brings forward-looking technologies and research results to companies and society.

Seven articles already await readers: a four-part series on ML-Basics as well as one article each within the sections Application, Research and Foundations. The authors illustrate why AI must be explainable, how obscured satellite images can be recovered using Machine Learning and show methods for the automated assignment of keywords for short texts.
SFB 876 researcher Sebastian Buschjäger will be featured in the ML2R-Blog with a post on February 3. In his article, Buschjäger details an ML approach, which has been developed in the context of the Collaborative Research Center and allows for the real-time analysis of cosmic gamma rays.
more...

Batteryless Sensing
Abstract - Over the last decade, energy harvesting has seen significant growth as different markets adopt green, sustainable ways to produce electrical energy. Even though costs have fallen, the embedded computing and Internet of Things community have not yet widely adopted energy-harvesting-based solutions. This is partly due to a mismatch between power density in energy harvesters and electronic devices which, until recently, required a battery or super-capacitor to be functional. This mismatch is especially accentuated in indoor environments, where there is comparably less primary energy available than in outdoor environments. In this talk, I will present a design methodology that can optimize energy flow in dynamic environments without requiring batteries or super-capacitors. Furthermore, I will discuss the general applicability of this approach by presenting several batteryless sensing applications for both static and wearable deployments.
Short bio - Andres Gomez received a dual degree in electronics engineering and computer engineering from the Universidad de Los Andes, Colombia, an M.Sc. degree from the ALaRI Institute (Università della Svizzera Italiana), Switzerland, and a Ph.D. from ETH Zurich, Switzerland. He has over ten years of experience with embedded systems and has worked in multiple research laboratories in Colombia, Italy, and Switzerland. More recently, he has worked as an R&D engineer at Miromico AG. He has co-authored more than 20 scientific articles and has contributed to multiple open-source projects. He is currently a Postdoctoral Fellow at the University of St. Gallen, Switzerland. His current research interests include batteryless system design, the Internet of Things and the Web of Things.
Watch the talk via the following link: https://youtu.be/ntp_l6Nem1s
more...

Text indexing for large amounts of data
Abstract - Large amounts of text are produced in bioinformatics, web crawling, and text mining, to name just a few examples. These texts need to be indexed to make them algorithmically efficient to handle. Classical text indexes are typically designed for sequential processors and main memory, and thus quickly reach their limits in real-world problems. In this talk, I will show some recent results on index construction for data sizes where the available main memory is insufficient and, moreover, the parallelism of modern systems is to be exploited. Concrete models here are multi-core CPUs and the PRAM model, distributed systems with message passing, and the external memory model. Applications in text compression are also discussed.
Short-Bio - Johannes Fischer has been Professor of Algorithm Engineering for Computer Science at TU Dortmund University since October 2013. After receiving his computer science degree from the University of Freiburg in 2003, he worked as a doctoral student at LMU Munich, where he received his PhD in 2007 for a dissertation in algorithmic bioinformatics. He then worked as a postdoctoral researcher at the University of Chile, the University of Tübingen, and KIT. His current research is at the intersection of theory/algorithm engineering and is mainly concerned with space-efficient data structures, text indexing and compression, and parallel algorithms on large data sets.
more...
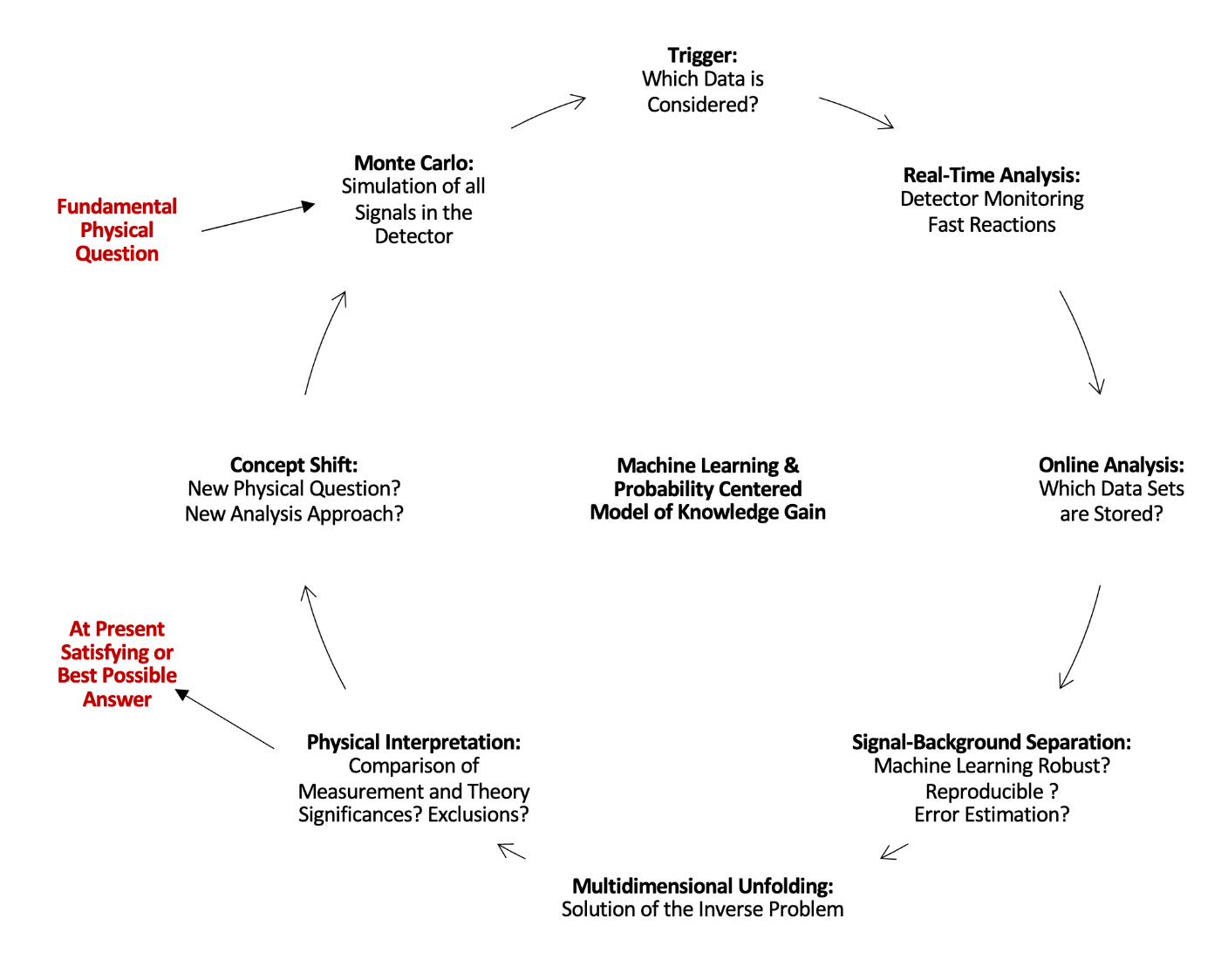
How does one arrive at scientifically proven knowledge? This question has accompanied research from the very beginning. Depending on the scientific context, claims to the degree of truth, and on scientific methodology, different answers to this question have been given throughout the ages. More recently, a new scientific methodology has emerged that can best be characterized as "probabilistic rationalism." In collaboration between computer science and physics, methods have been developed in recent decades and years that allow large amounts of data collected in modern experiments to be analyzed in terms of their probabilistic properties. Artificial intelligence or machine learning are the methods of the moment.
This is the subject of a new Techreport entitled "On Probabilistic Rationalism" by Prof. Dr. Dr. Wolfgang Rhode. It does not deal with individual aspects of statistical analysis, but rather with the entire evolutionary process of knowledge expansion. Interdisciplinary aspects of epistemology from the perspectives of physics, computer science and philosophy are brought together to form an up-to-date and consistent model of knowledge acquisition. This model can be used to overcome some well-known problems of existing epistemological approaches. In particular, interesting parallels have been identified between the functioning of machine learning and biological-neural learning processes.
The report can be found here.

Bayesian Deep Learning
Abstract - Drawing meaningful conclusions on the way complex real life phenomena work and being able to predict the behavior of systems of interest requires developing accurate and highly interpretable mathematical models whose parameters need to be estimated from observations. In modern applications of data modeling, however, we are often challenged with the lack of such models, and even when these are available they are too computational demanding to be suitable for standard parameter optimization/inference.
Deep learning techniques have become extremely popular to tackle such challenges in an effective way, but they do not offer satisfactory performance in applications where quantification of uncertainty is of primary interest. Bayesian Deep Learning techniques have been proposed to combine the representational power of deep learning techniques with the ability to accurately quantify uncertainty thanks to their probabilistic treatment. While attractive from a theoretical standpoint, the application of Bayesian Deep Learning techniques poses huge computational and statistical challenges that arguably hinder their wide adoption. In this talk, I will present new trends in Bayesian Deep Learning, with particular emphasis on practical and scalable inference techniques and applications.
Short bio - Maurizio Filippone received a Master's degree in Physics and a Ph.D. in Computer Science from the University of Genova, Italy, in 2004 and 2008, respectively.
In 2007, he was a Research Scholar with George Mason University, Fairfax, VA. From 2008 to 2011, he was a Research Associate with the University of Sheffield, U.K. (2008-2009), with the University of Glasgow, U.K. (2010), and with University College London, U.K (2011). From 2011 to 2015 he was a Lecturer at the University of Glasgow, U.K, and he is currently AXA Chair of Computational Statistics and Associate Professor at EURECOM, Sophia Antipolis, France.
His current research interests include the development of tractable and scalable Bayesian inference techniques for Gaussian processes and Deep/Conv Nets with applications in life and environmental sciences.

Significant Feature Selection with Random Forest
Abstract:
The Random Forest method as a tree-based regression and classification algorithm is able to produce feature selection methods along with point predictions during tree construction. Regarding theoretical results, it has been proven that the Random Forest method is consistent, but several other results are still lacking due to the complex mathematical forces involved in this algorithm. Focusing on the Random Forest as a feature selection method, we will deliver theoretical guarantees for the unbiasedness and consistency of the permutation importance measure used during regression tree construction. The result is important to conduct later statistical inference in terms of obtaining (asymptotically) valid statistical testing procedures. Regarding the latter, a brief overview of obtained results will be given and various approaches for future research in this field will be presented. Our results will be supported by extensive simulation experiments.
Short bio:
Burim Ramosaj is Post-Doctoral Researcher at the Faculty of Statistics at TU Dortmund University, where he graduated as Dr. rer. nat. In July 2020 with the Dissertation "Analyzing Consistency and Statistical Inference in Random Forest Models“. From April 2019 he worked there as a Research Assistant and Doctoral Student at TU Dortmund and before that at the Institute of Statistics, University of Ulm. He received a M.Sc. of Mathematics at Syracuse University, NY, USA and a M.Sc. of Mathematics and Management at the University of Ulm. His current research interests are: Asymptotic and Non-Parametric Statistics, Non-Parametric Classification and Regression, Statistical Inference with Machine Learning Methods, Missing Value Imputation.
more...

In-Memory Computing for AI
SFB876 Gast
Abstract:
In-memory computing provides a promising solution to improve the energy efficiency of AI algorithms. ReRAM-based crossbar architecture has gained a lot of attention recently. A few studies have shown the successful tape out of CIM ReRAM macros. In this talk, I will introduce ReRAM-based DNN accelerator designs, with emphasis on the system-level simulation method and techniques to exploit sparsity.
Short bio:
Chia-Lin Yang is a Professor in the Department of Computer Science and Information Engineering at NTU. Her research is in the area of computer architecture and system with focuses on storage/NVM architecture and AI-enabled edge computing. She was the General Co-chair for ISLPED 2017/Micro 2016, and the Program Co-Chair for ISLPED 2016. Dr. Yang is currently serving as an Associate Editor for IEEE Transaction on Computer-Aided Design, IEEE Computer Architecture Letter and in the editorial board for IEEE Design & Test. She has also served on the technical program committees of several IEEE/ACM conferences, such as ISCA, ASPLOS, HPCA, ISLPED, IPDPS, ICCD, DAC, ICCAD, ISSS+CODES, CASES, Date, ASP-DAC. She received the best paper award of ISLPED 2009, the 2005 and 2010 IBM Faculty Award,2014 NTU EECS Academic Contribution Award, and 2019 Distinguished Electrical Engineering Professor, Chinese Inst. of Electrical Engineering.
more...

Massive investments in digitalization and a fourfold increase in the budget for innovation are intended to strengthen North Rhine-Westphalia as a center of business and knowledge and drive forward the state's renewal. This was emphasized by Innovation Minister Prof. Dr. Andreas Pinkwart before the tenth presentation of the Innovation Award of the State of North Rhine-Westphalia in Düsseldorf in the evening. Since 2008, scientists and scholars have been honored for outstanding research work. Pinkwart presented this year's honorary award winner Prof. Dr. Dr. h. c. Michael ten Hompel to journalists. Economics and Innovation Minister Prof. Dr. Andreas Pinkwart: "North Rhine-Westphalia is a power house for innovations. Excellent universities, innovative medium-sized and large companies and a lively, creative start-up scene drive the renewal of the economy and society. Since 2017, we have quadrupled our funding for innovation and will be investing more than ten billion euros in digitization from public funds alone by 2025 to accelerate modernization. On top of this comes private investment, for example in expanding broadband mobile communications and gigabit networks.
The previous award winners are ambassadors for our innovative competencies in North Rhine-Westphalia. The whole of society benefits from their diverse innovations, e.g. in the fields of biofuels, cyber security, cancer therapy, artificial intelligence, compostable plastics or resource-saving oil filters. This year's honorary award winner is an outstanding personality who continues this tradition: Prof. Michael ten Hompel is a unique innovator of modern logistics and a pioneer of Industry 4.0. The European Blockchain Institute in Dortmund, which he initiated and which is supported by the state, is a key to the innovative further development of the sector and strengthens the logistics location North Rhine-Westphalia and Germany. We can be a little proud that Prof. ten Hompel is contributing to the renewal of the economy and society and to the creation of jobs with his energy, creative power and creativity from Dortmund".
Prof. ten Hompel holds the chair for materials handling and warehousing at the Technical University of Dortmund and is managing director of the Fraunhofer Institute for Material Flow and Logistics (IML). He shaped the automated shuttle technology in logistics. Thanks to his research and commitment, Europe's most important logistics cluster, the EffizienzCluster LogistikRuhr, has been put into practice. Together with his team from the Fraunhofer Institute IML, Prof. ten Hompel pushed ahead with the establishment of a European Blockchain Institute, which the state government is now funding with 7.7 million euros. The block chain technology stores data decentrally, securely and transparently. This enables companies to share data securely among themselves at eye level. Practical research into the technology has great potential across all industries.
Top-level research "Made in NRW
The innovation state of North Rhine-Westphalia can build on many strengths: This is shown by the new innovation report presented on 15.10.2020. The state leads Germany in the number of patent applications in the fields of biotechnology, pharmaceutical technologies, polymer technology, organic fine chemistry, materials technology/metallurgy, metal chemistry and construction technologies. Numerous research institutions are working on future fields such as the bio-economy, ICT and electromobility. The positive developments in university spin-offs, the nationwide digital infrastructure and innovative small and medium-sized enterprises are further strengths that we can exploit and expand.
With the North Rhine-Westphalia Innovation Award, the state government honors scientists and researchers who provide answers to the major challenges of our time with outstanding research. Since 2008, with few exceptions, a renowned jury of experts has selected award winners in the categories "Honorary Award", "Young Scientists" and "Innovation" from hundreds of applications every year.
Press contact: Matthias.Kietzmann@mwide.nrw.de, Image: © MWIDE NRW/Susanne Kurz.
more...

Semi-Structured Deep Distributional Regression
SFB876 & DoDSc guest
Abstract:
Semi-Structured Deep Distributional Regression (SDDR) is a unified network architecture for deep distributional regression in which entire distributions can be learned in a general framework of interpretable regression models and deep neural networks. The approach combines advanced statistical models and deep neural networks within a unifying network, contrasting previous approaches that embed the neural network part as a predictor in an additive regression model. To avoid identifiability issues between different model parts, an orthogonalization cell projects the deep neural network part into the orthogonal complement of the statistical model predictor, facilitating both estimation and interpretability in high-dimensional settings. The framework is implemented in an R software package based on TensorFlow and provides a formula user interface to specify the models based on the linear predictors. In the second part of the talk, models in which tasks are represented as direct acyclic graphs (DAGs) are considered, and methods for guaranteeing both timing constraints and memory feasibility are presented. In particular, solutions for bounding the worst-case memory space requirement for parallel tasks running on multi-core platforms with scratchpad memories are discussed.
Short bio:
Dr. David Rügamer is a lecturer and postdoctoral research fellow at the chair of Statistical Learning and Data Science (Prof. Bischl), Department of Statistics, LMU Munich, where he also leads two research subgroups on machine learning and deep learning. Before joining the chair, he has worked as Senior Data Science in the industry with focus on data engineering and deep learning research. From 2014 to 2018 he did his PhD under the supervision of Prof. Dr. Sonja Greven and was partly funded by the Emmy Noether project ‘Statistical Methods for Longitudinal Functional Data’.

At this year's ECML-PKDD, the publication "Resource-Constrained On-Device Learning By Dynamic Averaging" received a Best Paper Award at the "Workshop on Parallel, Distributed and Federated Learning". The cooperation between the TU Dortmund University, ML2R, CRC 876, the University of Bonn, Fraunhofer IAIS, and Monash University was initiated by Katharina Morik's research stay in Melbourne.
The paper demonstrated that distributed learning of probabilistic graphical models can be realized completely with integer arithmetic. This results in reduced bandwidth requirements and energy consumption, thus enabling the use of distributed models on resource-constrained hardware. Furthermore, the possible error of the approximation was theoretically analyzed and bounded.
more...
The third Industrial Data Science Conference (IDS 2020), taking place on 21th & 22th October 2020, brings together experts from various industries with data science application examples and best practices in order to promote the exchange of experience and discussions among colleagues and experts.
Digitisation, the Internet of Things (IoT) and industry 4.0 technologies are changing entire industries, enabling the capture of vast amounts of data of all kinds, including big data and streaming data, structured and unstructured data, text, images, audio and sensor data.
Data Science, Data Mining, Process Mining, machine learning and Predective Analytics offer the opportunity to generate enormous competitive advantages from data. Hence IDS 2020 will focus on these aspects.
The key topics of the event are:
Further information and registration can be found at the following address: IDS 2020
If you have any questions, don’t hesitate to contact us at ids2020@industrial-data-science.de
more...
(1).jpg?self=$g642qmm39c&part=data)
The faculty of statistics is happy to announce that Jakob Richter has successfully defended his dissertation on September 16, 2020. The dissertation titled "Extending Model-Based Optimization with Resource-Aware Parallelization and for Dynamic Optimization Problems" has proposed and investigated innovative concepts for extending Model-Based Optimization (MBO) with synchronous parallelization strategies that reduce idle time and extending MBO to be able to optimize problems that change systematically over time.
Parts of the dissertation were successfully published at the GECCO 2020 and LION 2017 conference.
The members of the doctoral committee were Prof. Dr. Jörg Rahnenführer (supervisor and first assessor), Prof. Dr. Andreas Groll (second assessor), Prof. Dr. Markus Pauly (chairman of the examination committee), and Prof. JProf. Dr. Kirsten Schorning (representative of the faculty). Jakob Richter was a research assistant at the faculty of statistics and a member of the Collaborative Research Center 876 (Project A3).
A conference paper developed within the DFG Collaborative Research Center 876 ("Data Analysis under Resource Constraints") by communication experts (Benjamin Sliwa, Christian Wietfeld from the Chair of Communication Networks of the Faculty ETIT) with experts in machine learning (Nico Piatkowski, former SFB 876 now ML2R) was awarded a Best Paper Award at the IEEE Flagship Conference "International Communications Conference (ICC)".

At the ICC 2020, which was originally planned for this year in Dublin, over 2100 papers were presented in a virtualized format. The SFB 876 paper awarded at the conference, entitled "LIMITS: Lightweight Machine Learning for IoT Systems with Resource Limitations", presents the novel open source framework LIghtweight Machine Learning for IoT Systems (LIMITS), which uses a platform-in-the-loop approach that explicitly takes into account the concrete software generation tools (the so-called compilation toolchain) of the Internet-of-Things (IoT) target platform.
LIMITS focuses on comprehensive tasks such as the automation of experiments and data acquisition, platform-specific code generation and the so-called sweet spot determination for optimal parameter combinations. In two case studies focusing on cellular data rate prediction and radio-based vehicle classification, LIMITS will be validated by comparing different learning models and real IoT platforms with memory constraints from 16 kB to 4 MB. Furthermore, its potential as a catalyst for the development of IoT systems with machine learning will be demonstrated.
more...

Machine learning has become one of the driving fields in data analysis. But how to deal with data analysis and limited resources: Computational power, data distribution, energy or memory? The summer school on Resource-aware Machine Learning provides lectures on the latest research in machine learning, typically with the twist on resource consumption and how these can be reduced. This year’s summer school will be held online and free of charge between 31st of August and 4th of September. The events will be a mixture of pre-recorded and live sessions, including a dedicated space for presenting PhD/PostDoc research and a hackathon featuring real world ML tasks.
A selection of course topics: Deep Learning, Graph Neural Networks, Large Models on Small Devices, Power Consumption of ML, Deep generative modeling, Memory challenges in DNN...
More info and registration: https://www-ai.cs.tu-dortmund.de/summer-school-2020/
During registration you may express your interest in joining the hackathon and/or presenting at the students’ corner.
Hackathon - Positioning prediction and robot control
As a practical example to leverage your ML skills we host a challenge on indoor location prediction based on floor-integrated sensor data. Real world data is gathered in a warehouse scenario, where free roaming robots perform transportation of goods. Your first task will be to use sensor data (vibration, magnetic fields…) with position ground truth to build a position prediction. The best teams will get the chance for live control of the robots on the final day of the summer school. The winner will be invited for research cooperations to Dortmund.
More details: https://www-ai.cs.tu-dortmund.de/summer-school-2020/hackathon
Students’ Corner - Share and discuss your work
The summer school will be accompanied by an exchange platform for participants, the Students' Corner, which will allow them to network and share their research. During the registration you may express your interest in participation at the student’s corner and we will keep you updated.
More details: https://www-ai.cs.tu-dortmund.de/summer-school-2020/students-corner
The summer school is organised by the competence center for Machine Learning Rhine-Ruhr, ML2R, the collaborative research center SFB 876 and the artificial intelligence group at TU Dortmund University.
more...
We are happy to announce that the newest article of project B3 "Real-time prediction of process forces in milling operations using synchronized data fusion of simulation and sensor data" is now available at ScienceDirect (follow: this link) for free access until August, 9th.
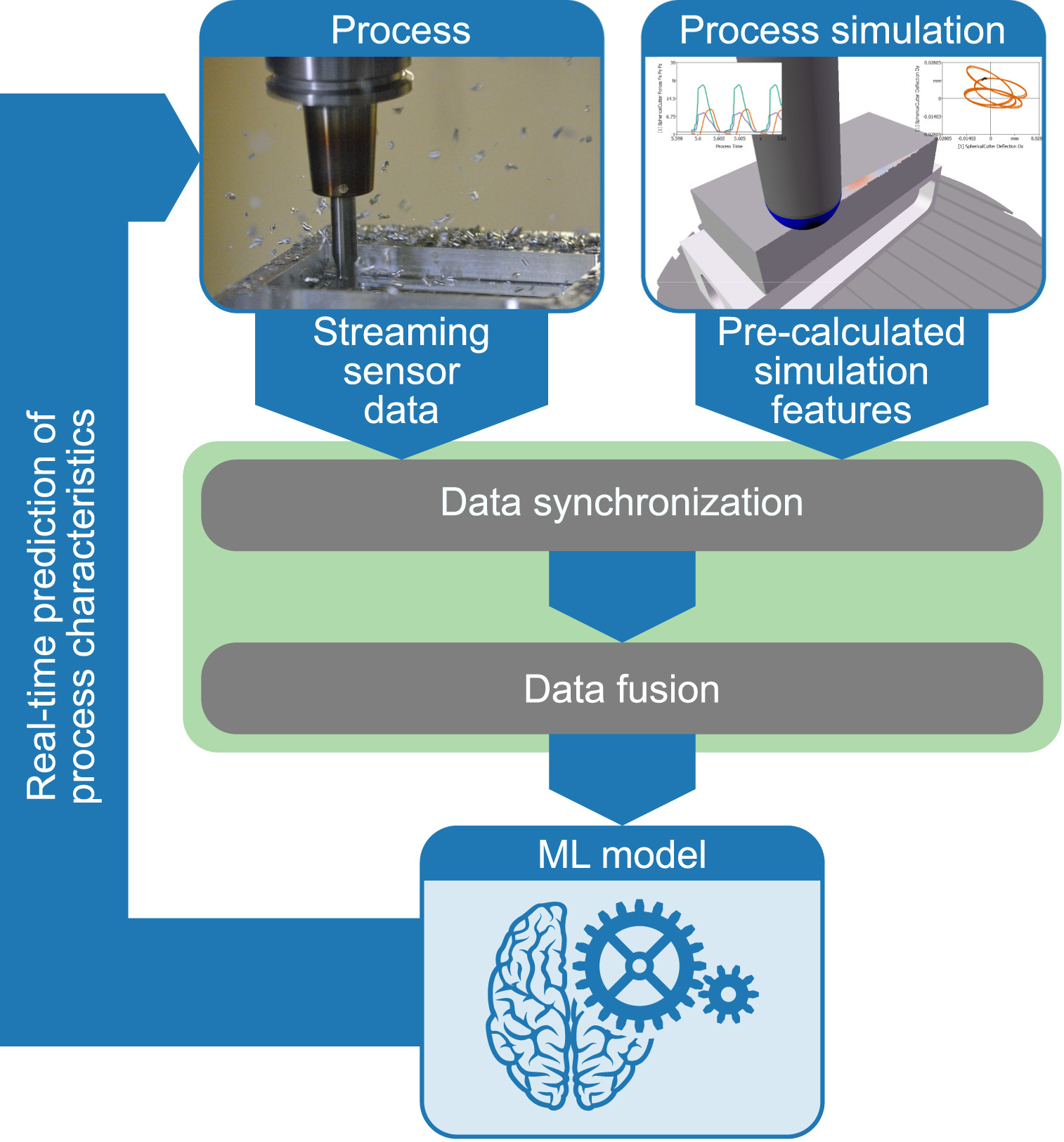
The paper focuses on Machine Learning based predictions in milling processes. In mechanical engineering, milling is one of the most important machining operations with a wide variety of application use cases, e.g., the machining of structural components for the aerospace industry, dental prostheses or forming tools in the context of the tool and die manufacturing. Different challenges arise for different process strategies, milling tools and machine tools, such as tool vibrations of long and slender finishing tools causing chatter marks on the workpiece surface and tool wear for long-running processes.
Nowadays, in the context of Industry 4.0, Machine Learning methods have allowed production processes, including machining, to be better understood and intelligently transformed. Data gathered and evaluated during these processes is the fundamental basis of such transformation. The industrial processes can thus not only be better understood, but also optimized.
In this context, to prevent undesirable effects during milling processes, the paper proposes a novel approach for combining simulation data with sensor data to generate online predictions of process forces, which are influenced by tool wear, using an ensemble-based machine learning method. In addition, a methodology was developed in order to synchronize pre-calculated simulation data and streaming sensor measurements in real time. Sensor data was acquired using milling machines by the Virtual Machining group of the Chair for Software Engineering in the laboratories of the Institute of Machining Technology (ISF), TU Dortmund. The geometric physically-based simulation system has also been developed in the same chair.
more...
Whereas viruses are too small to be revealed visually, their interaction with antibodies can be made visible. The Leibniz Institute for Analytical Sciences (ISAS) and the Collaborative Research Centre (SFB) 876 of the Technical University (TU) Dortmund intend to apply a measurement method to the novel corona virus Sars-Cov-2.
 The cooperation between ISAS and TU Dortmund University, which has been in place since 2010, could result in an effective method for the containment of the novel coronavirus (COVID-19). With the virus sensor, Dortmund physicists, computer scientists and mathematicians have developed an instrument that enables analysis procedures to be carried out in real time and on site. The sensor can also be used outside of special laboratories to determine the infection status of large groups of people, such as airport passengers or residents of entire housing estates. This measuring method can prevent the introduction, further spread and recurrence of viruses.
The cooperation between ISAS and TU Dortmund University, which has been in place since 2010, could result in an effective method for the containment of the novel coronavirus (COVID-19). With the virus sensor, Dortmund physicists, computer scientists and mathematicians have developed an instrument that enables analysis procedures to be carried out in real time and on site. The sensor can also be used outside of special laboratories to determine the infection status of large groups of people, such as airport passengers or residents of entire housing estates. This measuring method can prevent the introduction, further spread and recurrence of viruses.
It is conceivable that the biosensor could now also be used to combat the novel coronavirus. To this end, scientists at ISAS and TU Dortmund University are currently working with anti-SARS-CoV-2 antibodies to prepare the Sensor for the corona viruses.
Indeed, our sensor works by exploiting a physical effect that bridges the gap between the micrometer and nanometer range: viruses - including corona viruses - are objects on the nanometer range and thus too small to be detected with optical microscopes, which are only accessible to the micrometer range. Microscopes lack the necessary magnifying power for the direct detection of viruses. The sensor, on the other hand, detects viruses indirectly by measuring changes in the so-called surface plasmon resonance that the viruses cause on the sensor. In principle, this is based on the detection of label-free biomolecular binding reactions on a gold surface, in a series of images taken with a CCD camera. Even though a virus is only nanometer in size, the resonance as an effect extends over the micrometer range. These characteristic changes are determined by image and signal analysis methods based on special neural networks and allow the identification of different viral pathogens with high detection rates in real time.
"By this, viruses become optically detectable, which allows a low-cost, mobile sensor and very fast tests," summarizes Dr. Roland Hergenröder, who heads the project group on the ISAS side. He hopes that with the availability of anti-SARS-CoV-2 antibodies, the Sensor will soon be able to be used for the detection of the novel coronavirus.
Sensor and analysis methods were developed in a cooperation of physicists, computer scientists and mathematicians of ISAS and the Chairs of Computer Graphics and Embedded Systems of TU Dortmund within the framework of the Collaborative Research Center 876, subproject B2 with the name "Resource optimizing real time analysis of artifactious image sequences for the detection of nano objects". Prof. Dr. Katharina Morik, speaker of the Collaborative Research Centre 876 summarizes: "We are proud of the biosensor; if it can now be used against corona, that's wonderful," Morik summarizes.
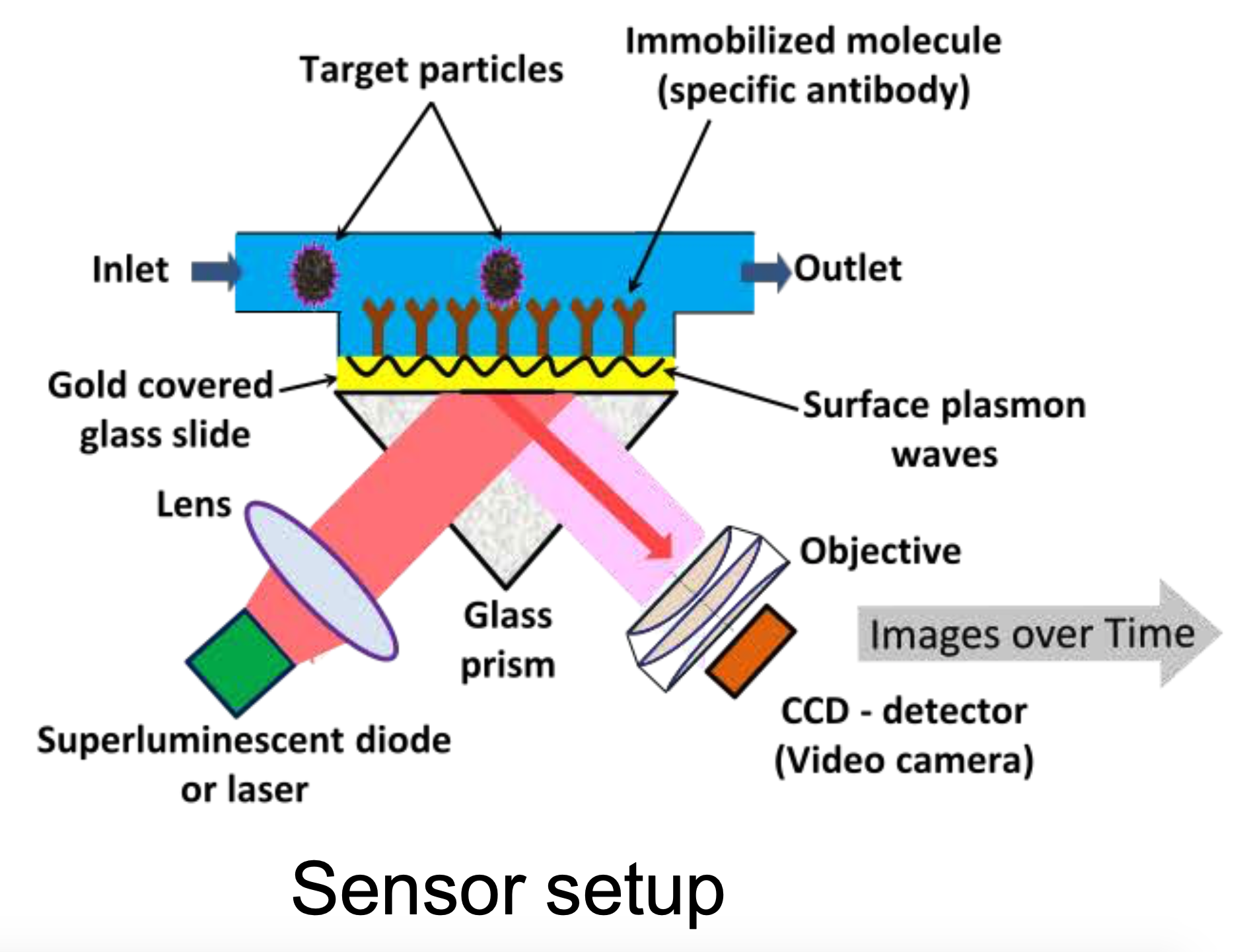 The comprehensive real-time detection of the Coronavirus SARS-CoV-2 is a fundamental challenge. A biosensor called "Plasmon Assisted Microscopy of Nano-sized Objects" could make a valuable contribution here. The sensor represents a viable technology for mobile real-time detection and quantitative analysis of viruses and virus-like particles. A mobile system that can detect viruses in real time is urgently needed, due to the combination of virus emergence and evolution with increasing global travel and transport. It could be used for fast and reliable diagnoses in hospitals, airports, the open air, or other settings. The development of the sensor is part of the collaborative research center 876 funded by DFG (sfb876.tu-dortmund.de) and has been launched since 2010.
The comprehensive real-time detection of the Coronavirus SARS-CoV-2 is a fundamental challenge. A biosensor called "Plasmon Assisted Microscopy of Nano-sized Objects" could make a valuable contribution here. The sensor represents a viable technology for mobile real-time detection and quantitative analysis of viruses and virus-like particles. A mobile system that can detect viruses in real time is urgently needed, due to the combination of virus emergence and evolution with increasing global travel and transport. It could be used for fast and reliable diagnoses in hospitals, airports, the open air, or other settings. The development of the sensor is part of the collaborative research center 876 funded by DFG (sfb876.tu-dortmund.de) and has been launched since 2010.
The biosensor permits the imaging of biological nano-vesicles (e.g. the Coronavirus) utilizing a Kretschmann’s scheme of plasmon excitation with an illumination of a gold sensor surface via a glass prism. The sensor applies anti-bodies to bind the nano-sized viruses on a gold layer. The presence of viruses can be detected by the intensity change of the reflection of a laser beam. For more technical details, we refer the reader to our survey paper by Shpacovitch, et al. (DOI: 10.3390/s17020244). Characteristics of these binding events are spatiotemporal blob-like structures with very low signal-to-noise ratio, which indicate particle bindings and can be automatically analyzed with image processing methods. We capture the intensity of the reflected laser beams using a CCD camera, which result in a series of artifactious images. For analysis of the images provided by the sensor, we have developed nanoparticle classification approaches based on deep neural network architectures. It is shown that the combination of the sensor and the application of deep learning enables a real-time data processing to automatically detect and quantify biological particles. With the availability of anti-SARS-CoV-2 antibodies, the sensor could thus also be used to detect the Coronavirus.

In the latest issue of the Handelsblatt Journal "Artificial Intelligence" Prof. Dr. Katharina Morik addresses the question: How do we achieve AI excellence in Germany?
As part of her guest article, she calls for the enhancement of German AI research through additional professorships. According to Morik, this is the only way to continuously strengthen strong and internationally visible research centers.
In her contribution she highlights the Collaborative Research Centres (SFB) of the German Research Foundation (DFG) as a unique environment for internationally leading research. Within this context, SFB 876 is the only Collaborative Research Centre that focuses genuinely on machine learning.
Click here for Professor Morik's guest article in the Handelsblatt Journal "Artificial Intelligence".

Causality in Data Science
Joined Topical Seminar of SFB 823 and SFB 876
Abstract - Causality enters data science in different ways. Often, we are interested in knowing how a system reacts under a specific intervention, e.g., when considering gene knock-outs or a change of policy.
The goal of causal discovery is to learn causal relationships from data. Other practical problems in data science focus on prediction. But as soon as we want to predict in a scenario that differs from the one which generated the available data (we may think about a different country or experiment), it might still be beneficial to apply causality related ideas. We present assumptions, under which causal structure becomes identifiable from data and methods that are robust under distributional shifts. No knowledge of causality is required.
Short bio - Jonas is a professor of statistics at the Department of Mathematical Sciences at the University of Copenhagen. Previously, he has associate professor at the same department, a group leader at the Max-Planck-Institute for Intelligent Systems in Tuebingen and a Marie Curie fellow (postdoc) at the Seminar for Statistics, ETH Zurich. He studied mathematics at the University of Heidelberg and the University of Cambridge and did his PhD both at the MPI Tuebingen and ETH Zurich. He tries to infer causal relationships from different types of data and is interested in building statistical methods that are robust with respect to distributional shifts. In his research, Jonas seeks to combine theory, methodology, and applications. His work relates to areas such as computational statistics, causal inference, graphical models, independence testing or high-dimensional statistics.
more...

Due to the Corona-Virus pandemic, this talk is canceled and will be postponed to later this year.
Towards a Principled Bayesian Workflow
Abstract:
Probabilistic programming languages such as Stan, which can be used to specify
and fit Bayesian models, have revolutionized the practical application of
Bayesian statistics. They are an integral part of Bayesian data analysis and
provide the basis for obtaining reliable and valid inference. However, they are
not sufficient by themselves. Instead, they have to be combined with substantive
statistical and subject matter knowledge, expertise in programming and data
analysis, as well as critical thinking about the decisions made in the process.
A principled Bayesian workflow for data analysis consists of several steps from
the design of the study, gathering of the data, model building, estimation, and
validation, to the final conclusions about the effects under study. I want to
present a concept for an interactive Bayesian workflow which helps users by
diagnosing problems and giving recommendations for sensible next steps. This
concept gives rise to a lot of interesting research questions we want to
investigate in the upcoming years.
Short bio:
Dr. Paul Bürkner is a statistician currently working as a postdoc at Aalto University (Finland), Department of Computer Science. Previously, he has studied Psychology and Mathematics at the Universities of Münster and Hagen and did his PhD about optimal design and Bayesian data analysis at the University of Münster. As a member of the Stan development team and author of the R package brms, a lot of Paul’s work is dedicated to the development and application of Bayesian methods. Specifically, he works on a Bayesian workflow for data analysis that guides researchers and practitioners from the design of their studies to the final decision-making process using state-of-the-art Bayesian statistical methods.
more...

Quantum Machine Learning at LMU's QAR-Lab
Abstract:
Quantum Computing, which is based on principles of quantum mechanics and so-called qubits as information units, has become increasingly relevant since the publication of algorithms by Shor and Grover in the 1990s. However, the scientific community has long been concerned with the possibility of a quantum computer, since famous physicist Richard Feynman postulated in his 1982 paper "Simulating Physics with Computers" that in order to simulate a quantum system a quantum computer is required. There are several approaches for such quantum computer architectures, such as Quantum Gate Computing and Adiabatic Quantum Computing. In the meantime, company D-Wave Systems is the first company to have built quantum annealing hardware based on Adiabatic Quantum Computing.
The talk is divided into two parts. First, an understanding of quantum mechanical fundamentals of quantum computing is developed, quantum gate model and adiabatic quantum computing are explained, and finally formalizations and solution methods for (combinatorial) optimization problems are shown. Second, activities of LMU Munich's "Quantum Applications and Research Laboratory" (QAR Lab) are presented. A particular focus is on topics of quantum machine learning.
Short bio:
Dr. Sebastian Feld is head of Quantum Applications and Research Laboratory (QAR Lab) at LMU Munich's Mobile and Distributed Systems Group. Currently, he pursues the goal of habilitation with a main focus being on optimization problems and the application of quantum technology. He joined LMU in 2013 and earned his doctorate in 2018 working on planning of alternative routes, time series analysis and geospatial trajectories. Previously, he has been working as a research associate at the Institute for Internet Security dealing with topics like Internet measurement, identity management and penetration testing. Since his time in Bavaria, Sebastian Feld has coordinated several research projects, including project "Mobile Internet of the Future" funded by Bavarian Ministry of Economic Affairs and project "Innovation Center Mobile Internet" which is part of Center for Digitalisation Bavaria (Z.DB). Currently he coordinates project "Platform and Ecosystem for Quantum-Supported Artificial Intelligence" funded by Federal Ministry of Economics and Energy.
New models and analyses for contemporary real-time workloads
Abstract:
Nowadays, real-time workloads are becoming always more computationally demanding, giving rise to the need to adopt more powerful computing platforms. This is the case of multi-core systems: nevertheless, their adoption increases the analysis complexity due to multiple sources of unpredictability. To exploit the available computational power, tasks running upon multi-core platforms are often characterized by a parallel structure and non-trivial dependencies. The analysis complexity is further exacerbated by the scheduling effects imposed by the operating systems and, sometimes, by middleware frameworks that handle the actual workload on behalf of the operating system. As a consequence, analyzing a modern real-time system is always becoming more complex, hence requiring new models and analysis techniques. This talk addresses these issues from different perspectives.
In the first part of the talk, an overview of how to model and analyze complex contemporary workloads is given. First, dynamic workloads are addressed, where tasks can join and leave while the system is operating. Then, how specific frameworks can affect the timing of applications is discussed, targeting the Robotics Operating System (ROS) and Tensorflow.
In the second part of the talk, models in which tasks are represented as direct acyclic graphs (DAGs) are considered, and methods for guaranteeing both timing constraints and memory feasibility are presented. In particular, solutions for bounding the worst-case memory space requirement for parallel tasks running on multi-core platforms with scratchpad memories are discussed.
Short bio:
Daniel Casini is a Ph.D. Candidate at the Real-Time Systems (ReTiS) Laboratory of the Scuola Superiore Sant'Anna of Pisa, working under the supervision of Prof. Alessandro Biondi and Prof. Giorgio Buttazzo.
He graduated (cum laude) in Embedded Computing Systems Engineering, a Master's degree jointly offered by the Scuola Superiore Sant'Anna of Pisa and University of Pisa.
His research interests include software predictability in multi-processor systems, schedulability analysis, synchronization protocols, and the design and implementation of real-time operating systems and hypervisors.

How to Efficiently and Predictably use Resources in Safety-critical Systems
Reliable Data Mining in Uncertain Data
Abstract - Our ability to extract knowledge from data is often impaired by unreliable, erroneous, obsolete, imprecise, sparse, and noisy data. Existing solutions for data mining often assume that all data are uniformly reliable and representative. Oblivious to sample size and sample variance, it is clear that mined patterns may be spurious, that is, caused by random variations rather than a causal signal. This is particularly problematic if latent features and deep learning methods are used to mine patterns, as their lack of interpretability prevents domain experts and decision makers from explaining spurious conclusions. This presentation will survey data mining algorithms that can exploit reliability information of data to enrich mined patterns with significance information. In detail, we will discuss the use of Monte Carlo and agent-based simulation to gain insights on the reliability of data mining results and we will look at applications for handling.
CV - Andreas is a tenure-track assistant professor at the Department of Geography and Geoinformation Science at George Mason University (GMU), USA. He received his Ph.D. in Computer Science, summa cum laude, under supervision of Dr. Hans-Peter Kriegel at LMU Munich in 2013. Since joining GMU in 2016, Andreas' research has received more than $2,000,000 in research grants by the National Science Foundation (NSF) and the Defense Advanced Research Projects Agency (DARPA). Andreas' research focuses on big spatial data, spatial data mining, social network mining, and uncertain database management. His research quest is to work interdisciplinary and bridge the gap between data-science and geo-science. Since 2011, Andreas has published more than 90 papers in refereed conferences and journals leading to an h-index of 18. For the work presented in this talk, Andreas has received the SSTD 2019 best vision paper award (runner-up), the SSTD 2019 best paper award (runner-up), and the ACM SIGSPATIAL 2019 GIS Cup 1st Place award.

Prof. Jian-Jia Chen (Principle Investigator of sub-projects A1 and A3 in SFB876) receives the ERC (European Research Council) Consolidator Award 2019 for his project "PropRT - Property-Based Modulable Timing Analysis and Optimization for Complex Cyber-Physical Real-Time Systems.” The grant is about 2 Million Euros for a period of 5 years. Prof. Chen expressed that, “It is my honor to be granted with the ERC Consolidator Award.”
PropRT will explore the possibilities to construct timing analysis for complex cyber-physical real-time systems from formal properties. The target properties should be modular so that safe and tight analysis as well as optimization can be performed (semi-)automatically. New, mathematical, modulable, and fundamental properties for property-based (schedulability) timing analyses and scheduling optimizations are needed to capture the pivotal properties of cyber-physical real-time systems, and thus enable mathematical and algorithmic research on the topic. Different flexibility and tradeoff options to achieve real-time guarantees should be provided in a modularized manner to enable tradeoffs between execution efficiency and timing predictability.
Part of the preliminary results of the project were supported in the scope of SFB876.

Dr. Kuan-Hsun Chen completed his doctorate on “Optimization and Analysis for Dependable Application Software on Unreliable Hardware Platforms” with a distinction (summa cum laude). He also received one of the dissertation prices at the TU Dortmund’s academic anniversary celebrations on 16 December 2019.
In the doctoral dissertation, Kuan-Hsun Chen dealt with Real-Time Systems under threats of soft-errors. He has considered how soft-errors can be handled and analyzed in such a way that both timeliness and functional correctness can be guaranteed at the same time. Such problems usually can be found in safety critical systems, e.g., computing systems in automotive systems, nuclear plants, and avionic systems. In addition, he also served in Collaborative Research Center SFB 876 and optimized a few Machine Learning models under various resource constraints. After his doctorate, he continues to work as a postdoctoral researcher in "Design Automation for Embedded Systems Group" at TU Dortmund and collaborates with several members in Collaborative Research Center SFB 876 for Machine Learning on Cyber-Physical Systems.

Georg von der Brüggen has successfully defended his dissertation "Realistic Scheduling Models and Analyses for Advanced Real-Time Embedded Systems" on November 14th. His dissertation focuses on the importance of realistic models and analyses when guaranteeing timeliness in advanced real-time embedded systems without over-provisioning system resources.
The members of the doctoral committee were Prof. Dr. Jian-Jia Chen (supervisor and first assessor), Dr. Robert I. Davis (Reader at the University of York and second assessor), Prof. Dr. Heinrich Müller (chairman of the examination committee), and Prof. Dr. Jens Teubner (representative of the faculty). Georg von der Brüggen was a research assistant at LS 12 and a member of the Collaborative Research Center 876 (Project A1).

How to Efficiently and Predictably use Resources in Safety-critical Systems
Abstract - In order to reduce the development time and cost of safety-critical systems the designers are turning towards commercial-of-the-shelf multicore platforms. The goal is achieved by enabling efficient sharing of platform resources, such as CPU cycles, memory bandwidth, and cache lines, among tasks that may have diverse safety levels and resource requirements, where the latter can change over time.
This talk will present the mapping and scheduling techniques, for CPUs, memories, and caches, along with automatic resource budgeting methods that reduce development time, and schedulability analyses that allow the timing requirements of tasks to be analytically verified. These techniques promote efficient resource usage by considering and managing variations in supply and demand of resources during execution, e.g. in response to a mode-switch in an executing task, or the system as a whole. This may reduce the cost of the platform required to schedule a given task set, or allow more tasks to be scheduled on a given platform.
Bio - Muhammad Ali Awan received his Master's Degree in System on Chip Design from the Royal Institute of Technology (KTH), Sweden in 2007. He completed his PhD with distinction from the University of Porto, Portugal in 2014 under the supervision of Stefan M. Petters in the area of “Real-Time Power Management on Partitioned Multicores”. He worked as a Lecturer at the National University of Science of Technology in Pakistan and as a researcher at IMEC Belgium. He has authored 25+ publications in ISI-indexed journals and prestigious conferences and served as PC member and external reviewer for many reputed conferences (EMSOFT, RTAS, RTSS, RTCSA, DATE, ECRTS and SIES) and top rated Journals (TECS, JSA, RTSJ, TC, TODAES) in the field of real-time systems. Currently, he is a research scientist at the CISTER Research Center and working on the design, implementation and performance analysis of safety-critical systems on a variety of hardware platforms. His research interests include real-time systems, multicore scheduling, mixed-criticality systems, safety-critical systems, energy-aware scheduling, heterogeneous multicore architecture design and exploration, power modelling and resource-aware system optimizations.
more...
Model-Centric Distributed Learning in Smart Community Sensing and Embedded Systems
Smart Community sensing is an efficient distributed paradigm that leverages the embedded sensors of community members to monitor the spatial-temporal phenomena in the environment, such as air pollution and temperature. The multi-party feature in community sensing increases the needs of distributed data collection, storage and processing, where it also benefits the privacy-preserved manner in different kinds of applications. Two types of distributed learning algorithms are usually used in community sensing, which is data-centric and model-centric. Each has its own merits on the variety of carriers for deployment. However, with the growth of embedded smart devices in real-world scenarios, we need to rethink and redesign the current distributed learning framework to appropriately deal with the trade-offs in these two classical models. In order to fully leverage the mobility, lite weight, low-cost and quick response of the embedded systems (devices), we propose multiple model-centric based distributed learning frameworks to handle the real-world cases/applications and demonstrate the superiority on the overall performance compared to the data-centric and centralized strategies. We will discuss the benefits of model-centric when embracing the community sensing and algorithm learning (training) on embedded systems.
CV:
Jiang Bian is a visiting Ph.D. student, supervised by Prof. Zhishan Guo at University of Central Florida (co-supervised by Prof. Haoyi Xiong, Baidu Research). His first two years of Ph.D are in Computer Science Department of Missouri University of Science and Technology. In advance of stepping in CECS doctoral research, he received my B.Eng degree of Logistics Systems Engineering in Huazhong University of Science and Technology in China, and earned my M.Sc degree of Industrial Systems Engineering in University of Florida. Jiang’s research interests include Human-subject Data Learning, Ubiquitous Computing and Intelligent Systems.

Synthesizing Real-Time Schedulability Tests using Evolutionary Algorithms : A Proof of Concept
Abstract: This talk assesses the potential for mechanised assistance in the formulation of schedulability tests. The novel idea is to use evolutionary algorithms to semi-automate the process of deriving response time analysis equations. The proof of concept presented focuses on the synthesis of mathematical expressions for the schedulability analysis of messages on Controller Area Network (CAN). This problem is of particular interest, since the original analysis developed in the early 1990s was later found to be flawed. Further, as well as known exact tests that have been formally proven, there are a number of useful sufficient tests of pseudo-polynomial complexity and closed-form polynomial-time upper bounds on response times that provide useful comparisons.
CV: Rob Davis is a Reader in the Real-Time Systems Research Group at the University of York, UK. He received his PhD in Computer Science from the University of York in 1995. Since then he has founded three start-up companies, all of which have succeeded in transferring real-time systems research into commercial products. Robert’s research interests include the following aspects of real-time systems: scheduling algorithms and analysis for single processor, multiprocessor and networked systems; analysis of cache related preemption delays, mixed criticality systems, and probabilistic hard real-time systems.
more...
With 6,200 employees in research, teaching and administration and its unique profile, TU Dortmund University shapes prospects for the future: the interaction between engineering and natural sciences as well as social and cultural studies drives both technological innovations and progress in knowledge and methodology. It is not only the roughly 34,500 students who benefit from this.The Department of Computer Science at TU Dortmund University is one of the largest in Germany, with particular strengths in research. Among similar institutions it is distinguished by a combination of fundamental research on formal methods with the development of practical applications. Research focuses on Algorithmics, Data Science, Cyber-Physical Systems, and Software and Service Engineering.
The successful candidate will specialize in research and teaching in the field of machine learning for industrial applications.
TU Dortmund University is seeking an outstanding individual and established scientist holding an excellent PhD with publications in highly ranked international journals or conference papers in the area of machine learning for industrial applications with a focus on the digital transformation of logistics and production (e.g. autonomous mobile robotic systems, machine perception, or in the context of smart production / smart factories).
This professorship is endowed by the KION GROUP AG.
Preconditions for employment are specified in § 36 and § 37 HG NRW (law governing universities in North-Rhine Westphalia).
TU Dortmund University strives to increase the number of women in academic research and teaching and therefore explicitly encourages women to apply.
TU Dortmund University is an equal opportunity employer and gives preference to candidates with disabilities if equally qualified.
TU Dortmund University supports the compatibility of work and family life and promotes gender equality in science.
Please send your application, including the usual documents(CV, list of publications, etc.), by either regular mail or e-mail (preferred, in one pdf-file) to the following address by 27.11.2019
Dean of the Department of Computer Science Prof. Dr.-Ing. Gernot A. Fink
TU Dortmund University
44221 Dortmund – Germany
phone:+49 231 755-6151
email: bewerbung@cs.tu-dortmund.de
http://www.cs.tu-dortmund.de/
Call for Applications for a W3 Professorship
more...
 Maximilian Meier has defended his dissertation Search for Astrophysical Tau Neutrinos using 7.5 years of IceCube Data at the Chair of Astroparticle Physics. He has developed a new event selection for tau neutrinos in IceCube and found two tau neutrinos candidates in his analysis.
Maximilian Meier has defended his dissertation Search for Astrophysical Tau Neutrinos using 7.5 years of IceCube Data at the Chair of Astroparticle Physics. He has developed a new event selection for tau neutrinos in IceCube and found two tau neutrinos candidates in his analysis.
The members of the doctoral committee were Prof. Dr. Dr. Wolfgang Rhode (supervisor and first assessor), Prof. Dr. Bernhard Spaan (second assessor), Prof. Dmitri Yakovlev (chairman of the examination committee) and Dr. Gerald Schmidt (representative of the scientific staff of the faculty). Maximilian Meier was previously a research assistant at Chair E5 as a member of Collaborative Research Centre 876 (Project C3) and is now working as a postdoctoral fellow at Chiba University.
 The publication "Nanoparticle Classification Using Frequency Domain Analysis on Resource-Limited Platforms" of the B2-project is selected as cover page of Journal of Sensors, Volume 19, Issue 19.
The publication "Nanoparticle Classification Using Frequency Domain Analysis on Resource-Limited Platforms" of the B2-project is selected as cover page of Journal of Sensors, Volume 19, Issue 19.
Abstract - A mobile system that can detect viruses in real time is urgently needed, due to the combination of virus emergence and evolution with increasing global travel and transport. A biosensor called "Plasmon Assisted Microscopy of Nano-sized Objects" represents a viable technology for mobile real-time detection of viruses and virus-like particles. It could be used for fast and reliable diagnoses in hospitals, airports, the open air, or other settings. For analysis of the images provided by the sensor, state-of-the-art methods based on convolutional neural networks (CNNs) can achieve high accuracy. However, such computationally intensive methods may not be suitable on most mobile systems. In this work, we propose nanoparticle classification approaches based on frequency domain analysis, which are less resource-intensive. We observe that on average the classification takes 29 μ s per image for the Fourier features and 17 μ s for the Haar wavelet features. Although the CNN-based method scores 1–2.5 percentage points higher in classification accuracy, it takes 3370 μ s per image on the same platform. With these results, we identify and explore the trade-off between resource efficiency and classification performance for nanoparticle classification of images provided by the sensor.
more...
The search for tau neutrinos with MAGIC telescopes
Abstract - n the multi-messenger era of Astronomy, the detection of neutrinos is quickly gaining its well-deserved importance: the broadband spectral energy distributions (SED) of astrophysical sources can be enriched by the presence of neutrinos emitted simultaneously to other wavebands. Neutrinos can be detected by ad-hoc experiments such as IceCube, ANTARES (Neutrino Telescope and Abyss environmental RESearch), Super-K (Super-Kamioka Neutrino Detection Experiment) and others, but recent results from the MAGIC Collaboration have shown that Imaging Atmosphere Cherenkov telescopes (IACTs) as MAGIC (Major Atmospheric Gamma-ray Cherenkov telescope) devoted to the study of very-high-energy gamma-rays are able to detect showers induced by earth-skimming neutrinos. Special simulations were recently developed to perform this peculiar analysis. In this work we analyse ~40 hours of data, taken by MAGIC telescopes when pointing to the Sea, using Monte Carlo simulations consisting of ANIS (All Neutrino Interaction Simulation), CORSIKA (COsmic Ray SImulations for KAscade) and MARS software. The selection criteria has been created with the support of Fisher discriminant analysis and the Genetic algorithm. These criteria can be applied to every sample of MAGIC data taken on very high zenith angles, making the next analysis on new data faster and more efficient. The analysis of tau neutrino induced shower is a non-standard procedure, and would largely benefit by the application of the here described procedure.
Recent research results and future directions within the SFB 876
October 10 & October 17, 2019, 16:15, Location: Campus North, Room C1-04-105
For the SFB-Workshop organized by Prof. Christian Wietfeld 8 interesting presentations could be won.
In the following you will find the program, which offers space for lively discussions:
October 10, 2019
16:15 Introduction to part 1
16:20 Applying Large Models on Small Devices - Sebastian Buschjäger - A1
16:40 Flexible Multi-Core Scheduling Help to Execute Machine Learning Algorithms Resource-Efficiently - Junjie Shi - A3
17:00 Gotta Catch 'Em All: Techniques and Potentials of Client-based Mobile Network Data Analysis - Robert Falkenberg - A4
17:20 A review on resource constraint distributed platforms for developing for integrative data analysis strategies - Moritz Roidl,
Aswin Ramachandran - A4
17:40 Closing and outlook to part 2
October 17, 2019
16:15 Introduction to part 2
16:20 Nanoparticle Classification Using Frequency Domain Analysis On Resource-limited Platforms - Mikail Yayla - B2, A1
16:40 Towards hybrid traffic with communicating automated vehicle - Tim Vranken B4
17:00 Towards data-driven simulation of end-to-end network performance indicators - Benjamin Sliwa - B4
17.20 The LHCb full software HLT1 reconstruction sequence on GPU - Holger Stevens - C5
17:40 Closing and next steps
The Advantages of Taiwan - Prospects for Development of AI
Abstract - Taiwan, one of the best freedom country in Asia with merely 23 million populations. There are many reasons make the small democracy country has amazing advantages of AI development. For example, a lot of talent in science and technology, comprehensive aggregated data, integration of software hardware, and so on. But the most important advantage is the value of humanity and integrity, which bring the AI solution to the world.

CV - Ethan Tu is an AI guru in Taiwan and formally worked as a principal development manager at US-based tech giant Microsoft Corp. He is also well-known as the founder of PTT, which has grown into one of Taiwan’s most influential online forums since its launch in 1995. In 2016 he founded the Taiwan AI Labs (https://ailabs.tw/) to leverage unique advantages in Taiwan to build AI solutions to solve the world’s problems, e.g., healthcare system, smart city solutions and social natural conversations
more...

Fine-Grained Complexity Theory: Hardness for a Big Data World
Abstract - For many data analysis tasks we know some polynomial time algorithm, say in quadratic time, but it is open whether faster algorithms exist. In a big data world, it is essential to close this gap: If the true complexity of the problem is indeed quadratic, then it is intractable on data arising in areas such as DNA sequencing or social networks. On such data essentially only near-linear time algorithms are feasible. Unfortunately, classic hardness assumptions such as P!=NP are too coarse to explain the gap between linear and quadratic time.
Fine-grained complexity comes to the rescue: It provides conditional lower bounds via fine-grained reductions from certain hard core problems. For instance, it allows us to rule out truly subquadratic algorithms for the Longest Common Subsequence problem (used e.g. in the diff file comparison tool), assuming a certain strengthening of P!=NP. This talk is an introduction to fine-grained complexity theory with a focus on dynamic programming problems.
more...
 Dr. Tim Ruhe, project leader in Project C3 since 2015, was admitted to the sixth year of the Global Young Faculty together with 43 other highly qualified and committed scientists and representatives from regional companies. The prestigious project is an initiative of the Mercator Foundation in cooperation with the University Alliance Ruhr and has been taking place since 2009. Within the framework of the Global Young Faculty, Tim Ruhe will work together with other scientists on an inter- and transdisciplinary project until March 2021. A budget of up to 250,000 euros per project is available to the participants. Scientific members also receive an individual travel budget of 5,000 euros.
Dr. Tim Ruhe, project leader in Project C3 since 2015, was admitted to the sixth year of the Global Young Faculty together with 43 other highly qualified and committed scientists and representatives from regional companies. The prestigious project is an initiative of the Mercator Foundation in cooperation with the University Alliance Ruhr and has been taking place since 2009. Within the framework of the Global Young Faculty, Tim Ruhe will work together with other scientists on an inter- and transdisciplinary project until March 2021. A budget of up to 250,000 euros per project is available to the participants. Scientific members also receive an individual travel budget of 5,000 euros.
 Anja Karliczek, Federal Minister of Education and Research, visited the Competence Center Machine Learning Rhine-Ruhr (ML2R) together with journalists on 9 July. The Minister took the opportunity to experience practical applications of artificial intelligence and machine learning live and to try them out for herself: She met robots that make AI and ML comprehensible in a playful way, discovered AI systems that analyse spoken language, improve satellite images and make autonomous driving safer, and a swarm of drones buzzed over her. This gave the Minister impressions of outstanding projects funded by the Federal Ministry of Education and Research (BMBF) as part of the ML2R.
Anja Karliczek, Federal Minister of Education and Research, visited the Competence Center Machine Learning Rhine-Ruhr (ML2R) together with journalists on 9 July. The Minister took the opportunity to experience practical applications of artificial intelligence and machine learning live and to try them out for herself: She met robots that make AI and ML comprehensible in a playful way, discovered AI systems that analyse spoken language, improve satellite images and make autonomous driving safer, and a swarm of drones buzzed over her. This gave the Minister impressions of outstanding projects funded by the Federal Ministry of Education and Research (BMBF) as part of the ML2R.
The CRC 876 was represented at this event with a small accompanying exhibition, which the Minister visited together with Katharina Morik.

Title: Logical Foundations of Cyber-Physical Systems
Abstract:
Cyber-physical systems (CPS) combine cyber aspects such as communication and computer control with physical aspects such as movement in space, which arise frequently in many safety-critical application domains, including aviation, automotive, railway, and robotics. But how can we ensure that these systems are guaranteed to meet their design goals, e.g., that an aircraft will not crash into another one?
This talk highlights some of the most fascinating aspects of cyber-physical systems and their dynamical systems models, such as hybrid systems that combine discrete transitions and continuous evolution along differential equations. Because of the impact that they can have on the real world, CPSs deserve proof as safety evidence.
Multi-dynamical systems understand complex systems as a combination of multiple elementary dynamical aspects, which makes them natural mathematical models for CPS, since they tame their complexity by compositionality. The family of differential dynamic logics achieves this compositionality by providing compositional logics, programming languages, and reasoning principles for CPS. Differential dynamic logics, as implemented in the theorem prover KeYmaera X, have been instrumental in verifying many applications, including the Airborne Collision Avoidance System ACAS X, the European Train Control System ETCS, automotive systems, mobile robot navigation, and a surgical robot system for skull-base surgery. This combination of strong theoretical foundations with practical theorem proving challenges and relevant applications makes Logic for CPS an ideal area for compelling and rewarding research.
CV: André Platzer is an Associate Professor of Computer Science at Carnegie Mellon University. He develops the logical foundations of cyber-physical systems to characterize their fundamental principles and to answer the question how we can trust a computer to control physical processes.
André Platzer has a Ph.D. from the University of Oldenburg in Germany and received an ACM Doctoral Dissertation Honorable Mention and NSF CAREER award. He received best paper awards at TABLEAUX'07 and FM'09 and was also named one of the Brilliant 10 Young Scientists by the Popular Science magazine and one of the AI's 10 to Watch by the IEEE Intelligent Systems Magazine.

Amal Saadallah has been selected as finalist at The European DatSci & AI Awards - Celebrating & Connecting Data Science Talent, category "Best Data Science Student of the Year". Amal works for the Research Project B3 "Data Mining in Sensor Data of Automated Processes" within the Collaborative Research Center 876.
The Data Science Award 2019 competition is open to individuals and teams working in the Data Science Ecosystem across Europe and is a unique opportunity to showcase research and application of Data Science/AI.
The Dortmund Data Science Center (DoDSc) is an interdisciplinary center of the TU Dortmund where the data science research within the TU Dortmund and its environment is bundled.
The first colloquium of the Dortmund Data Science Center will take place on Thursday, 11 July 2019. Between 8 and 10 short lectures of approx. 5 minutes each are planned. They will present current research work, projects and problems from various fields. This will allow the participating scientists to talk to each other and identify main fields of research for future cooperation.
Time: Thursday, 11 July 2019, 16-17 o'clock c.t.
Location: Lecture hall E23, Otto-Hahn-Str. 14, Campus North, TU Dortmund
 Sibylle Hess has successfully defended her dissertation A Mathematical Theory of Making Hard Decisions: Model Selection and Robustness of Matrix Factorization with Binary Constraints at the Chair of Artificial Intelligence. She developed new methodologies for two branches of clustering: the one concerns the derivation of nonconvex clusters, known as spectral clustering; the other addresses the identification of biclusters, a set of samples together with similarity defining features, via Boolean matrix factorization.
Sibylle Hess has successfully defended her dissertation A Mathematical Theory of Making Hard Decisions: Model Selection and Robustness of Matrix Factorization with Binary Constraints at the Chair of Artificial Intelligence. She developed new methodologies for two branches of clustering: the one concerns the derivation of nonconvex clusters, known as spectral clustering; the other addresses the identification of biclusters, a set of samples together with similarity defining features, via Boolean matrix factorization.
The members of the doctoral committee were Prof. Dr. Katharina Morik (supervisor and first examiner), Prof. Dr. Arno Siebes (second examiner, University of Utrecht) and Prof. Dr. Erich Schubert (representative of the faculty). Sibylle Hess was a research assistant at LS8, a member of the Collaborative Research Center 876 (Project C1) and now works as a postdoctoral fellow at the TU Eindhoven.
Prof. Katharina Morik (TU Dortmund)
Prof. Rainer Doemer (UC Irvine)
Prof. Heiko Falk (Hamburg University of Technology)
Prof. Jian-Jia Chen (TU Dortmund)
Prof. Gernot Fink (TU Dortmund)
more...
Pushing the Limits of Parallel Discrete Event Simulation for SystemC (Prof. Rainer Dömer, UC Irvine)
Computing with NCFET: Challenges and Opportunities (Prof. Jörg Henkel, KIT Karlsruhe)
Run-Time Enforcement of Non-functional Program Properties on MPSoCs (Prof. Jürgen Teich, University of Erlangen)
Compilation for Real-Time Systems 10 Years After PREDATOR (Prof. Heiko Falk, TU Hamburg)
more...
Towards Making Chips Self-Aware (Prof. Nikil Dutt, UC Irvine)
As Embedded Systems Became Serious Grown-Ups, They Decide on Their Own (Prof. Andreas Herkersdorf, TU München)
more...
M3 - Not just yet another micro-kernel (Prof. Hermann Härtig, TU Dresden)
Property-based Analysis for Real-Time Embedded Systems (Prof. Jian-Jia Chen, TU Dortmund)
ASSISTECH: A Journey from Embedded Systems to Affordable Technology Solutions for the Visually Impaired (Prof. M. Balakrishnan, IIT Delhi)
more...
Testing Implementation Soundness of a WCET Tool (Prof. Reinhard Wilhelm, Saarland University)
Controlling Concurrent Change - Automating Critical Systems Integration (Prof. Rolf Ernst, TU Braunschweig)
The (DRAM) Memory Challenge in Embedded Computing Systems (Prof. Norbert Wehn, TU Kaiserslautern)
more...
We a proud to announce the Workshop on Embedded Systems in Dortmund, dedicated to Peter Marwedel on the occasion of his 70th birthday, from July 4th to 5th, 2019. The workshop features 12 scientific talks and is announced as a colloquium of the computer science faculty.
Place:
Room E23, Otto-Hahn-Strasse 14, 44227 Dortmund, Germany
Date:
04-05 July, 2019 (lunch to lunch)
![]()
In its March edition, the Nature Career Guide recommends international researchers to move to Germany. The Collaborative Research Centres of the German Research Foundation (DFG) are named as one of ten reasons for this.
Collaborative research
Germany has more than 270 collaborative research centres that are funded by the German Research Foundation (DFG) for periods of up to 12 years, giving researchers the time to work on complex, long-term, multidisciplinary projects across universities and institutes. In 2017, the DFG spent nearly €3.2 billion on research funding. Such spending efforts are paying off, says cancer researcher Ivan Dikic, who is originally from Croatia but has been in Germany for 15 years and now heads the biochemistry department at Goethe University Frankfurt. “The German government has invested a lot more money in top-class science, and that attracts a lot of highly talented people,” he says.
more...
Title: Adversarial Robustness of Machine Learning Models for Graphs
Abstract — Graph neural networks and node embedding techniques have recently achieved impressive results in many graph learning tasks. Despite their proliferation, studies of their robustness properties are still very limited -- yet, in domains where graph learning methods are often used, e.g. the web, adversaries are common. In my talk, I will shed light on the aspect of adversarial robustness for state-of-the art graph-based learning techniques. I will highlight the unique challenges and opportunities that come along with the graph setting and introduce different perturbation approaches showcasing the methods vulnerabilities. I will conclude with a short discussion of methods improving robustness.
Biography — Stephan Günnemann is a Professor at the Department of Informatics, Technical University of Munich. He acquired his doctoral degree in 2012 at RWTH Aachen University, Germany in the field of computer science. From 2012 to 2015 he was an associate of Carnegie Mellon University, USA; initially as a postdoctoral fellow and later as a senior researcher. Stephan Günnemann has been a visiting researcher at Simon Fraser University, Canada, and a research scientist at the Research & Technology Center of Siemens AG. His main research interests include the development of robust and scalable machine learning techniques for graphs and temporal data. His works on subspace clustering on graphs as well as his analysis of adversarial robustness of graph neural networks have received the best research paper awards at ECML-PKDD 2011 and KDD 2018.
Title: Decentralized brain in low data-rate, low power networks for collaborative manoeuvres in space
Abstract: This talk will provide insight into the topic of decentralized brain and an implementation that was developed under SFB876 and tested above the Kármán line (100 km). Self-assembly protocols for aerospace structures development require a communication architecture that can assist in the decentralized control of those structures. The architecture presented in this talk is an infrastructure-less networking framework with a self-organizing wireless communications networking protocol; this includes a communication primitive for data structure replication with consistency that acts as a shared brain between the nodes. This article also presents the applicability for such a communication architecture in space applications with a proof-of-concept implementation in ultra-low power hardware to demonstrate the feasibility. The results of the suborbital tests will be discussed along with future developments on large-scale testing of the communication architecture, self-assembly experiments in space with connection to machine learning and the importance of decentralised communication.
CV: Aswin Karthik Ramachandran Venkatapathy has a Master's degree in Automation and Robotics and currently pursuing a research career at the chair of "Material Handling and Warehousing", Technical University of Dortmund, Germany. He is a Human-Machine Systems enthusiast with interests towards heterogeneous wireless communication, systems communication and integration of smart objects in industrial processes with emphasis in the field of Information Logistics. He is a visiting researcher at MIT Media Lab and the Space Exploration Initiative collaborating in developing and deploying experiments for self-assembly space architectures as part of SFB876. He is also working at the department of "Automation and Embedded systems" at Fraunhofer IML for deploying smart devices and robot systems for logistics processes.

The 5th Digital Future Science Match brought together AI experts from science, industry and politics to answer the question: What’s Next in Artificial Intelligence? Katharina Morik gave the keynote “AI and the sciences”.
more...

Title: Distributed Convex Thresholding
Abstract
Over the last two decades years, a large group of algorithms emerged which compute various predicates from distributed data with a focus on communication efficiency. These algorithms are often called "communication-efficient", "geometric-monitoring", or "local" algorithms and are jointly referred as distributed convex thresholding (DCT) algorithms. DCT algorithms have found their applications in domains in which bandwidth is a scarce resource, such as wireless sensor networks and peer-to-peer systems, or in scenarios in which data rapidly streams to the different processors but outcome of the predicate rarely changes. Common to all of DCT algorithms is their use of a data dependent criteria to determine when further messaging is no longer required.
This work presents two very simple yet exceedingly general theorems which provide an alternative proof of correctness for any DCT algorithm. This alternative proof does not depend on the communication infrastructure and hence algorithms which depended on specific architectures (all but one of the previous work) are immediately extended to general networks. Because the theorems are general, they vastly extend the range of predicates which can be computed using DCT. Critical inspection of previous work in light of the new proof reveals that they contain redundant requirements, which cause unneeded messaging.
Work originally presented in PODC'15
Bio
Ran graduated from the computer science department of the Technion - Israel Institute of Technology. He previously held positions with the University of Maryland at Baltimore County and the department of information systems at the university of Haifa. In recent years he is a principle research scientist at Yahoo research, now a part of Verizon and still teaches privacy and information ethics courses at several Israeli universities. Ran's active research areas are data mining and the theory of privacy.
Meetings
His current academic focus is the theory of privacy and information ethics in general. Ran Wolff would like to invite interested students and faculty to discuss possible collaboration. For a preview of his work in this area please see https://www.pdcnet.org/jphil/content/jphil_2015_0112_0003_0141_0158. Please contact Jens Buß (jens.buss@tu-dortmund) for a time slot to talk to Ran Wolff.
Title:
Looking Past The Internet of Things - How We Will Connect To Our Networked Future
Abstract:
We have already witnessed profound and often unanticipated developments as IoT is built out and the world is mediated via a mainly graphic wireless device held at arm’s length. But what will happen once the world is precognitively interpreted by what we term ‘sensory prosthetics’ that change what and how humans physically perceive, a world where your own intelligence is split ever more seamlessly between your brain and the cloud? Accordingly, this talk will overview the broad theme of interfacing humans to the ubiquitous electronic "nervous system" that sensor networks will soon extend across things, places, and people, going well beyond the ‘Internet of Things,’ challenging the notion of physical presence. I'll illustrate this through two avenues of research - one looking at a new kind of digital "omniscience" (e.g., different kinds of browsers for sensor network data & agile frameworks for sensor/data representation) and the other looking at buildings & tools as "prosthetic" extensions of humans (e.g., making HVAC and lighting systems an extension of your natural activity and sense of comfort, or smart tools as human-robot cooperation in the hand), drawing from many projects that are running in my group at the MIT Media Lab and touching on technical areas ranging from low-power wearable sensing/computing to spatialized/cognitive audio and distributed sensor networks.
CV:
Joseph Paradiso joined the MIT Media Laboratory in 1994, where he is the Alexander W. Dreyfoos (1954) Professor in Media Arts and Sciences. He is currently serving as the associate academic head of the MAS Program, and also directs the Media Lab's Responsive Environments Research Group, which explores which explores how sensor networks augment and mediate human experience, interaction and perception. His current research interests include embedded sensing systems and sensor networks, wearable and body sensor networks, energy harvesting and power management for embedded sensors, ubiquitous and pervasive computing, localization systems, passive and RFID sensor architectures, human-computer interfaces, smart rooms/buildings/cities, and interactive music/media. He has also served as co-director of the Things That Think Consortium, a group of Media Lab researchers and industrial partners examining the extreme future of embedded computation and sensing.
Full bio: http://paradiso.media.mit.edu/Bio.html
Deep Learning and the AI-Hype
Abstract:
Deep learning, referring to machine learning with deep neural networks, has revolutionized data science. It receives media attention, billion dollar investments, and caused rapid growth of the field. In this talk I will present the old and new technologies behind deep learning, which problems have been solves, and how intelligent this hyped new "artificial intelligence" really is.
CV:
Tobias Glasmachers is a professor for theory of machine learning at the Institut für Neuroinformatik, Ruhr-Universität Bochum, Germany. His research interests are (supervised) machine learning and optimization.
2004-2008: Ph.D. in Christian Igel's group at the Institut für Neuroinformatik in Bochum. He received my Ph.D. in 2008 from the Faculty of Mathematics, Ruhr-Universität Bochum, Germany; 2008-2009: Post-doc in the same group;
2009-2011: Post-doc in Jürgen Schmidhuber's group at IDSIA, Lugano, Switzerland;
2012-2018: Junior professor for theory of machine learning at the Institut für Neuroinformatik, Ruhr-Universität Bochum, Germany. He is the head of the optimization of adaptive systems group;
2018: Promotion to full professor.

Generative Models
Abstract:
Generative models are a set of unsupervised learning techniques, which attempt to model the distribution of the data points themselves instead of predicting labels from them. In recent years, deep learning approaches to generative models have produced impressive results in areas such as modeling of images (BigGAN), audio (WaveNet), language (Transformer, GPT-2) and others. I'm going to give an overview of the three most popular underlying methods used in deep generative models today: Autoregressive models, generative adversarial networks and variational autoencoders. I will also go over some of the state of the art models and explain how they work.
CV:
Igor Babuschkin is a Senior Research Engineer at DeepMind, Google's artificial intelligence division with the ambitious goal of building a general artificial intelligence. He studied physics at the TU Dortmund (2010-2015), where he was involved in experimental particle physics research at the LHCb experiment at CERN. He then switched fields to machine learning and artificial intelligence, joining DeepMind in 2017. Since then he has been working on new types of generative models and approaches to scalable deep reinforcement learning. He is a tech lead of DeepMind's AlphaStar project, which recently produced the first software agent capable of beating a professional player at the game of StarCraft II.
Title: Optimization and Analysis for Dependable Application Software on Unreliable Hardware Platforms (PhD thesis defense)
Bio
Kuan-Hsun Chen is a PhD student at Arbeitsgruppe Entwurfsautomatisierung für Eingebettete Systeme, Technical University of Dortmund (TUDo), Germany. He received his Master in Computer Science from National Tsing Hua University, Taiwan, in 2013. He received Best Student Paper Award (IEEE RTCSA in 2018).

Title:
Learning in a dynamic and ever changing world
Abstract:
The world is dynamic – in a constant state of flux – but most learned models are static. Models learned from historical data are likely to decline in accuracy over time. I will present our recent work on how to address this serious issue that confronts many real-world applications of machine learning. Methodology: we are developing objective quantitative measures of drift and effective techniques for assessing them from sample data. Theory: we posit a strong relationship between drift rate, optimal forgetting rate and optimal bias/variance profile, with the profound implication that the fundamental nature of a learning algorithm should ideally change as drift rate changes. Techniques: we have developed the Extremely Fast Decision Tree, a statistically more efficient variant of the incremental learning workhorse, the Very Fast Decision Tree.
Short bio:
Geoff Webb is a leading data scientist. He is Director of the Monash University Centre for Data Science and a Technical Advisor to data science startups FROOMLE and BigML Inc. The latter have incorporated his best of class association discovery software, Magnum Opus, as a core component of their advanced Machine Learning service.
He developed many of the key mechanisms of support-confidence association discovery in the late 1980s. His OPUS search algorithm remains the state-of-the-art in rule search. He pioneered multiple research areas as diverse as black-box user modelling, interactive data analytics and statistically-sound pattern discovery. He has developed many useful machine learning algorithms that are widely deployed.
He was editor in chief of the premier data mining journal, Data Mining and Knowledge Discovery from 2005 to 2014. He has been Program Committee Chair of the two top data mining conferences, ACM SIGKDD and IEEE ICDM, as well as General Chair of ICDM. He is an IEEE Fellow.
His many awards include the prestigious inaugural Australian Museum Eureka Prize for Excellence in Data Science.
Scalable Time-series Classification
Abstract: Time-series classification is a pillar problem for the machine learning community, particularly considering the wide range of applicable domains. In this talk, the focus is on prediction models that are scalable both in terms of the training efforts, but also with regards to the inference time and memory footprint. Concretely, time-series classification through models that are based on discriminative patterns will be presented. Finally, the talk will end with a recent application on biometric verification.
Bio: Dr. Josif Grabocka is a Postdoc at the University of Hildesheim, Information Systems and Machine Learning Lab, working in the research team of Prof. Dr. Dr. Lars Schmidt-Thieme. He graduated his PhD in Machine Learning from the University of Hildesheim in 2016. Dr. Grabocka's primary research interests lie on mining time-series data and more recently on Deep Learning techniques for sequential data.

The SFB876 is following with great interest the ongoing auction of frequencies for the new mobile radio standard 5G. In the course of the auction, the value of the limited available 5G spectrum will be measured. Currently, the bidders involved in the auction have already exceeded the 2 billion Euro limit.
The new mobile radio standard promises significantly increased transmission rates, ultra-reliable real-time communication (e.g. for autonomous driving and production environments) and maximum scalability to serve a massive number of small devices for the Internet of Things (IoT). In order to achieve these goals, the limited spectrum available must be utilized very efficiently. Using the latest methods of machine learning at all system levels, the SFB876 is also developing methods for increasing and ensuring scalability, energy efficiency, reliability and availability of 5G communication systems in subprojects A4 and B4.
For interested parties, the Communication Networks Institute, which is involved in both subprojects, continuously visualizes the round results of the current 5G auction:
https://www.kn.e-technik.tu-dortmund.de/cms/en/institute/News/2019/5G-Auktion/5G-Auction-Statistics/
![]()
The deep learning based software "PyTorch Geometric" from the projects A6 and B2 is a PyTorch based library for deep learning on irregular input data like graphs, point clouds or manifolds. In addition to general data structures and processing methods, the software contains a variety of recently published methods from the fields of relational learning and 3D computing.
Last Friday, the software attracted some attention via Twitter and Facebook when it was specifically shared and recommended by Yann LeCun. Since then, it has been collecting around 250 stars a day on GitHub and can be found in particular among the trending repositories at GitHub.
PyTorch Geometric (PyG) is freely available on GitHub at https://github.com/rusty1s/pytorch_geometric.
more...
Representation and Exploration of Patient Cohorts
Abstract The availability of health-care data calls for effective analysis methods which help medical experts gain a better understanding of their data. While the focus has been largely on prediction, representation and exploration of health-care data have received little attention. In this talk, we introduce CORE, a data-driven framework for medical cohort representation and exploration. CORE builds a succinct representation of a cohort by pruning insignificant events using sequence matching. It also prioritizes patient attributes to short-list a set of interesting contrast cohorts as exploration candidates. We discuss real use cases that we developed in collaboration with Grenoble hospital and show the usability of CORE in interactions with our medical partners
Bio Behrooz Omidvar-Tehrani is a postdoctoral researcher at the University of Grenoble Alpes, France. Previously, he was a postdoctoral researcher at the Ohio State University, USA. His research is in the area of data management, focusing on interactive analysis of user data. Behrooz received his PhD in Computer Science from University of Grenoble Alpes, France. He has published in several international conferences and journals including CIKM, ICDE, VLDB, EDBT, DSAA and KAIS. Also, he has been a reviewer for several conferences and journals including Information Systems, TKDE, DAMI, CIKM, ICDE, and AAAI.
more...

The Industrial Data Science Conference gathers experts from various industries and focuses on data science applications in industry, use cases, and best practices to foster the exchange of experience, discussions with peers and experts, and learning from presenters and other attendees.
Digitization, the Internet of Things (IoT), the industrial internet, and Industry 4.0 technologies are transforming complete industries and allow the collection of enormous amounts of data of various types, including Big Data and Streaming Data, structured and unstructured data, text, image, audio, and sensor data. Data Science, Data Mining, Process Mining, Machine Learning, and Predictive Analytics offer the opportunity to generate enormous value and a competitive advantage. Typical use cases include demand forecasting, price forecasting, predictive maintenance, machine failure prediction and prevention, critical event prediction and prevention, product quality prediction, process optimization, mixture of ingredients optimization, and assembly plan predictions for new product designs in industries like automotive, aviation, energy, manufacturing, metal, etc.
Join your peers in the analytics community at IDS 2019 as we explore breakthrough research and innovative case studies that discuss how to best create value from your data using advanced analytics.
|
Date |
March 13th, 2019 |
| Location | DASA Arbeitswelt Ausstellung |
| Web | IDS 2019 |

AAAI 2019 unified all AI, 3000 participants, at the conference in Honolulu: Perception, Representation and Reasoning, Learning, Natural Interaction, Societal Impact. 1147 papers have been accepted (submitted 7095) with the most coming from China, followed by USA, Japan and at 4th rank Germany.
Sibylle Hess (C1) gave the talk for our paper:
Sibylle Hess, Wouter Duivesteijn, Katharina Morik, Philipp-Jan Honysz
"The SpectACl of Nonconvex Clustering: A Spectral Approach to Density-Based Clustering",
Christopher Morris (A6) presented:
Christopher Morris, Martin Ritzert, Matthias Fey, William L. Hamilton, Jan Eric Lenssen, Gaurav Rattan, Martin Grohe
"Weisfeiler and Leman Go Neural: Higher-order Graph Neural Networks".
Explain Yourself - A Semantic Stack for Artificial Intelligence
Abstract:
Artificial Intelligence is the pursuit of the science of intelligence. The journey includes everything from formal reasoning, high-performance game playing, natural language understanding, and computer vision. Each AI experimental domain is littered along a spectrum of scientific explainability, all the way from high-performance but opaque predictive models, to multi-scale causal models. While the current AI pandemic is preoccupied with human intelligence and primitive unexplainable learning methods, the science of AI requires what all other science requires: accurate explainable causal models. The presentation introduces a sketch of a semantic stack model, which attempts to provide a framework for both scientific understanding and implementation of intelligent systems. A key idea is that intelligence should include an ability to model, predict, and explain application domains, which, for example, would transform purely performance-oriented systems into instructors as well.
Biography:
Randy Goebel is currently professor of Computing Science in the Department of Computing Science at the University of Alberta, Associate Vice President (Research) and Associate Vice President (Academic), and Fellow and co-founder of the Alberta Machine Intelligence Institute (AMII). He received the B.Sc. (Computer Science), M.Sc. (Computing Science), and Ph.D. (Computer Science) from the Universities of Regina, Alberta, and British Columbia, respectively. Professor Goebel's theoretical work on abduction, hypothetical reasoning and belief revision is internationally well know, and his recent research is focused on the formalization of visualization and explainable artificial intelligence (XAI). He has been a professor or visiting professor at the University of Waterloo, University of Regina, University of Tokyo, Hokkaido University, Multi-media University (Malaysia), National Institute of Informatics, and a visiting researcher at NICTA (now Data 61) in Australia, and DFKI and VW Data:Lab in Germany. He has worked on optimization, algorithm complexity, systems biology, and natural language processing, including applications in legal reasoning and medical informatics.
Contextual Bandit Models for Long- and Short-Term Recommendations
Recommender systems aim to capture interests of users to provide tailored recommendations. User interests are often unique and depend on many unobservable factors including internal moods or external events. We present a unified contextual bandit framework for recommendation problems that is able to capture both short- and long-term interests of users. The model is devised in dual space and the derivation is consequentially carried out using Fenchel-Legrende conjugates and thus leverages to a wide range of tasks and settings. We detail two instantiations for regression and classification scenarios and obtain well-known algorithms for these special cases. The resulting general and unified framework allows for quickly adapting contextual bandits to different applications at-hand. The empirical study demonstrates that the proposed short- and long-term framework outperforms both, short-term and long-term models. Moreover, a tweak of the combined model proves beneficial in cold start problems.
Bio
Maryam Tavakol is in the last year of her PhD studies in Machine Learning at TU Darmstadt under joint supervision of prof. Ulf Brefeld and Johannes Fürnkranz, whilst working as a research assistant in Machine Learning group at Leuphana University of Lüneburg. The main area of her research during PhD is to use machine learning techniques, particularly, Reinforcement Learning in sequential recommendation systems which has led to novel contributions in the area of recommendation. Before that, she received both of her bachelor and master degrees in Computer Science from the university of Tehran in Iran.
She also has a 6-month internship experience in recommender system group of Criteo company in Paris.

Neuroblastomas—the most common tumor type in infants—develop from fetal nerve cells, and their clinical course is highly variable. Some neuroblastomas are fatal despite treatment, whereas others respond well to treatment and some undergo spontaneous regression without treatment. Ackermann et al. sequenced more than 400 pretreatment neuroblastomas and identified molecular features that characterize the three distinct clinical outcomes. Low-risk tumors lack telomere maintenance mechanisms, intermediate-risk tumors harbor telomere maintenance mechanisms, and high-risk tumors harbor telomere maintenance mechanisms in combination with RAS and/or p53 pathway mutations.
more...
The research group of Jian-Jia Chen received an outstanding paper award for their paper Dependency Graph Approach for Multiprocessor Real-Time Synchronization in IEEE Real-Time Systems Symposium (RTSS) 2018, Dec. 11-14, Nashville, USA.

Abstract
The european lab CERN in Geneva hosts with the Large Hadron Collider and its experiments todays most advanced particle accelerator and detectors. The dataset generated is about 1PB per second.
The talk focusses on the LHCb experiment, one of the four big experiments at the LHC. The real time data processing, the trigger system, is discussed as well hints to possible physics discoveries that are currently seen in the data.
Bio
Johannes Albrecht received his PhD from Heidelberg University in 2009 and moved then to CERN as senior research fellow. From 2013 he is based at TU Dortmund, first as Emmy-Noether group leader and since 2016 with a research group awarded by the European research council (ERC starting grant).
His research interest is experimental particle physics, in the past decade of running of the LHCb experiment at CERN, he performed many physics measurements and is currently responsible for the physics as deputy physics coordinator. His second research focus is on event triggering, where petabytes of data are reconstructed and filtered in real time on a dedicated Event Filter Farm with currently 27000 physical cores.
more...
The Deutsche Forschungsgemeinschaft (DFG) granted the next four years of the collaborative research center SFB 876. The following projects will continue their research:

The joint work on "Analysis of Deadline Miss Rates for Uniprocessor Fixed-Priority Scheduling" by Kuan-Hsun Chen, Georg von der Brüggen and Jian-Jia Chen was awarded the RTCSA Best Student Paper Award. The conference, which took place this August in Hakodate, Japan, focuses on the technology of embedded and real-time systems as well as their emerging applications. The paper is a direct result of the research done in the CRC project B2.
Abstract
Timeliness is an important feature for many embedded systems. Although soft real-time embedded systems can tolerate and allow certain deadline misses, it is still important to quantify them to justify whether the considered systems are acceptable. In this paper, we provide a way to safely over-approximate the expected deadline miss rate for a specific sporadic real-time task under fixed-priority preemptive scheduling in uniprocessor systems. Our approach is compatible with the existing results in the literature that calculate the probability of deadline misses either based on the convolution-based approaches or analytically. We demonstrate our approach by considering randomly generated task sets with an execution behavior that simulates jobs that are subjected to soft errors incurred by hardware transient faults under a given fault rate. To empirically gather the deadline miss rates, we implemented an event-based simulator with a fault-injection module and release the scripts. With extensive simulations under different fault rates, we evaluate the efficiency and the pessimism of our approach. The evaluation results show that our approach is effective to derive an upper bound of the expected deadline miss rate and efficient with respect to the required computation time.

The 2018 William C. Carter PhD Dissertation Award in Dependability has been awarded to Christoph Borchert for his disseration "Aspect-Oriented Technology for Dependable Operating Systems" done at the Technische Universität Dortmund, Germany. Christoph will be presenting his dissertation at the 2018 International Conference on Dependable Systems and Networks (DSN) in Luxembourg in late June.
Abstract:
Modern computer devices exhibit transient hardware faults that disturb the electrical behavior but do not cause permanent physical damage to the devices. Transient faults are caused by a multitude of sources, such as fluctuation of the supply voltage, electromagnetic interference, and radiation from the natural environment. Therefore, dependable computer systems must incorporate methods of fault tolerance to cope with transient faults. Software-implemented fault tolerance represents a promising approach that does not need expensive hardware redundancy for reducing the probability of failure to an acceptable level.
This thesis focuses on software-implemented fault tolerance for operating systems because they are the most critical pieces of software in a computer system: All computer programs depend on the integrity of the operating system. However, the C/C++ source code of common operating systems tends to be already exceedingly complex, so that a manual extension by fault tolerance is no viable solution. Thus, this thesis proposes a generic solution based on Aspect-Oriented Programming (AOP).
To evaluate AOP as a means to improve the dependability of operating systems, this thesis presents the design and implementation of a library of aspect-oriented fault-tolerance mechanisms. These mechanisms constitute separate program modules that can be integrated automatically into common off-the-shelf operating systems using a compiler for the AOP language. Thus, the aspect-oriented approach facilitates improving the dependability of large-scale software systems without affecting the maintainability of the source code. The library allows choosing between several error-detection and error-correction schemes, and provides wait-free synchronization for handling asynchronous and multi-threaded operating-system code.
This thesis evaluates the aspect-oriented approach to fault tolerance on the basis of two off-the-shelf operating systems. Furthermore, the evaluation also considers one user-level program for protection, as the library of fault-tolerance mechanisms is highly generic and transparent and, thus, not limited to operating systems. Exhaustive fault-injection experiments show an excellent trade-off between runtime overhead and fault tolerance, which can be adjusted and optimized by fine-grained selective placement of the fault-tolerance mechanisms. Finally, this thesis provides evidence for the effectiveness of the approach in detecting and correcting radiation-induced hardware faults: High-energy particle radiation experiments confirm improvements in fault tolerance by almost 80 percent.
more...
We are very happy that Benjamin Sliwa from the Communication Networks Institute (CNI) has received the Best Student Paper award of the IEEE Vehicular Technology Conference (VTC) Spring-2018, which took place in June in Porto, Portugal (see photo). The VTC is the flagship conference of the Vehicular Technology Society within the IEEE and is typically attended by approx. 600 international scientists with a focus on wireless and mobile communications. The contribution "Efficient Machine-type Communication using Multi-metric Context-awareness for Cars used as Mobile Sensors in Upcoming 5G Network" has been co-authored by further CNI members Robert Falkenberg, Johannes Pillmann and Christian Wietfeld jointly with Thomas Liebig from the Computer Science department. It was selected from over 200 papers of the conference with PhD students as first author. The paper reports on key results of the research of projects B4 "Analysis and Communication for Dynamic Traffic Prognosis" and A4 "Resource efficient and distributed platforms for integrative data analysis" within the Collaborative Research Centre (SFB 876). The results of the paper demonstrate the significant potential of machine-learning for the optimization of mobile networks.

The paper can be found here:
and also within the coming weeks in the IEEE Xplore electronic proceedings.
Just Machine Learning
Fairness in machine learning is an important and popular topic these days. Most papers in this area frame the problem as estimating a risk score. For example, Jack’s risk of defaulting on a loan is 8, while Jill's is 2. These algorithms are supposed to produce decisions that are probabilistically independent of sensitive features (such as gender and race) or their proxies (such as zip codes). Some examples here include precision parity, true positive parity, and false positive parity between groups in the population. In a recent paper, Kleinberg, Mullainathan, and Raghavan (arXiv:1609.05807v2, 2016) presented an impossibility result on simultaneously satisfying three desirable fairness properties when estimating risk scores with differing base rates in the population. I take a boarder notion of fairness and ask the following two questions: Is there such a thing as just machine learning? If so, is just machine learning possible in our unjust world? I will describe a different way of framing the problem and will present some preliminary results.
Bio
Tina Eliassi-Rad is an Associate Professor of Computer Science at Northeastern University in Boston, MA. She is also on the faculty of Northeastern's Network Science Institute. Prior to joining Northeastern, Tina was an Associate Professor of Computer Science at Rutgers University; and before that she was a Member of Technical Staff and Principal Investigator at Lawrence Livermore National Laboratory. Tina earned her Ph.D. in Computer Sciences (with a minor in Mathematical Statistics) at the University of Wisconsin-Madison. Her research is rooted in data mining and machine learning; and spans theory, algorithms, and applications of massive data from networked representations of physical and social phenomena. Tina's work has been applied to personalized search on the World-Wide Web, statistical indices of large-scale scientific simulation data, fraud detection, mobile ad targeting, and cyber situational awareness. Her algorithms have been incorporated into systems used by the government and industry (e.g., IBM System G Graph Analytics) as well as open-source software (e.g., Stanford Network Analysis Project). In 2010, she received an Outstanding Mentor Award from the Office of Science at the US Department of Energy. For more details, visit http://eliassi.org.
Consistent k-Clustering
The study of online algorithms and competitive analysis provide a solid foundation for studying the quality of irrevocable decision making when the data arrives in an online manner. While in some scenarios the decisions are indeed irrevocable, there are many practical situations when changing a previous decision is not impossible, but simply expensive. In this work we formalize this notion and introduce the consistent k- clustering problem. With points arriving online, the goal is to maintain a constant approximate solution, while minimizing the number of reclusterings necessary. We prove a lower bound, showing that O(k log n) changes are necessary in the worst case, for a wide range of objective functions. On the positive side, we give an algorithm that needs only O(k^2 log^4 n) changes to maintain a constant competitive solution. This is an exponential improvement on the naive solution of reclustering at every time step. Finally, we show experimentally that our approach performs much better than the theoretical bound, with the number of changes growing approximately as O(log n).
Joint work with Sergei Vassilvitskii.
From Best-effort Monitoring to Feedback Control: How Synchronous Transmissions Enable the Future Internet of Things
Wirelessly networked sensors, actuators, and computing elements are increasingly being brought to bear on societal-scale problems ranging from disaster response and personalized medicine to precision agriculture and intelligent transportation. Often referred to as the Internet of Things (IoT) or Cyber-physical Systems (CPS), these networks are embedded in the environment for monitoring and controlling physical processes.
In this talk, I will begin by illustrating some of the opportunities and challenges of these emerging systems using a real-world application scenario. I will highlight how we tackle the challenge of wirelessly networking the IoT devices in a predictable and adaptive, yet highly efficient manner. At the core of our solution is a disruptive communication paradigm we conceived, synchronous transmissions, that allowed us to build a wireless bus that abstracts a complex multi-hop wireless network as a single entity with known properties and predictable behavior. Besides its superior performance and reliability compared with state-of-the-art solutions, I will show that the broadcast communication model of the wireless bus enables applying concepts from distributed computing, embedded systems, and feedback control to provide functionality and formally proven guarantees previously thought impossible.
On the Local Structure of Stable Clustering Instances
As an optimization problem, clustering exhibits a striking phenomenon: It is generally regarded as easy in practice, while theory classifies it among the computationally intractable problems. To address this dichotomy, research has identified a number of conditions a data set must satisfy for a clustering to be (1) easily computable and (2) meaningful.
In this talk we show that all previously proposed notions of struturedness of a data set are fundamentally local properties, i.e. the global optimum is in well defined sense close to a local optimum. As a corollary, this implies that the Local Search heuristic has strong performance guarantees for both the tasks of recovering the underlying optimal clustering and obtaining a clustering of small cost. The talk is based on joint work with Vincent Cohen-Addad, FOCS 2017.
Bio
Chris Schwiegelshohn is currently a post-doc in Sapienza, University of Rome. He did his Phd in Dortmund with a thesis on "Algorithms for Large-Scale Graph and Clustering Problems". Chris' research interests include streaming and approximation algorithms as well as machine learning.
Performance Evaluation for Annealing Based Quantum Computers
A D-Wave quantum processing unit (QPU) implements an algorithm in hardware that exploits quantum properties (such as superposition and entanglement), to heuristically solve instances of the Ising model problem, which may be more familiar as quadratic unconstrained binary optimization (QUBO). The current 2000Q model contains 2000 qubits.
The algorithmic approach it uses, called Quantum Annealing (QA), falls in the adiabatic quantum model of computation (AQC), which is an alternative to the more familiar gate model (GM) of quantum computation. Relatively little is known theoretically about QA and AQC; but on the other hand the existence of quantum computing systems of reasonable size make empirical approaches to performance analysis possible.
I will give an introductory overview of quantum annealing and D-Wave processors, show how to solve Max Cut problems on these novel computing platforms, and survey what is known about performance on this problem. No background in Physics is assumed.
Bio
Catherine McGeoch received her PhD from Carnegie Mellon University in 1987. She spent almost 30 years contentedly in academia, on the faculty at Amherst College. In 2014 she decided to shake things up, and joined the benchmarking team at D-Wave Systems.
Her research interests are in experimental methods for evaluating algorithms and heuristics, with recent emphasis on quantum algorithms and platforms. She co-founded the DIMACS Challenges and the ALENEX Workshops, and is past Editor in Chief of the ACM Journal on Experimental Algorithmics. She has written a book on experimental algorithmics and a book on AQC and quantum annealing.
With more than 6,200 employees in research, teaching and administration and its unique profile, TU Dortmund University shapes prospects for the future: The cooperation between engineering and natural sciences as well as social and cultural studies promotes both technological innovations and progress in knowledge and methodology. And it is not only the more than 34,600 students who benefit from that. The Faculty for Computer Science at TU Dortmund University, Germany, is looking for a Assistant Professor(W1) in Smart City Science specialize in research and teaching in the field of Smart City Science with methodological focus in computer science (e.g. machine learning and/or algorithm design) and applications in the area of Smart Cities (e.g. traffic prediction, intelligent routing, entertainment, e-government or privacy).
Applicants profile:
The TU Dortmund University aims at increasing the percentage of women in academic positions in the Department of Computer Science and strongly encourages women to apply. Disabled candidates with equal qualifications will be given preference.
more...

Peter Marwedel gives the opening talk "Cyber-Physical Systems: Opportunities, Challenges, and (Some) Solutions" at the 21. workshop on Synthesis And System Integration of Mixed Information technologies (SASIMI) in Matsue, Japan. He presents opportunities and challenges of the design of cyber-physical systems. He will additionally attend the panel "What is the next place to go, in the era of IoT and AI?".
14:15-14:30: Willi Sauerbrei (University of Freiburg, Germany):
Short introduction of the STRengthening Analytical Thinking for Observational Studies (STRATOS) initiative
The validity and practical utility of observational medical research depends critically on good study design, excellent data quality, appropriate statistical methods and accurate interpretation of results. Statistical methodology has seen substantial development in recent times, unfortunately often ignored in practice. Part of the underlying problem may be that even experts (whoever they are) do often not agree on potential advantages and disadvantages of competing approaches. Furthermore, many analyses are conducted by applied researchers with limited experience in statistical methodology and software. The lack of guidance on vital practical issues discourages them from using more appropriate methods. Consequently, analyses reported can be flawed, casting doubt on their results and conclusions.
The main aim of the international STRATOS initiative is to develop guidance for researchers with different levels of statistical knowledge. Currently there are nine topic groups on study design, initial data analysis, missing data, measurement error, variable and function selection, evaluating test and prediction models, causal inference, survival analysis, and high dimensional data. In addition, the initiative has ten crossing cutting panels. We will give a short introduction of the initiative. More information is available on the website (http://stratos-initiative.org) and in the first paper (Sauerbrei et al (2014), Statist Med 33: 5413-5432).
14:30-15:15: Lisa McShane (NIH, USA):
Analysis of high-dimensional Data: Opportunities and challenges
“Big data,” which refers to data sets that are large or complex, are being generated at an astounding pace in the biological and medical sciences. Examples include electronic health records and data generated by technologies such as omics assays which permit comprehensive molecular characterization of biological samples (e.g., genomics, transcriptomics, proteomics, epigenomics, and metabolomics), digital and molecular imaging technologies, and wearable devices with capability to collect real-time health status and health-related behaviors. Big data may be characterized by “large n” (number of independent observations or records) and/or “large p” (number of dimensions of a measurement or number of variables associated with each independent record). Either large n or p may present difficulties for data storage or computations, but large p presents several particularly interesting statistical challenges and opportunities and is the focus of High-dimensional Data Topic Group (TG9) within the STRATOS initiative.
Many types of high-dimensional data in the biomedical field (e.g., generated from omics assays or by imaging) require pre-processing prior to higher level analyses to correct for artifacts due to technical biases and batch effects. Statistical pre-processing methods may require modification, or novel approaches may be needed, as new technologies emerge. Visualization and exploration of data in high dimensions is also challenging, necessitating development of novel graphical methods, including approaches to integrate high-dimensional data of different types such as DNA mutation calls and expression levels of genes and protein. Additionally, data dimension reduction, for which many methods exist, may be needed for ease of interpretation or as an initial step before proceeding with downstream analyses such as prediction modeling.
Many discovery studies have as their goal identification of biological differences between groups of biological specimens, patients, or other research subjects. When those differences may occur in any of thousands of measured variables, standard approaches that control family- wise error (e.g., Bonferroni adjustment) are generally too stringent to be useful. The explosion of high-dimensional data has encouraged further development of approaches that control expected or actual false discovery number or proportions. Analysts need to appreciate what criteria these methods control and what assumptions are required.
Traditional classification and prediction methods may become computationally infeasible or unstable when the number of potential predictor variables is very large. Penalized regression methods and a variety of machine learning methods have been introduced into routine statistical practice to address these challenges. However, great care is needed to avoid overfitting models in high-dimensions. Methods such as cross-validation or other resampling methods can be used to provide realistic assessments of model performance and detect overfitting; frequent occurrence of overfit models based on high-dimensional data in the published literature suggests that more education is needed on proper model performance assessment.
More research to develop new approaches for analysis of high-dimensional data is clearly needed. Before adoption, performance of new methods should be adequately assessed on real and simulated data sets. Some methods previously developed for use on data of substantially lower dimension might also require reassessment to ensure that their acceptable performance is maintained in high dimensions. How to simulate realistic data in high dimensions is a research topic in itself.
Growth of big data is already outpacing the increase in the number of individuals knowledgeable in how to manage and analyze these data. The goal of the High-dimensional Data Topic Group (TG9) of STRATOS is to educate researchers, including statisticians, computational scientists and other subject matter experts, on proper design and analysis of studies reliant on high- dimensional data, and also to stimulate development of new and improved methods for application to big data. Success in meeting the demand for big data analytic methods will require unprecedented levels of collaboration among all parties engaging in big data-based research.
15:15-15:45 Tomasz Burzykowski (Hasselt University, Belgium)
A bird’s eye view on processing and statistical analysis of 'omics' data
Technologies used to collected experimental “omics” data share several important features: they use sophisticated instruments that involve complex physical and biochemical process; they are highly sensitive and can exhibit systematic effects due to time, place, reagents, personnel, etc.; they yield large amounts (up to millions) of measurements per single biological sample; they produce highly structured and complex data (in terms of correlation, variability, etc.). The features pose various practical challenges. For instance, sensitivity to systematic effects can compromise reproducibility of the findings if experiments are repeated in different laboratories. There are also challenges for the statistical analysis of the data. In the presentation we will provide an overview of and illustrate the common points that one may need to keep on mind when attempting to analyze an “omics” dataset.
15:45-16:00 Discussion and break
16:00-16:30 Riccardo de Bin (University of Oslo, Norway):
Strategies to derive combined prediction models using both clinical predictors and high- throughput molecular data
In biomedical literature, numerous prediction models for clinical outcomes have been developed based either on clinical data or, more recently, on high-throughput molecular data (omics data). Prediction models based on both types of data, however, are less common, although some recent studies suggest that a suitable combination of clinical and molecular information may lead to models with better predictive abilities. This is probably due to the fact that it is not straightforward to combine data with different characteristics and dimensions (poorly characterized high-dimensional omics data, well-investigated low-dimensional clinical data). Here we show some possible ways to combine clinical and omics data into a prediction model of time-to-event outcome. Different strategies and statistical methods are exploited.
16:30-17:00 Willi Sauerbrei (University of Freiburg, Germany):
Guidance for the selection of variables and functional form for continuous variables – Why and for whom?
During recent times, research questions have become more complex resulting in a tendency towards the development of new and even more complex statistical methods. Tremendous progress in methodology for clinical and epidemiological studies has been made, but has it reached researchers who analyze observational studies? Do experts (whoever they are) agree how to analyze a study and do they agree on potential advantages and disadvantages of competing approaches?
Multivariable regression models are widely used in all areas of science in which empirical data are analyzed. A key issue is the selection of important variables and the determination of the functional form for continuous variables. More than twenty variable selection strategies (each with several variations) are proposed and at least four approaches (assuming linearity, step functions (based on categorization), various types of spline based approaches and fractional polynomials) are popular to determine a functional form. In practice, many analysts are required de facto to make important modelling decisions. Are decisions based on good reasons? Why was a specific strategy chosen? What would constitute a ‘state-of-the-art’ analysis?
Considering such questions we will argue that guidance is needed for analysts with different levels of statistical knowledge, teachers and many other stakeholders in the research process. Guidance needs to be based on well designed and conducted studies comparing competing approaches. With the aim to provide accessible and accurate guidance for relevant topics in the design and analysis of observational studies the international STRengthening Analytical Thinking for Observational Studies (STRATOS) Initiative (http://stratos-initiative.org) was recently founded. More about issues mentioned is given in the short summary of topic group 2 ‘Selection of variables and functional forms in multivariable analysis’ in a paper introducing the initiative and its main aims (Sauerbrei et al (2014), Statist Med 33: 5413-5432).
17:00-17:15 Discussion

Intelligent fabrics, fitness wristbands, smartphones, cars, factories, and large scientific experiments are recording tremendous data streams. Machine Learning can harness these masses of data, but storing, communicating, and analysing them spends lots of energy. Therefore, small devices should send less, but more meaningful data to a central processor where additional analyses are performed.
more...

Germany ranks among the pioneers in the field of learning systems and Artificial Intelligence. The aim of the Plattform Lernende Systeme initiated by the Federal Ministry of Education and Research is to promote the shaping of Learning Systems for the benefit of individuals, society and the economy. Learning Systems will improve people’s quality of life, strengthen good work performance, secure growth and prosperity and promote the sustainability of the economy, transport systems and energy supply.
more...
Two independent publications from subproject B2 have been honored with a Best Paper Award at different conferences dealing with the automatic classification of nano-objects (e. g. viruses) in noisy sensor data. They provide a valuable contribution to the automatic analysis of medical probes using the PAMONO sensor.
The joint work "Real-Time Low SNR Signal Processing for Nanoparticle Analysis with Deep Neural Networks" of Jan Eric Lenssen, Anas Toma, Albert Seebold, Victoria Shpacovitch, Pascal Libuschewski, Frank Weichert, Jian-Jia Chen and Roland Hergenröder received the Best Paper Award of the BIOSIGNALS 2018.
The joint work "Unsupervised Data Analysis for Virus Detection with a Surface Plasmon Resonance Sensor" of Dominic Siedhoff, Martin Strauch, Victoria Shpacovitch and Dorit Merhof received the Best Paper Award of the IEEE International Conference on Image Processing Theory, Tools and Applications (IPTA) 2017. The approach was developed in cooperation with the Department of Image Processing, RWTH Aachen University.
Resource-Aware Cyber-Physical Systems Design
The heart of the software in many embedded systems contain one or more control algorithms. For example, a modern car contains several hundreds of millions of lines of software code implementing various control algorithms spanning across several domains like basic functionality (engine control, brake control), driver assistance (adaptive cruise control), safety (crash preparation systems) and comfort (vibration control). However, control algorithms have traditionally been designed to optimize stability and control performance metrics like settling time or peak overshoot.
The notions of efficiency that are prevalent in Computer Science - such as efficient utilization of computation, communication and memory resources - do not feature in the list of design criteria when designing control algorithms. This is in spite of the large volume of software code implementing control algorithms in many domains, as mentioned above.
It is only recently that the control theory community has focussed on designing control algorithms that efficiently utilize implementation platform resources. Such control algorithms turn out to be very different from those which were designed using approaches that were platform resource agnostic.
In this talk we will discuss how a "Computer Science approach" is important for designing control algorithms and how such an approach embodies the principles of what is today referred to as cyber-physical systems design.
Bio:
Samarjit Chakraborty is a Professor of Electrical Engineering at TU Munich in Germany, where he holds the Chair for Real-Time Computer Systems. From 2011 – 2016 he also led a research program on embedded systems for electric vehicles at the TUM CREATE Center for Electromobility in Singapore, where he also served as a Scientific Advisor. Prior to taking up his current position at TU Munich in 2008, he was an Assistant Professor of Computer Science at the National University of Singapore from 2003 - 2008. He obtained his Ph.D. in Electrical Engineering from ETH Zurich in 2003. His research interests include distributed embedded systems, hardware/software co-design, embedded control systems, energy storage systems, electromobility, and sensor network-based information processing for healthcare, smart-buildings and transportation. He was the General Chair of Embedded Systems Week (ESWeek) 2011, and the Program Chair of EMSOFT 2009 and SIES 2012, and regularly serves on the TPCs of various conferences on real-time and embedded systems. During 2013-2014, he also served on the Executive Committee of DAC, where he started a new track on Automotive Systems and Software along with Anthony Cooprider from the Ford Motor Company. He serves on the editorial boards of IEEE Transactions on Computers, ACM Transactions on Cyber-Physical Systems, Leibnitz Transactions on Embedded Systems, Design Automation of Embedded Systems and Springer's Lecture Notes on Electrical Engineering. For his Ph.D. thesis, he received the ETH Medal and the European Design and Automation Association's Outstanding Doctoral Dissertation Award in 2004. In addition, he has received Best Paper and Demo Awards at ISLPED, ICCD, RTCSA, ASP-DAC, EUC, Mobisys, and several Best Paper Award nominations at RTSS, EMSOFT, CODES+ISSS, ECRTS and DAC. In addition to funding from several governmental agencies, his work has also been supported by grants from General Motors, Intel, Google, BMW, Audi, Siemens and Bosch.

At the recent yearly anniversary celebration of the TU Dortmund University two members of the CRC 876 received awards for their research:
Andrea Bommert (photo left, project A3) received an award as best in class for her masters degree.
Dr. Claudia Köllmann (photo right, project C4) received a PhD award for her outstanding contribution with the topic Unimodal Spline Regression and Its Use in Various Applications with Single or Multiple Modes:
Research in the field of non-parametric shape constrained regression has been extensive and there is need for such methods in various application areas, since shape constraints can reflect prior knowledge about the underlying relationship. This thesis develops semi-parametric spline regression approaches to unimodal regression. However, the prior knowledge in different applications is also of increasing complexity and data shapes may vary from few to plenty of modes and from piecewise unimodal to accumulations of identically or diversely shaped unimodal functions. Thus, we also go beyond unimodal regression in this thesis and propose to capture multimodality by employing piecewise unimodal regression or deconvolution models based on unimodal peak shapes. More explicitly, this thesis proposes unimodal spline regression methods that make use of Bernstein-Schoenberg-splines and their shape preservation property.
To achieve unimodal and smooth solutions we use penalized splines, and extend the penalized spline approach towards penalizing against general parametric functions, instead of using just difference penalties. For tuning parameter selection under a unimodality constraint a restricted maximum likelihood and an alternative Bayesian approach for unimodal regression are developed. We compare the proposed methodologies to other common approaches in a simulation study and apply it to a dose-response data set.
All results suggest that the unimodality constraint or the combination of unimodality and a penalty can substantially improve estimation of the functional relationship. A common feature of the approaches to multimodal regression is that the response variable is modelled using several unimodal spline regressions. This thesis examines mixture models of unimodal regressions, piecewise unimodal regression and deconvolution models with identical or diverse unimodal peak shapes. The usefulness of these extensions of unimodal regression is demonstrated by applying them to data sets from three different application areas: marine biology, astroparticle physics and breath gas analysis. The proposed methodologies are implemented in the statistical software environment R and the implementations and their usage are explained in this thesis as well.
more...
How to program 1000 Robots?
Swarm robotics is a branch of collective robotics that studies decentralized solutions for the problem of coordinating large groups of robots. Robot swarms are envisioned for challenging scenarios characterized by large and hazardous environments that require adaptivity, resilience, and efficiency. Despite this ambitious vision, the major achievements in this field still consist of algorithms that tackle specific problem instances, and the performance of these algorithms strongly depends upon the context in which they are developed (i.e., hardware capabilities and assumptions on the environment). Given this state of affairs, reproducing results and comparing algorithms is difficult, thus hindering the development of swarm robotics as a whole. Buzz is a novel programming language for the development of complex swarm behaviors. It offers a small, but powerful set of primitive operations that enable the specification of behaviors both in a swarm-wide fashion, and from the point of view of an individual robot. Buzz offers the promise of letting a designer program thousands of robots in a manageable way.
Bio
Giovanni Beltrame obtained his Ph.D. in Computer Engineering from Politecnico di Milano, in 2006 after which he worked as microelectronics engineer at the European Space Agency on a number of projects spanning from radiation-tolerant systems to computer-aided design. In 2010 he moved to Montreal, Canada where he is currently Associate Professor at Polytechnique Montreal with the Computer and Software Engineering Department. Dr. Beltrame directs the MIST Lab, with more than 30 students and postdocs under his supervision. His research interests include modeling and design of embedded systems, artificial intelligence, and robotics. He is currently on sabbatical and a visiting professor at the University of Tübingen.
End-to-end learning on graphs with graph convolutional networks
Neural networks on graphs have gained renewed interest in the machine learning community. Recent results have shown that end-to-end trainable neural network models that operate directly on graphs can challenge well-established classical approaches, such as kernel-based methods or methods that rely on graph embeddings (e.g. DeepWalk). In this talk, I will motivate such an approach from an analogy to traditional convolutional neural networks and introduce our recent variant of graph convolutional networks (GCNs) that achieves promising results on a number of semi-supervised node classification tasks. I will further introduce two extensions to this basic framework, namely: graph auto-encoders and relational GCNs. While graph auto-encoders provide a novel way of approaching problems like link prediction and clustering, relational GCNs allow for efficient modeling of directed, relational graphs, such as knowledge bases (e.g. Freebase).
Short bio
Thomas Kipf is a second-year PhD student at the University of Amsterdam, advised by Prof. Max Welling. His research focuses on large-scale inference for structured data, including topics such as semi-supervised learning, reasoning, and multi-agent reinforcement learning. During his earlier studies in Physics, he has had exposure to a number of fields, and—after a short interlude in Neuroscience-related research at the Max Planck Institute for Brain Research—eventually developed a deep interest in machine learning and AI.

Jani Tiemann was awarded the "Best of the Best Papers"-Award for his latest submission to the International Conference on Indoor Positioning and Indoor Navigation (IPIN) in Sapporo, Japan. The paper "Scalable and Precise Multi-UAV Indoor Navigation using TDOA-based UWB Localization" describes a novel, radio-based, scalable, high-precision positioning algorithm. This contribution opens up new possibilities to deploy autonomous robots in scenarios such as logistics or emergency services. The jury particularly acknowledged the innovative new concept as well as the extensive experimental validation. The submission is an important contribution to the subproject A4 of the SFB 876 and the CPS.HUB/NRW.

Within a week two independent publications from subproject B4 have been honored with a Best Paper Award at different conferences.
The joint work "On Avoiding Traffic Jams with Dynamic Self-Organizing Trip Planning" of Thomas Liebig and Maurice Sotzny received the Best Paper Award of the International Conference on Spatial Information Theory (COSIT) 2017.
The joint work "LIMoSim: A Lightweight and Integrated Approach for Simulating Vehicular Mobility with OMNeT++" of Benjamin Sliwa, Johannes Pillmann, Fabian Eckermann and Christian Wietfeld received the Best Contribution Award of the OMNeT++ Community Summit 2017.
The article “Analysis of min-hashing for variant tolerant DNA read mapping” by Jens Quedenfeld (now at TU Munich) and Sven Rahmann has received the Best Paper Award at the Workshop of Algorithms in Bioinformatics (WABI) 2017, held in Cambridge, MA, USA, August 20-23, 2017.
The authors consider an important question, as DNA read mapping has become a ubiquitous task in bioinformatics. New technologies provide ever longer DNA reads (several thousand basepairs), although at comparatively high error rates (up to 15%), and the reference genome is increasingly not considered as a simple string over ACGT anymore, but as a complex object containing known genetic variants in the population. Conventional indexes based on exact seed matches, in particular the suffix array based FM index, struggle with these changing conditions, so other methods are being considered, and one such alternative is locality sensitive hashing. Here we examine the question whether including single nucleotide polymorphisms (SNPs) in a min-hashing index is beneficial. The answer depends on the population frequency of the SNP, and we analyze several models (from simple to complex) that provide precise answers to this question under various assumptions. Our results also provide sensitivity and specificity values for min-hashing based read mappers and may be used to understand dependencies between the parameters of such methods. This article may provide a theoretical foundation for a new generation of read mappers.
The article can be freely accessed in the WABI conference proceedings (Proceedings of the 17th International Workshop on Algorithms in Bioinformatics (WABI 2017), Russell Schwartz and Knut Reinert (Eds.), LIPICS Vol. 88).
This work is part of subproject C1 of the collaborative research center SFB 876.

Prof. Dr. Katharina Morik described challenges and approaches for the analysis of very large data sets and high-dimensional data in industrial applications. Overall 12 talks, both from academia and from industry, presented case studies of RapidMiner in industry.
The Industrial Data Science Conference attracted experts from various industries and focused on data science applications for all industries utilizing use cases, and best practices to foster the exchange of experience, discussions with peers and experts, and learning from presenters and other attendees. It was organised by RapidMiner, the SFB 876 and the CPS.hub at the Institute for Production Systems at the TU Dortmund University.
Ultra-Low-Power Wireless Communication Using IR-UWB
The connection of our daily life’s objects to the cloud according to the Internet-of- Things (IoT) vision is about to revolutionize the way to live. To enable this revolution, a massive deployment of sensor nodes is required with predictions announcing up to trillions of these nodes. Such a massive deployment is not environmentally and economically sustainable with current technologies. Some of the pitfalls lay in the wireless communications of IoT nodes whose power consumption needs to be optimized in order to enable operation on ambient energy harvesting without compromising the connectivity. Recent wireless solutions usually tackle the energy problem with low-duty cycled radios taking advantage of the ultra-low requirement on speed by the sensing application. However, key applications using audio/vision sensing or requiring low latency call for high data rates. Impulse-Radio Ultra-Wideband (IR-UWB) is considered as a promising solution for high data-rate, short range and low-power solution due to the duty-cycled nature of the signal as well as the potential for low-complexity and low-power transmitter (TX) architectures. These characteristics have been the driving force behind the development of the IEEE 802.15.4a standard covering data rates from 0.11 to 27.24Mbps. A mostly-digital UWB transmitter System-on-Chip (SoC) which was designed for ultra-low voltage in 28nm FDSOI CMOS compliant with the IEEE 802.15.4a standard.
Another connectivity challenge comes from the massive deployment of IoT nodes. To avoid the congestion of the RF spectrum, cognitive communications based on software- defined reconfigurable radio (SDR) architectures covering bands up to 6 GHz are needed for agile wireless communications. On the receiver (RX) side, these radios impose though requirement on the low-noise amplifier (LNA) over a wide frequency range. Reducing the supply voltage pushes devices from strong inversion to moderate inversion and that forward back biasing can be used to mitigate this trend and increase the design space. The impact of technology scaling on important RF figures of merit to highlight the ability of advanced 28nm FDSOI CMOS to trade speed for power. Then illustrate this ability at circuit level by looking at the optimum sizing of a noise cancelling ultra-low-voltage wideband LNA targeting the hot topic of SDR.
This talk will introduce the IR-UWB, SDR technology with use cases for IoT. The characteristics of the communication with potential for IR-UWB and SDRs will be explored.

On June 30th, 2017, professor Michael ten Hompel was awarded an honorary doctorate for his special scientific merits of logistics research. Ten Hompel is Director of the Chair of Materials Handling and Warehousing at TU Dortmund University as well as Manager of the Fraunhofer Institute for Material Flow and Logistics. The doctorate was awarded by the Hungarian University of Miskolc.

This is an exciting time for journalism. The rise of online media and computational journalism proposes new opportunities for investigation, presentation and distribution of news. One opportunity is collaborative data science-facilitated journalism: for the Panama Papers project, 2.6 Terabyte of offshore documents were analysed; the resulting stories caused global attention and investigations in 79 countries, and led to the resignation of several heads of state. Other opportunities arise from new formats such as Virtual Reality, Drone and Robot Journalism which offer completely new forms of storytelling. In addition to new opportunities, there are challenges that are proving critical in 2017. The role of social media on the distribution of information is controversial. Fake news and filter bubbles are blamed for political, social and economic unrest, and they have caused a crisis in trust in the news industry. In turn, scientists use methods from Machine Learning and Large Scale Graph Analysis to study their effects on society.
These topics will be discussed at the first workshop on DATA SCIENCE + JOURNALISM at KDD 2017 in Halifax, Canada. The workshop is organized collaboratively by scientists from SFB 876, Project A6, the university of Illinois and Bloomberg.
more...
The Industrial Data Science Conference gathers experts from various industries and focuses on data science applications in industry, use cases, and best practices to foster the exchange of experience, discussions with peers and experts, and learning from presenters and other attendees.
Digitization, the Internet of Things (IoT), the industrial internet, and Industry 4.0 technologies are transforming complete industries and allow the collection of enormous amounts of data of various types, including Big Data and Streaming Data, structured and unstructured data, text, image, audio, and sensor data. Data Science, Data Mining, Process Mining, Machine Learning, and Predictive Analytics offer the opportunity to generate enormous value and a competitive advantage. Typical use cases include demand forecasting, price forecasting, predictive maintenance, machine failure prediction and prevention, critical event prediction and prevention, product quality prediction, process optimization, mixture of ingredients optimization, and assembly plan predictions for new product designs in industries like automotive, aviation, energy, manufacturing, metal, etc.
Join your peers in the analytics community at IDS 2017 as we explore breakthrough research and innovative case studies that discuss how to best create value from your data using advanced analytics.
| Date | September 5th, 2017 |
| Location | TU Dortmund University |
| Web | RapidMiner IDS 2017 |

Runtime management for many core embedded systems: the PRiME approach
PRiME (Power-efficient, Reliable, Manycore Embedded Systems, http://www.prime-project.org) is a national research programme funded by UK EPSRC, which started in 2013. My talk will outline the key scientific challenges in energy efficiency and hardware reliability of many-core embedded systems which PRiME has addressed / is still addressing. I will describe the main theoretical and experimental advances achieved to date. This includes presentation of learning-based runtime algorithms and OpenCL based cross-layer framework for energy optimization.
Bio
Bashir M. Al-Hashimi (M’99-SM’01-F’09) is a Professor of Computer Engineering and Dean of the Faculty of Physical Sciences and Engineering at University of Southampton, UK.
He is ARM Professor of Computer Engineering and Co-Director of the ARM- ECS research centre. His research interests include methods, algorithms and design automation tools for energy efficient of embedded computing systems. He has published over 300 technical papers, authored or co-authored 5 books and has graduated 33 PhD students.
GPU and coprocessor use in analytic query processing - Why we have only just begun
The past several years have seen several initial efforts to speed up analytic DB query processing using coprocessors (GPUs mostly) [1]. But DBMSes are complex software systems, which have seen decades of spirited evolution and optimization on CPUs - and coprocessor proponents have found it very challenging to catch up. Thus, only last year was a system presented [2] which surpasses MonetDB-level performance on TPC-H queries. Yet, that system is still slow compared to the CPU state-of-the-art; and it has remained closed and unreleased - exemplifying two aspects of the challenges of putting coprocessors to use: The technical and the social/methodological.
Drawing inspiration from shortcomings of existing work (with GPUs), and from both technical and social aspects of leading projects (HyPer, VectorWise and MonetDB in its own way), we will lay out some of these challenges, none having been seriously tackled so far; argue for certain approaches (GPU-specific and otherwise) for addressing them; and if time allows, discuss potential benefits from the interplay of such approaches.
[1] Breß, Sebastian, et al. "GNU-accelerated database systems: Survey and open challenges." Transactions on Large-Scale Data-and Knowledge-Centered Systems XV. Springer Berlin Heidelberg, 2014. 1-35.
[2] Overtaking CPU DBMSes with a GPU in Whole-Query Analytic Processing with Parallelism-Friendly Execution Plan Optimization, Adnan Agbaria, David Minor, Natan Peterfreund, Eyal Rozenberg, and Ofer Rosenberg.
Probabilistic Program Induction = program synthesis + learning?
In this talk I will first give a brief overview of a recent line of work on program synthesis based on
typed lambda-calculi. I will then outline some research questions pertaining to the integration of program synthesis and learning and will also include some examples from some recent, thought-provoking contributions in machine learning.
Bio
Since 2006 Jakob Rehof holds a joint position as full professor of Computer Science at the University of Dortmund, where he is chair of Software Engineering, and as a director at the Fraunhofer Institute for Software and Systems Engineering (ISST) Dortmund.
Jakob Rehof studied Computer Science and Mathematics at the University of Copenhagen and got his Ph.D. in Computer Science at DIKU, Department of Computer Science, University of Copenhagen.
In 1997 Rehof was a visiting Researcher at the University of Stanford, CA, USA.
From 1998 until 2006 he was at Microsoft Research, Redmond, WA, USA.
Prior to all of the above he studied Classical Philology (Latin & Greek) and Philosophy at the University of Aarhus and the University of Copenhagen and was a DAAD scholar at the Eberhard-Karls University of Tübingen.
Complex Network Mining on Digital and Physical Information Artefacts
In the world of today, a variety of interaction data of humans, services and systems is generated, e.g., utilizing sensors and social media. This enables the observation and capture of digital and physical information artefacts at various levels in offline and online scenarios.
Then, data science provides for the means of sophisticated analysis of the collected information artefacts and emerging structures.
Targeting that, this talk focuses on data mining on complex networks and graph structures and presents exemplary methods and results in the context of real-world systems. Specifically, we focus on the grounding and analysis of behavior, interactions and complex structures emerging from heterogeneous data, and according modeling approaches.
Biography
Martin Atzmueller is assistant professor at Tilburg University as well as visiting professor at the Université Sorbonne Paris Cité.
He earned his habilitation (Dr. habil.) in 2013 at the University of Kassel, where he also was appointed as adjunct professor (Privatdozent).
He received his Ph.D. (Dr. rer. nat.) in Computer Science from the University of Würzburg in 2006. He studied Computer Science at the University of Texas at Austin (USA) and at the University of Wuerzburg where he completed his MSc in Computer Science.
Martin Atzmueller conducts fundamental and applied research at the nexus of Data Science, Network Analysis, Ubiquitous Social Media, the Internet of Things, and Big Data. In particular, his research focuses on how to successfully analyze and design information and knowledge processes in complex ubiquitous and social environments. This is implemented by developing according methods and approaches for augmenting human intelligence and to assist the involved actors in all their purposes, both online and in the physical world.
Algorithmic Symmetry Detection and Exploitation
Symmetry is a ubiquitous concept that can both be a blessing and a curse. Symmetry arises naturally in many computational problems and can for example be used for search space compression or pruning. I will talk about algorithmic techniques to find symmetries and application scenarios that exploit them.
Starting with an introduction to the framework that has been established as the de facto standard over the past decades, the talk will highlight the underlying central ideas. I will then discuss several recent results and developments from the area. On the one hand, these results reassert the effectiveness of symmetry detection tools, but, on the other hand, they also show the limitations of the framework that is currently applied in practice. Finally, I will focus on how the central algorithmic ideas find their applications in areas such as machine learning and static program analysis.
Bio
Since 2014, Pascal Schweitzer is a junior-professor for the complexity of discrete problems at RWTH Aachen University. Following doctoral studies at the Max-Planck Institute for Computer Science in Saarbrücken, he was first a post-doctoral researcher at the Australian National University and then a laureate of the European Post-Doctoral Institute for Mathematical Sciences. His research interests comprise a wide range of discrete mathematics, including algorithmic and structural graph and group theory, on-line algorithms, and certifying algorithms.
Real-Time Mobility Data Mining
Abstract:
We live on a digital era. Weather, communications and social interactions start, happen and/or are triggered on some sort of cloud – which represent the ultimate footprint of our existence. Consequently, millions of digital data interactions result from our daily activities. The challenge of transforming such sparse, noisy and incomplete sources of heterogeneous data into valuable information is huge. Nowadays, such information is key to keep up a high modernization pace across multiple industries. Transportation is not an exception.
One of the key insights on mobility data mining are GPS traces. Portable digital devices equipped with GPS antennas are ubiquitous sources of continuous information for location-based decision support systems. The availability of these traces on the human mobility patterns is growing explosively, as industrial players modernize their infrastructure, fleets as well as the planning/control of their operations. However, to mine this type of data possesses unique characteristics such as non-stationarity, recurrent drifts or high communication rate. These latest issues clearly disallow the application of traditional off-the-shelf Machine Learning frameworks to solve these problems.
In this presentation, we approach a series of Transportation problems. Solutions involve near-optimal decision support systems based on straightforward Machine Learning pipelines which can handle the particularities of these problems. The covered applications include Mass Transit Planning (e.g. buses and subways), Operations of On-Demand Transportation Networks (e.g. taxis and car-sharing) and Freeway Congestion Prediction and Categorization. Experimental results on real-world case studies of NORAM, EMEA and APAC illustrate the potential of the proposed methodologies.
Bio:
Dr. Luis Moreira-Matias received his Ms.c. degree in Informatics Engineering and Ph.d. degree in Machine Learning from the University of Porto, in 2009 and 2015, respectively. During his studies, he won an International Data Mining competition held during a Research Summer School at TU Dortmund (2012). Luis served in the Program Committee and/or as invited reviewer of multiple high-impact research venues such as KDD, AAAI, IEEE TKDE, ESWA, ECML/PKDD, IEEE ITSC, TRB and TRP-B, among others. Moreover, he encloses a record of successful real-world deployment of AI-based software products across EMEA and APAC.
Currently, he is Senior Researcher at NEC Laboratories Europe (Heidelberg, Germany), integrated in the Intelligent Transportation Systems group. His research interests include Machine Learning, Data Mining and Predictive Analytics in general applied to improve Urban Mobility. He was fortunate to author 30+ high-impact peer-reviewed publications on related topics.
How to Time a Black Hole: Time series Analysis for the Multi-Wavelength Future
Abstract:
Virtually all astronomical sources are variable on some time scale, making studies of variability across different wavelengths a major tool in pinning down the underlying physical processes. This is especially true for accretion onto compact objects such as black holes: “spectral-timing”, the simultaneous use of temporal and spectral information, has emerged as the key probe into strong gravity and accretion physics. The new telescopes currently starting operations or coming online in the coming years, including the Square Kilometre Array (SKA), the Large Synoptic Survey Telescope (LSST) and the Cherenkov Telescope Array (CTA), will open up the sky to transient searches, monitoring campaigns and time series studies with an unprecedented coverage and resolution. But at the same time, they collect extraordinarily large data sets of previously unknown complexity, motivating the necessity for new tools and statistical methods. In this talk, I will review the state-of-the-art of astronomical time series analysis, and discuss how recent developments in machine learning and statistics can help us study both black holes and other sources in ever greater detail. I will show possible future directions of research that will help us address the flood of multiwavelength time series data to come.
Bio:
Daniela Huppenkothen received a Bachelor Degree in Geosciences and Astrophysics from the Jacobs University in Bremen in 2008 and the M.Sc. and Ph.D. degrees from the University of Amsterdam in Astronomy and Astrophysics in 2010 and 2014 respectively. Since October 2016 she works as an James Arthur Postdoctoral Fellow at the New York University. Her interests are time series analysis in astronomy, astrostatistics, X-ray data analysis, and machine learning.
Sketching as a Tool for Geometric Problems
Abstract:
I will give an overview of the technique of sketching, or data dimensionality reduction, and its applications to fundamental geometric problems such as projection (regression) onto flats and more general objects, as well as low rank approximation and clustering applications.
Learning with Knowledge Graphs
In recent years a number of large-scale triple-oriented knowledge graphs have been generated. They are being used in research and in applications to support search, text understanding and question answering. Knowledge graphs pose new challenges for machine learning, and research groups have developed novel statistical models that can be used to compress knowledge graphs, to derive implicit facts, to detect errors, and to support the above mentioned applications. Some of the most successful statistical models are based on tensor decompositions that use latent representations of the involved generalized entities. In my talk I will introduce knowledge graphs and approaches to learning with knowledge graphs. I will discuss how knowledge graphs can be related to cognitive semantic memory, episodic memory and perception. Finally I will address the question if knowledge graphs and their statistical models might also provide insight into the brain's memory system.
Volker Tresp received a Diploma degree from the University of Goettingen, Germany, in 1984 and the M.Sc. and Ph.D. degrees from Yale University, New Haven, CT, in 1986 and 1989 respectively. Since 1989 he is the head of various research teams in machine learning at Siemens, Research and Technology. He filed more than 70 patent applications and was inventor of the year of Siemens in 1996. He has published more than 100 scientific articles and administered over 20 Ph.D. theses. The company Panoratio is a spin-off out of his team. His research focus in recent years has been „Machine Learning in Information Networks“ for modeling Knowledge Graphs, medical decision processes and sensor networks. He is the coordinator of one of the first nationally funded Big Data projects for the realization of „Precision Medicine“. Since 2011 he is also a Professor at the Ludwig Maximilian University of Munich where he teaches an annual course on Machine Learning.
At BTW 2017 in Stuttgart, Jens Teubner received the Best Paper Award for his Paper "Efficient Storage and Analysis of Genome Data in Databases". He developed this work together with the University Magdeburg, Bayer AG, and TU Berlin.
The paper discusses technique to store genome data efficiently in a relational database. This makes the flexibility and performance of modern relational database engines accessible to the analysis of genome data.
At the same day, Stefan Noll, a Master Student of Jens Teubner, received the Best Student Paper Award ath BTW 2017 in Stuttgart. His contribution "Energy Efficiency in Main Memory Databases" reports on the key results of his Master Thesis. The Master Thesis was prepared within the DBIS Group and in the context of the Collaborative Research Center SFB876, Project A2.
His paper shows how the energy efficiency of a database system can be improved by balancing the compute capacity of the system with the available main memory bandwidth. To this end, he proposes to use Dynamic Voltage and Frequency Scaling (DVFS) as well as the selective shutdown of individual cores.
Abstract: "Efficient Storage and Analysis of Genome Data in Databases"
Genome-analysis enables researchers to detect mutations within genomes and deduce their consequences. Researchers need reliable analysis platforms to ensure reproducible and comprehensive analysis results. Database systems provide vital support to implement the required sustainable procedures. Nevertheless, they are not used throughout the complete genome-analysis process, because (1) database systems suffer from high storage overhead for genome data and (2) they introduce overhead during domain-specific analysis. To overcome these limitations, we integrate genome-specific compression into database systems using a specialized database schema. Thus, we can reduce the storage overhead to 30%. Moreover, we can exploit genome-data characteristics during query processing allowing us to analyze real-world data sets up to five times faster than specialized analysis tools and eight times faster than a straightforward database approach.
Big data in machine learning is the future. But how to deal with data analysis and limited resources: Computational power, data distribution, energy or memory? From September 25th to 28th, TU Dortmund University, Germany, hosts the 4th summer school on resource-aware machine learning. Further information and online registration at: http://sfb876.tu-dortmund.de/SummerSchool2017
Topics of the lectures include: Machine learning on FPGAs, Deep Learning, Probabilistic Graphical Models and Ultra Low Power Learning.
Exercises help bringing the contents of the lectures to life. The PhyNode low power computation platform was developed at the collaborative research center SFB 876. It enables sensing and machine learning for transport and logistic scenarios. These devices provide the background for hands-on experiments with the nodes in the freshly built logistics test lab. Solve prediction tasks under very constrained resources and balance accuracy versus energy.
The summer school is open to advanced graduate, post-graduate students as well as industry professionals from across the globe, who are eager to learn about cutting edge techniques for machine learning with constrained resources.
Excellent students may apply for a student grant supporting travel and accommodation. Deadline for application is July 15th.
more...

The most recent B2-Project publication "Application of the PAMONO-sensor for Quantification of Microvesicles and Determination of Nano-particle Size Distribution" has been selected by the journal Sensors as the leading article for their current issue. The article is available via Open Access on the journals web site. The article was co-authored by Alexander Schramm, project leader of SFB-project C1.
Abstract
The PAMONO-sensor (plasmon assisted microscopy of nano-objects) demonstrated an ability to detect and quantify individual viruses and virus-like particles. However, another group of biological vesicles—microvesicles (100–1000 nm)—also attracts growing interest as biomarkers of different pathologies and needs development of novel techniques for characterization. This work shows the applicability of a PAMONO-sensor for selective detection of microvesicles in aquatic samples. The sensor permits comparison of relative concentrations of microvesicles between samples. We also study a possibility of repeated use of a sensor chip after elution of the microvesicle capturing layer. Moreover, we improve the detection features of the PAMONO-sensor. The detection process utilizes novel machine learning techniques on the sensor image data to estimate particle size distributions of nano-particles in polydisperse samples. Altogether, our findings expand analytical features and the application field of the PAMONO-sensor. They can also serve for a maturation of diagnostic tools based on the PAMONO-sensor platform.
more...
Learning over high dimensional data streams
High dimensional data streams are collected in many scientific projects, humanity research, business processes, social media and the Web.
The challenges of data stream mining are aggravated in high dimensional data, since we have to decide with one single look at the data also about the dimensions that are relevant for the data mining models.
In this talk we will discuss about learning over high dimensional
i) numerical and
ii) textual streams.
Although both cases refer to high dimensional data streams, in
(i) the feature space is fixed, that is, all dimensions are present at each timepoint, whereas in
(ii) the feature space is also evolving as new words show up and old words get out of use.
Bio
Eirini Ntoutsi is an Associate Professor of Intelligent Systems at the Faculty of Electrical Engineering and Computer Science, Leibniz University Hannover, since March 2016. Her research lies in the areas of Data Mining, Machine Learning and Data Science and can be summarized as learning over complex data and data streams.
Prior to joining LUH, she was a postdoctoral researcher at the Ludwig-Maximilians-University (LMU) in Munich, Germany under the supervision of Prof. Hans-Peter Kriegel. She joined LMU in 2010 with an Alexander von Humboldt Foundation fellowship.
She received her PhD in data mining from the University of Piraeus, Greece under the supervision of Prof. Yannis Theodoridis.
Scalable Algorithms for Extreme Multi-class and Multi-label Classifcation
In the era of big data, large-scale classification involving tens of thousand target categories is not uncommon these days. Also referred to as Extreme Classification, it has also been recently shown that the machine learning challenges arising in recommendation systems and web-advertising can be effectively addressed by reducing it to extreme multi-label classification. In this talk, I will discuss my two recent works which have been accepted at SDM 2016 and WSDM 2017, and present TerseSVM and DiSMEC algorithms for extreme multi-class and multi-label classification. The training process for these agorithms makes use of openMP based distributed architectures, thereby using thousands of cores for computation, and train models in a few hours which would otherwise take several weeks. The precision@k and nDCG@k results using DiSMEC improve by upto 10% on benchmark datasets over state-of-the-art methods such as SLEEC and FastXML, which are used by Microsoft in Bing Search. Furthermore, the model size is upto three orders of magnitutde smaller than that obtained by off-the-shelf solvers.
Bio
Rohit Babbar is currently a post-doc in the Empirical Inference group at Max-Planck Institute Tuebingen since October 2014. His work has primarily been focused around large-scale machine learning and Big data problems. His research interests also include optimization and deep learning. Before that, he finished his PhD from University of Grenoble in 2014.

The Fritz-Lampert-Award of the TRANSAID-foundation for cancer-suffering children of the year 2016 has been awarded to Alexander Schramm (C1), head of the pediatric-oncologic research lab at the University Clinic Essen. The german-russian research award recognises excellent researchers and their work in the field of pediatric hematology and oncology for fundamental and clinical research. The award has been handed over at the semi-annual meeting of the Gesellschaft für Pädiatrische Onkologie und Hämatologie (GPOH) in Frankfurt at the 8th of November.
Recognised was his work in the publication Mutational dynamics between primary and relapse neuroblastomas, published together with national and international researchers in the Nature Genetics Journal. Beside Prof. Dr. Schramm the two further C1 project leaders, Prof. Dr. Sven Rahmann and Dr. Sangkyun Lee, also contributed to the publication.
Major concern of doctors is the recurrence of tumors, often leading to worse treatment results. Novel data analysis techniques can focus on differences between primary (at diagnosis) and recurrent neuroblastoma cancer cell genetic profiles. Found genetic patterns provide a chance for upcoming, target-specific therapies.
A year with successful international exchanges is nearing its end.
This year, six of our SFB researchers were (or will be in the near future) between news, space and science. Amongst others, they were at Google, NASA, Stanford and the Wirtschaftswoche. While it was certainly not a walk in the park, it was definitely an experience and a great success.
Following the topical seminar visit by Luca Benini, Mojtaba Masoudinejad (A4) could visit his lab at the ETH Zurich complementing the SFB research on energy-efficient systems and energy harvesting. Already aroung the turn of the last year, Nils Kriege (A6) visited Universities at York and Nottingham covering graph mining topics. Kai Brügge (C3) will at the beginning of 2017 stay at the French Alternative Energies and Atomic Energy Commission (CEA) to port the concepts and algorithms of the project to the upcoming Cherenkov Telescope Array (CTA).
Elena Erdmann (A6) received a Google News Lab Fellowship and worked two months at the Wirtschaftswoche. She has developed both journalistic know-how and technical skills to drive innovation in digital and data journalism. Nico Piatkowski (A1) visited Stefano Ermon at Stanford University. Together they worked on techniques for scalable and exact inference in graphical models. He also made a detour to NASA, Netflix and Google. Last but not least, Martin Mladenov (A6/B4) got an internship at Google. Some people say this is more difficult than getting admitted to Stanford or Harvard. Who knows? But this year they accepted about 2% of applicants (1,600 people). What did he work on? We do not know it, but he visited Craig Boutilier, so very likely something related to making decisions under uncertainty.

In July Jian-Jia Chen has already been awarded the outstanding paper award 2016 of the ECRTS for the publication Partitioned Multiprocessor Fixed-Priority Scheduling of Sporadic Real-Time Tasks.
Now the next award, this time by the IEEE RTSS symposion, was awarded to Wen-Hung Huang, Maolin Yang and Jian-Jia Chen for the publication Resource-Oriented Partitioned Scheduling in Multiprocessor Systems: How to Partition and How to Share?
Abstract:
When concurrent real-time tasks have to access shared resources, to prevent race conditions, the synchronization and resource access must ensure mutual exclusion, e.g., by using semaphores. That is, no two concurrent accesses to one shared resource are in their critical sections at the same time. For uniprocessor systems, the priority ceiling protocol (PCP) has been widely accepted and supported in real-time operating systems. However, it is still arguable whether there exists a preferable approach for resource sharing in multiprocessor systems. In this paper, we show that the proposed resource-oriented partitioned scheduling using PCP combined with a reasonable allocation algorithm can achieve a non-trivial speedup factor guarantee. Specifically, we prove that our task mapping and resource allocation algorithm has a speedup factor 11-6 / ( m + 1) on a platform comprising m processors, where a task may request at most one shared resource and the number of requests on any resource by any single job is at most one. Our empirical investigations show that the proposed algorithm is highly efective in terms of task sets deemed schedulable.
more...
Opportunities and Challenges in Global Network Cameras
Millions of network cameras have been deployed. Many of these cameras provide publicly available data, continuously streaming live views of national parks, city halls, streets, highways, and shopping malls. A person may see multiple tourist attractions through these cameras, without leaving home. Researchers may observe the weather in different cities. Using the data, it is possible to observe natural disasters at a safe distance. News reporters may obtain instant views of an unfolding event. A spectator may watch a celebration parade from multiple locations using street cameras. Despite the many promising applications, the opportunities of using global network cameras for creating multimedia content have not been fully exploited. The opportunities also bring forth many challenges. Managing the large amount of data would require fundamentally new thinking. The data from network cameras are unstructured and have few metadata describing the content. Searching the relevant content would be a challenge. Because network cameras continuously produce data, processing must be able to handle the streaming data. This imposes stringent requirements of the performance. In this presentation, I will share the experience building a software system that aims to explore the opportunities using the data from global network cameras. This cloud-based system is designed for studying the worldwide phenomena using network cameras. It provides an event-based API (application programming interface) and is open to researchers to analyze the data for their studies. The cloud computing engine can scale in response to the needs of analysis programs.
Biography
Yung-Hsiang Lu is an associate professor in the School of Electrical and Computer Engineering and (by courtesy) the Department of Computer Science of Purdue University. He is an ACM distinguished scientist and ACM distinguished speaker. He is a member in the organizing committee of the IEEE Rebooting Computing Initiative. He is the lead organizer of Low-Power Image Recognition Challenge, the chair (2014-2016) of the Multimedia Communication Systems Interest Group in IEEE Multimedia Communications Technical Committee. He obtained the Ph.D. from the Department of Electrical Engineering at Stanford University and BSEE from National Taiwan University.
With more than 6,200 employees in research, teaching and administration and its unique profile, TU Dortmund University shapes prospects for the future: The cooperation between engineering and natural sciences as well as social and cultural studies promotes both technological innovations and progress in knowledge and methodology. And it is not only the more than 33,500 students who benefit from that.
The Faculty for Computer Science at TU Dortmund University, Germany, is looking for a
Research Assistant (m/f)
with a strong background in Machine Learning/Data Mining, to start at the next possible date and for the duration of up to three years.
Salary will be paid, in agreement with the lawful regulations of tariffs, according to salary group E13 TV-L resp. according to the provisional regulations of the TVÜ-L, if applicable. The position is a full time appointment; it is in principle suitable for part-time employment too. Duration of the contract will be based on the targeted qualification (e.g. PhD).
Profile:
The Department of Artificial Intelligence at Dortmund is a small team that is involved in international research on Machine Learning and Data Mining, and develops application-oriented theories as well as theoretically well-founded applications. We expect:
• The candidate must have a university master degree in computer science
• Motivation to push research forward
• Interest in exchanging ideas within the team and with international researchers
• Excellent software development skills
• Ability to supervise and motivate students
• Outstanding performance resulting in publications
Tasks:
Responsibilities include teaching (four hours per week, e.g. tutoring, project groups, supervision of students) and support of research on machine learning. Participation at the collaborative research center SFB 876 is expected.
We offer:
• Participation in an inspiring, highly motivated team
• Support in developing the candidate's specific scientific strengths and qualification
• Opportunity to obtain a Ph.D.
The TU Dortmund University aims at increasing the percentage of women in academic positions in the Department of Computer Science and strongly encourages women to apply.
Disabled candidates with equal qualifications will be given preference.
more...
On the Smoothness of Paging Algorithms
We study the smoothness of paging algorithms. How much can the number of page faults increase due to a perturbation of the request sequence? We call a paging algorithm smooth if the maximal increase in page faults is proportional to the number of changes in the request sequence. We also introduce quantitative smoothness notions that measure the smoothness of an algorithm.
We derive lower and upper bounds on the smoothness of deterministic and randomized demand-paging and competitive algorithms. Among strongly-competitive deterministic algorithms LRU matches the lower bound, while FIFO matches the upper bound.
Well-known randomized algorithms like Partition, Equitable, or Mark are shown not to be smooth. We introduce two new randomized algorithms, called Smoothed-LRU and LRU-Random. Smoothed-LRU allows to sacrifice competitiveness for smoothness, where the trade-off is controlled by a parameter. LRU-Random is at least as competitive as any deterministic algorithm while smoother.
This is joint work with Alejandro Salinger.
Bio
Jan Reineke is an Assistant Professor of Computer Science at Saarland University. He tries to understand what makes systems predictable, and applies his insights in the design of resource-efficient, timing-predictable microarchitectures for real-time systems. Besides design, he is interested in analysis, usually by abstract interpretation, with applications in static timing analysis, quantification of side-channel vulnerabilities, and shape analysis.
Customized OS support for data processing on modern hardware
For decades, data processing systems have found the generic interfaces and policies offered by the operating systems at odds with the need for efficient utilization of hardware resources. As a result, most engines circumvent the OS and manage hardware resources directly. With the growing complexity and heterogeneity of modern machines, data processing engines are now facing a steep increase in the complexity they must absorb to achieve good performance.
In this talk we will focus on the challege of running concurrent workloads in multi-programming execution environments, as systems' performance often suffers from resource interaction among multiple parallel jobs. In the light of recent advancements in operating system design, such as multi-kernels, we propose two key principles: the separation of compute and control planes on a multi-core machine, and customization of the compute plane as a light weight OS kernel tailored for data processing. I will present some of our design decisions, and how they help to improve the performance of workloads consisting of common graph algorithms and relational operators.
Short Bio:
Jana Giceva is a final year PhD student in the Systems Group at ETH Zurich, supervised by Gustavo Alonso, and co-advised by Timothy Roscoe. Her research interests revolve around systems running on modern hardware, with inclination towards engines for in-memory data processing and operating systems. During her PhD studies she has been exploring various cross-layer optimizations across the systems stack, touching aspects from both hardware/software and database/OS co-design. Some of these projects are part of industry collaboration with Oracle Labs. She received the European Google PhD Fellowship 2014 in Operating Systems.
Runtime Reconfigurable Computing - from Embedded to HPC
Today, FPGAs are virtually deployed in any application domain ranging from embedded systems all the way to HPC installations. While FPGAs are commonly used rather statically (basically as ASIC substitutes), this talk will focus on exploiting reprogrammability of FPGAs to improve performance, cost and the energy efficiency of a system.
For embedded systems and future Internet of things systems, it will be demonstrated how tiny FPGA fabrics can replace hardened functional blocks in, for example, an ARM A9 processor. Furthermore, a database acceleration system will be presented that uses runtime reconfiguration of FPGAs to compose query optimized dataflow processing engines. Finally, the talk will introduce the ECOSCALE project that aims at using FPGAs for exascale computing.
Bio
Dirk Koch is a lecturer in the Advanced Processor Technologies Group at the University of Manchester. His main research interest is on runtime reconfigurable systems based on FPGAs, embedded systems, computer architecture and VLSI. Dirk Koch leaded a research project at the University of Oslo, Norway which was targeting to make partial reconfiguration of FPGAs more accessible. Current research projects include database acceleration using FPGAs based on stream processing as well as reconfigurable instruction set extensions for CPUs.
Dirk Koch was a program co-chair of the FPL2012 conference and he is a program committee member of several further conferences including FCCM, FPT, DATE, ISCAS, HEART, SPL, RAW, and ReConFig. He is author of the book "Partial Reconfiguration on FPGAs" and co-editor of "FPGAs For Software Programmers". Dirk holds two patents, and he has (co-)authored 80 conference and journal publications.

In celebration of Prof. Dr. Moriks 60th birthday, the Festschrift ''Solving Large Scale Learning Tasks'' covers research areas and researchers Katharina Morik worked with. This Festschrift has now been published at the Springer series on Lecture Notes in Artificial Intelligence.
Official presentation of the Festschrift will be on 20th of October at auditorium E23 at Otto-Hahn-Str. 14 starting 16.15 o’clock.
Articles in this Festschrift volume provide challenges and solutions from theoreticians and practitioners on data preprocessing, modeling, learning and evaluation. Topics include data mining and machine learning algorithms, feature selection and creation, optimization as well as efficiency of energy and communication. Talks for the presentation of the Festschrift are: Bart Goethals: k-Morik: Mining Patterns to Classify Cartified Images of Katharina, Arno Siebes: Sharing Data with Guaranteed Privacy, Nico Piatkowski: Compressible Reparametrization of Time-Variant Linear Dynamical Systems and Marco Stolpe: Distributed Support Vector Machines: An Overview.
more...
In celebration of Prof. Dr. Moriks 60th birthday, the Festschrift ''Solving Large Scale Learning Tasks'' covers research areas and researchers Katharina Morik worked with.
Articles in this Festschrift volume provide challenges and solutions from theoreticians and practitioners on data preprocessing, modeling, learning and evaluation. Topics include data mining and machine learning algorithms, feature selection and creation, optimization as well as efficiency of energy and communication.
Bart Goethals: k-Morik: Mining Patterns to Classify Cartified Images of Katharina
When building traditional Bag of Visual Words (BOW) for image classification, the k-Means algorithm is usually used on a large set of high dimensional local descriptors to build a visual dictionary. However, it is very likely that, to find a good visual vocabulary, only a sub-part of the descriptor space of each visual word is truly relevant for a given classification problem. In this paper, we explore a novel framework for creating a visual dictionary based on Cartification and Pattern
Mining instead of the traditional k-Means algorithm. Preliminary experimental results on face images show that our method is able to successfully differentiate photos of Elisa Fromont, and Bart Goethals from Katharina Morik.
Arno Siebes: Sharing Data with Guaranteed Privacy
Big Data is both a curse and a blessing. A blessing because the unprecedented amount of detailed data allows for research in, e.g., social sciences and health on scales that were until recently unimaginable. A curse, e.g., because of the risk that such – often very private – data leaks out though hacks or by other means causing almost unlimited harm to the individual.
To neutralize the risks while maintaining the benefits, we should be able to randomize the data in such a way that the data at the individual level is random, while statistical models induced from the randomized data are indistinguishable from the same models induced from the original data.
In this paper we first analyse the risks in sharing micro data – as statisticians tend to call it – even if it is anonymized, discretized, grouped, and perturbed. Next we quasi-formalize the kind of randomization we are after and argue why it is safe to share such data. Unfortunately, it is not clear that such randomizations of data sets exist. We briefly discuss why, if they exist at all, will be hard to find. Next I explain why I think they do exist and can be constructed by showing that the code tables computed by, e.g., Krimp are already close to what we would like to achieve. Thus making privacy safe sharing of micro-data possible.
Nico Piatkowski: Compressible Reparametrization of Time-Variant Linear Dynamical Systems
Linear dynamical systems (LDS) are applied to model data from various domains—including physics, smart cities, medicine, biology, chemistry and social science—as stochastic dynamic process. Whenever the model dynamics are allowed to change over time, the number of parameters can easily exceed millions. Hence, an estimation of such time-variant dynamics on a relatively small—compared to the number of variables—training sample typically results in dense, overfitted models.
Existing regularization techniques are not able to exploit the temporal structure in the model parameters. We investigate a combined reparametrization and regularization approach which is designed to detect redundancies in the dynamics in order to leverage a new level of sparsity. On the basis of ordinary linear dynamical systems, the new model, called ST-LDS, is derived and a proximal parameter optimization procedure is presented. Differences to l1 -regularization-based approaches are discussed and an evaluation on synthetic data is conducted. The results show, that the larger the considered system, the more sparsity can be achieved, compared to plain l1 -regularization.
Marco Stolpe: Distributed Support Vector Machines: An Overview
Support Vector Machines (SVM) have a strong theoretical foundation and a wide variety of applications. However, the underlying optimization problems can be highly demanding in terms of runtime and memory consumption. With ever increasing usage of mobile and embed ded systems, energy becomes another limiting factor. Distributed versions of the SVM solve at least parts of the original problem on different networked nodes. Methods trying to reduce the overall running time and memory consumption usually run in high performance compute clusters, assuming high bandwidth connections and an unlimited amount of available energy. In contrast, pervasive systems consisting of battery-powered devices, like wireless sensor networks, usually require algorithms whose main focus is on the preservation of energy. This work elaborates on this distinction and gives an overview of various existing distributed SVM approaches developed in both kinds of scenarios.
![]()
In fall 2015, the Ruhr Astroparticle and Plasma Physics Center (RAPP center) was founded in order to combine research efforts within the fields of plasma- and particle-astrophysics in the Ruhr area. The three universities Ruhr-Universität Bochum, Technische Universität Dortmund and Universität Duisbug/Essen are located in a radius of 20 kilometers, enabling close collaboration between the universities.
The founding PIs include Prof. Wolfgang Rhode and Prof. Bernhard Spaan, who are also one of the project leaders of the SFB projects C3, respectively C5. During the Inauguration Workshop Katharina Morik gave an invited talk on the research impact of Data Mining for astroparticle physics.
In the RAPP center, about 80 researchers, from master’s level up to staff members, join forces to investigate fundamental physics questions and to break new ground by combining knowledge from the fields of plasma-, particle- and astrophysics.
more...

From 26th to 28th of September the annual meeting of the DFG-SPP 1736: Algorithms for BIG DATA will be held in Dortmund. SPP members of the TU Dortmund are Johannes Fischer, Oliver Koch and Petra Mutzel. The SFB 876 participates via invited talks of Katharina Morik and Sangkyun Lee.
Focus of the SPP:
Computer systems pervade all parts of human activity and acquire, process, and exchange data at a rapidly increasing pace. As a consequence, we live in a Big Data world where information is accumulating at an exponential rate and often the real problem has shifted from collecting enough data to dealing with its impetuous growth and abundance. In fact, we often face poor scale-up behavior from algorithms that have been designed based on models of computation that are no longer realistic for big data.
While it is getting more and more difficult to build faster processors, the hardware industry keeps on increasing the number of processors/cores per board or graphics card, and also invests into improved storage technologies. However, all these investments are in vain, if we lack algorithmic methods that are able to efficiently utilize additional processors or memory features.
more...
In domain adaptation, the goal is to find common ground between two, potentially differently distributed, data sets. By finding common concepts present in two sets of words pertaining to different domains, one could leverage the performance of a classifier for one domain for use on the other domain. We propose a solution to the domain adaptation task, by efficiently solving an optimization problem through Stochastic Gradient Descent. We provide update rules that allow us to run Stochastic Gradient Descent directly on a matrix manifold: the steps compel the solution to stay on the Stiefel manifold. This manifold encompasses projection matrices of word vectors onto low-dimensional latent feature representations, which allows us to interpret the results: the rotation magnitude of the word vector projection for a given word corresponds to the importance of that word towards making the adaptation. Beyond this interpretability benefit, experiments show that the Stiefel manifold method performs better than state-of-the-art methods.
Published at the European Conference for Machine Learning ECML 2016 by Christian Poelitz, Wouter Duivesteijn, Katharina Morik
more...
The Cherenkov Telescope Array (CTA) is the next generation ground-based gamma-ray observatory, aimed at improving the sensitivity of current-generation experiments by an order of magnitude and provide coverage over four decades of energy. The current design consists of two arrays, one in each hemisphere, composed by tens of imaging atmospheric Cherenkov telescopes of different sizes. I will present the current status of the project, focusing on the analysis and simulation work carried on to ensure the best achievable performance, as well as how to use muons for the array calibration.
Bio
I received my PhD in Italy working on simulation and analysis for a space-based gamma-ray instrument. As an IFAE postdoc, I am currently working in both MAGIC and CTA, but still dedicating part of my time to gamma-ray satellites. For CTA, I'm part of the Monte Carlo working group, analyzing the simulations of different possible array layouts, and muon simulations for the calibration of the Large Size Telescope (LST).
There is a vacant job as project assistent
Tasks:
Support the speaker from CRC876 Mrs. Prof. Katharina Morik and the executive office. You have to support carrying out colloquia, meetings, workshops, summer schools and public appearance. As well as control of the funding and staff contracts from all part projects.
Qualification:
Ideally you allready have
We offer:
For further information, on german, you can follow the link
more...
Toward zero-power sensing: a transient computing approach
Current and future IoT applications envision huge numbers of smart sensors in deploy-and-forget scenarii. We still design these smart sensing systems based on the assumption of significant energy storage availability, and working on low-power electronics to minimize the depletion rate of the stored energy. In this talk I will take a different perspective - I will look into designing smart sensing systems for operating exclusively from sporadically available environmental energy (zero-power sensing) and extremely limited energy storage. These "unusual" constraints open interesting new opportunities for innovation. I will give several examples of practical "transient computing" systems and I will outline future research and application challenges in this field.
Bio
Luca Benini is Full Professor at the University of Bologna. He also holds the chair of digital circuits and systems at ETHZ . He received a Ph.D. degree in electrical engineering from Stanford University in 1997.
Dr. Benini's research interests are in energy-efficient system design and Multi-Core SoC design. He is also active in the area of energy-efficient smart sensors and sensor networks for biomedical and ambient intelligence applications.
He has published more than 700 papers in peer-reviewed international journals and conferences, four books and several book chapters (h-index 86). He has been general chair and program chair of the Design Automation and Test in Europe Conference, the International Symposium on Low Power Electronics and Design, the Network on Chip Symposium. He is Associate Editor of the IEEE Transactions on Computer-Aided Design of Circuits and Systems the ACM Transactions on Embedded Computing Systems. He is a Fellow of the IEEE and a member of the Academia Europaea.
Analysing Big Data typically involves developing for or comparing to Hadoop. For researching new algorithms, a personal Hadoop cluster, running independently of other software or other Hadoop clusters, should provide a sealed environment for testing and benchmarking. Easy setup, resizing and stopping enables rapid prototyping on a containerized playground.
DockHa is a project developed at the Artificial Intelligence Group, TU Dortmund University, that aims to simplify and automate the setup of independent Hadoop clusters in the SFB 876 Docker Swarm cluster. The Hadoop properties and setup parameters can be modified to suit the application. More information can be found in the software section (DockHa) and the Bitbucket repository (DockHa-Repository).
more...
As part of the work for project B3 the survey on Opportunities and Challenges for Distributed Data Analysis has now been published by Marco Stolpe at ACM SIGKDD.
This survey motivates how the real-time analysis of data, embedded into the Internet of Things (IoT), enables entirely new kinds of sustainable applications in sectors such as manufacturing, transportation and distribution, energy and utilities, the public sector as well as in healthcare. It presents and discusses the challenges of real-time constraints for state-of-the-art analysis methods. Current research strongly focuses on cloud-based big data analysis. Our survey provides a more balanced view, taking also into account highly communication-constrained scenarios which require research on decentralized analysis algorithms. These must analyse data directly on sensors and small devices. Discussed is the vertical partitioning of data common for the IoT, which is particularly challenging, since information about observations is assessed at different networked nodes. The paper includes a comprehensive bibliography that should provide readers with a good starting point for their own work.
more...
The publication can now be found online. It compiles profiles of the most important players involved in Big Data in Germany:
60 technology providers (p. 55 ff LS11, LS8 of TU Dortmund Computer Sience), 40 cooperation partners and 30 research centers and institutions, including SFB 876 on p.47.
more...
Applications of Machine Learning: From Brain-Machine-Interfaces to Autonomous Driving
Machine learning methods have been established in many areas and produce better results for special fields than humans. Current developments like Deep Learning strengthen these trends. This presentation gives a short introduction to the state of the art of Machine Learning and shows a couple of examples where the Department of Computer Engineering, University of Tübingen, especially has its focus on. By means of Brain-Machine-Interfaces good results could be achieved regarding the rehabilitation of stroke patients. Another good example is the Brain-Machine-Interface being tested for adaptive learning systems. More challenges exist in the area of autonomous driving where for example the recognition of the state of the driver plays a key role to check if he or she is able to take back the control of the car in corresponding situations.
Bio
Professor Dr. Wolfgang Rosenstiel studied Informatics at the University of Karlsruhe. There he also received his Diploma in 1980 and his Ph.D. in 1984. From 1986 to 1990 he led the department “Automatization of Integrated Circuit Design” at the Research Center for Information Technology Karlsruhe (FZI Karlsruhe). Since 1990 he is Professor (Chair for Computer Engineering) at the Wilhelm-Schickard-Institute for Informatics at the University of Tübingen. Since 1st October 2010 he is Dean of the Faculty of Science. He was committee member of DFG senate for Collaborative Research Centers. He is editor-in-chief of the Springer journal „Design Automation for Embedded Systems“. He is active in numerous program and executive committees. He is member of GI, IEEE, IFIP 10.5 as well as ITRS-Design-Committee. In 2009 he received an ERC advanced research grant and he is DATE Fellow since 2008. In 2007 he received a Shared University Research Grant from IBM.
Deep Learning for Big Graph Data
Big data can often be represented as graphs. Examples include chemical compounds, communication and traffic networks, and knowledge graphs. Most existing machine learning methods such as graph kernels do not scale and require ad-hoc feature engineering. Inspired by the success of deep learning in the image and speech domains, we have developed neural representation learning approaches for graph data. We will present two approaches to graph representation learning. First, we present Patchy-SAN, a framework for learning convolutional neural networks (CNNs) for graphs. Similar to CNNs for images, the method efficiently constructs locally connected neighborhoods from the input graphs. These neighborhoods serve as the receptive fields of a convolutional architecture, allowing the framework to learn effective graph representations. Second, we will discuss a novel approach to learning knowledge base representations. Both frameworks learn representations of small and locally connected regions of the input graphs, generalize these to representations of more and more global regions, and finally embed the input graphs in a low-dimensional vector space. The resulting embeddings are successfully used in several classification and prediction tasks.
Bio
Mathias Niepert is a senior researcher at NEC Labs Europe in Heidelberg. From 2012-2015 he was a research associate at the University of Washington, Seattle, and from 2009-2012 also a member of the Data and Web Science Research Group at the University of Mannheim. Mathias was fortunate enough to win awards at international conferences such as UAI, IJCNLP, and ESWC. He was the principle investigator of a Google faculty and a bilateral DFG-NEH research award. His research interests include tractable machine learning, probabilistic graphical models, statistical relational learning, digital libraries and, more broadly, the large-scale extraction, integration, and analysis of structured data.
Sildes from Topical Seminar
The slides from Mathias Niepert's talk can be found here.
more...
Predictable Real-Time Computing in GPU-enabled Systems
Graphic processing units (GPUs) have seen wide-spread use in several computing domains as they have the power to enable orders of magnitude faster and more energy-efficient execution of many applications. Unfortunately, it is not straightforward to reliably adopt GPUs in many safety-critical embedded systems that require predictable real-time correctness, one of the most important tenets in certification required for such systems. A key example is the advanced automotive system where timeliness of computations is an essential requirement of correctness due to the interaction with the physical world. In this talk, I will describe several system-level and algorithmic challenges on ensuring predictable real-time correctness in GPU-enabled systems, as well as our recent research results on using suspension-based approaches to resolve some of the issues.
Bio
Cong Liu is currently a tenure-track assistant professor in the Department of Computer Science at the University of Texas at Dallas, after obtaining his Ph.D in Computer Science from the University of North Carolina at Chapel Hill in summer 2013. His current research focuses on Real-Time and Embedded Systems, Battery-Powered Cyber-Physical Systems, and Mobile and Cloud Computing. He is the author and co-author of over 50 papers in premier journals and conferences such as RTSS, ICCPS, ECRTS , RTAS, EMSOFT, ICNP, INFOCOM. He received the Best Student Paper Award at the 30th IEEE Real-Time Systems Symposium, the premier real-time and embedded systems conference; he also received the best papers award at the 17th RTCSA.
The Fundamental Theorem of Perfect Simulation
Perfect simulation algorithms give a method for sampling exactly from high dimensional distributions. With applications both in Bayesian and Frequentist Statistics, Computer Science approximation algorithms, and statistical physics, several protocols for creating such algorithms exist. In this talk I will explore the basic principle of probabilistic recursion that underlies these different algorithms, and show how the Fundamental Theorem of Perfect Simulation can be used as a tool for building more complex methods.
Academic Bio
Mark Huber received his Ph.D. in Operations Research from Cornell University working in the area of perfect simulation. After completing a two-year postdoc with Persi Diaconis at Stanford, he begin a stint at Duke, where he received an NSF Early Career Award. Huber then moved to the Department of Mathematical Sciences at Claremont McKenna College, where he is the Fletcher Jones Foundation Associate Professor of Mathematics and Statistics, and Robert S. Day Fellow. Currently he is also the chair of the department.
Reprocessing and analysis of high-throughput data to identify novel therapeutic non-coding targets in cancer
Genome-wide studies have shown that our genome is pervasively transcribed, producing a complex pool of coding and non-coding transcripts that shape the cancer transcriptome. Long non-coding RNAs or lncRNAs dominate the non-coding transcriptome and are emerging as key regulatory factors in human disease and development. Through re-analysis of RNA-sequencing data from 10000 cancer patients across 33 cancer types (The Cancer Genome Atlas), we define a PAN-cancer lncRNA landscape, revealing insights in cancer-specific lncRNAs with therapeutic and diagnostic potential.
Journalism students from the TU Dortmund University spoke during the media talk "Think Big" with various experts on the topic of "Big Data". In the series Prof. Kristian Kersting (projects A6 and B4), Prof. Christian Sohler (projects A2, A6 and C4), Prof. Katharina Morik (projects A1, B3 and C3) and Prof. Michael ten Hompel (project A4) were guests of the students at the TU Dortmund University. They discussed questions of large data collections, their analysis, forecasts on them and even more. The questions discussed were for example how data mining influenced our life, which conclusion is possible due to our social network on facebook or how data mining influenced the medicine. They also talked about the risks arising with data mining. Another topic was Industry 4.0, for example warehousing could be automated by seonsrs and data mining, on long-term there could be self-organizing systems. This format was created under the direction of journalism professor Michael Steinbrecher, whose research area also deals with the topic "Big Data".
Broadcast with Prof. Kristian Kersting
Broadcast with Prof. Christian Sohler
Broadcast with Prof. Katharina Morik
Broadcast with Prof. Michael ten Hompel
more...

Katharina Morik, speaker of the collaborative research center SFB 876, has been appointed as a new member of the North Rhine-Westphalian Academy of Sciences, Humanities and the Arts for the group Engineering and Economic Science. The academy puts its focus on fundamental research. It provides a platform for discussion via regular public events and bridges the gap between research, government and industry. The certficate of appointment will be granted at the yearly academy ceremony on 11th of March 2016.
By the appointment of Katharina Morik does the acadamy acknowledge her outstanding resarch profile, her achievements as speaker of the research center SFB 876 and her international reputation and research in machine learning.
When Bits meet Joules: A view from data center operations' perspective
The past decade has witnessed the rapid advancement and great success of information technologies. At the same time, new energy technologies including the smart grid and renewables have gained significant momentum. Now we are in a unique position to enable the two technologies to work together and spark new innovations.
In this talk, we will use data center as an example to illustrate the importance of the co-design of information technologies and new energy technologies. Specifically, we will focus on how to design cost-saving power management strategies for Internet data center operations. We will conclude the discussion with future work and directions.
Bio
Xue (Steve) Liu is a William Dawson Scholar and an Associate Professor in the School of Computer Science at McGill University. He received his Ph.D. in Computer Science (with multiple distinctions) from the University of Illinois at Urbana-Champaign. He has also worked as the Samuel R. Thompson Chaired Associate Professor in the University of Nebraska-Lincoln and at HP Labs in Palo Alto, California. His research interests are in computing systems and communication networks, cyber-physical systems, and smart energy technologies. His research appeared in top venues including Mobicom,S&P (Oakland), Infocom, ACM Multimedia, ICNP, RTSS, RTAS, ICCPS, KDD, ICDE etc, and received several best paper awards.
Dr. Liu's research has been reported by news media including the New York Times, IDG/Computer World, The Register, Business Insider, Huffington Post, CBC, NewScientist, MIT Technology Review's Blog etc. He is a recipient of the Outstanding Young Canadian Computer Science Researcher Prizes from the Canadian Association of Computer Science, and a recipient of the Tomlinson Scientist Award from McGill University.
He has served on the editorial boards of IEEE Transactions of Parallel and Distributed Systems (TPDS), IEEE Transactions on Vehicular Technology (TVT), and IEEE Communications Surveys and Tutorials (COMST).
Analysis and Optimization of Approximate Programs
Many modern applications (such as multimedia processing, machine learning, and big-data analytics) exhibit an inherent tradeoff between the accuracy of the results they produce and the execution time or energy consumption. These applications allow us to investigate new optimization approaches that exploit approximation opportunities at every level of the computing stack and therefore have the potential to provide savings beyond the reach of standard semantics-preserving program optimizations.
In this talk, I will describe a novel approximate optimization framework based on accuracy-aware program transformations. These transformations trade accuracy in return for improved performance, energy efficiency, and/or resilience. The optimization framework includes program analyses that characterize the accuracy of transformed programs and search techniques that navigate the tradeoff space induced by transformations to find approximate programs with profitable tradeoffs. I will particularly focus on how we (i) automatically generate computations that execute on approximate hardware platforms, while ensuring that they satisfy the developer's accuracy specifications and (ii) apply probabilistic reasoning to quantify uncertainty coming from inputs or caused by program transformations, and analyze the accuracy of approximate computations.
Bio
Sasa Misailovic graduated with a Ph.D. from MIT in 2015. He will start as an Assistant Professor in the Computer Science Department at the University of Illinois at Urbana-Champaign in Fall 2016. During this academic year he is visiting Software Reliability Lab at ETH Zurich. His research interests include programming languages, software engineering, and computer systems, with an emphasis on improving performance, energy efficiency, and resilience in the face of software errors and approximation opportunities.
Discovering Compositions
The goal of exploratory data analysis -- or, data mining -- is making sense of data. We develop theory and algorithms that help you understand your data better, with the lofty goal that this helps formulating (better) hypotheses. More in particular, our methods give detailed insight in how data is structured: characterising distributions in easily understandable terms, showing the most informative patterns, associations, correlations, etc.
My talk will consist of three parts. I will start by explaining what is a pattern composition. Simply put, databases often consist of parts, each best characterised by a different set of patterns. Young parents, for example, exhibit different buying behaviour than elderly couples. Both, however, buy bread and milk. A pattern composition jointly characterises the similarities and differences between such components of a database, without redundancy or noise, by including only patterns that are descriptive for the data, and assigning those patterns only to the relevant components of the data.
In the second part of my talk I will go into the more important question of how to discover the pattern composition of a database when all we have is just a single database that has not yet been split into parts. That is, we are after that partitioning of the data by which we can describe it most succinctly using a pattern composition.
In the third part I will make the connection to causal discovery, as in the end that is our real goal.
On March 7 the panel discussion on Big Data - Small devices has been held in New York. The video including presentations and discussion is now available online. The collaborative research center SFB 876 has been represented by Katharina Morik (Resource-Aware Data Science), Wolfgang Rhode (Science for Science) and Kristian Kersting (Not so Fast: Driving into (Mobile) Traffic Jams), while a as a local presenter Claudia Perlich (Dstillery) gave her view on big data analysis. The discussion itself was moderated by Tina Eliassi-Rad (Northeastern-University/Rutgers University). The event has been organized by the New York German Center for Research and Innovation and co-sponsored by Deutsche Forschungsgemeinschaft (DFG) and University Allicane UA Ruhr.
Graphs, Ellipsoids, and Balls-into-Bins: A linear-time algorithm for constructing linear-sized spectral sparsification
Spectral sparsification is the procedure of approximating a graph by a sparse graph such that many properties between these two graphs are preserved. Over the past decade, spectral sparsification has become a standard tool in speeding up runtimes of the algorithms for various combinatorial and learning problems.
In this talk I will present our recent work on constructing a linear-sized spectral sparsification in almost-linear time. In particular, I will discuss some interesting connections among graphs, ellipsoids, and balls-into-bins processes.
This is based on joint work with Yin Tat Lee (MIT). Part of the results appeared at FOCS'15.
On March 7th a panel discussion on topics of the SFB will be held at the German Embassy New York. The event is organized by the University Alliance UA Ruhr and the German Center for Research and Innovation. Speakers from the SFB are Katharina Morik, Wolfgang Rhode and Kristian Kersting. The group of presenters also includes Claudia Perlich, Dstillery New York, und is moderated by Tina Eliassi-Rad (Northeastern University, currently on leave from Rutgers University).
Topic:
The amount of digitally recorded information in today’s world is growing exponentially. Massive volumes of user-generated information from smart phones and social media are fueling this Big Data revolution. As data flows throughout every sector of our global economy, questions emerge from commercial, government, and non-profit organizations interested in the vast possibilities of this information. What is Big Data? How does it create value? How can we as digital consumers and producers personally benefit? While Big Data has the potential to transform how we live and work, others see it as an intrusion of their privacy. Data protection concerns aside, the mere task of analyzing and visualizing large, complex, often unstructured data will pose great challenges to future data scientists. We invite you to join us for an exciting discussion on the technological developments and sociological implications of this Big Data revolution.
more...
Kernel-based Machine Learning from Multiple Information Sources
In my talk I will introduce multiple kernel learning, a machine learning framework for integrating multiple types of representation into the learning process. Furthermore I will present an extension called multi-task multiple kernel learning, which can be used for effectively learning from multiple sources of information, even when the relations between the sources are completely unknown. The applicability of the methodology is illustrated by applications taken from the domains of visual object recognition and computational biology.
Bio
Since 2014 Marius Kloft is a junior professor of machine learning at the Department of Computer Science of Humboldt University of Berlin, where he is since 2015 also leading the Emmy-Noether research group on statistical learning from dependent data. Prior to joining HU Berlin he was a joint postdoctoral fellow at the Courant Institute of Mathematical Sciences and Memorial Sloan-Kettering Cancer Center, New York, working with Mehryar Mohri, Corinna Cortes, and Gunnar Rätsch. From 2007-2011, he was a PhD student in the machine learning program of TU Berlin, headed by Klaus-Robert Müller. He was co-advised by Gilles Blanchard and Peter L. Bartlett, whose learning theory group at UC Berkeley he visited from 10/2009 to 10/2010. In 2006, he received a diploma (MSc equivalent) in mathematics from the University of Marburg with a thesis in algebraic geometry.
Marius Kloft is interested in statistical machine learning methods for analysis of large amounts of data as well as applications, in particular, computational biology. Together with colleagues he has developed learning methods for integrating the information from multiple sensor types (multiple kernel learning) or multiple learning tasks (transfer learning), which have successfully been applied in various application domains, including network intrusion detection (REMIND system), visual image recognition (1st place at ImageCLEF Visual Object Recognition Challenge), computational personalized medicine (1st place at NCI-DREAM Drug Sensitivity Prediction Challenge), and computational genomics (most accurate gene start detector in international comparison of 19 leading models). For his research, Marius Kloft received the Google Most Influential Papers 2013 award.

From the 19th to the 20th of January, the "U.S.-German Workshop on the Internet of Things (IoT)/Cyber-Physical-System (CPS)" took place in Washington. The purpose of the workshop was the preparation of an intensified German-American collaboration in the subject area of the workshop. The workshop was organized by the American National Science Foundation (NSF), the Fraunhofer-Institute for Software in Kaiserslautern, Germany, and the CPS-VO. The CPS-VO organizes the CPS programs that are funded by the NSF. The workshop was well-cast with high-ranking lecturers. The first day was hosted at the German Embassy in Washington. On the second day, the workshop was conducted in Arlington, in close proximity to the National Science Foundation.
The workshop made it obvious that economy, research institutes and universities, both in the USA and in Germany, have high expectations of the potential that CPS- and IoT-Systems hold. The participants saw complementary strong points on both sides of the Atlantic. While the USA has its strong suit in the subject area of the Internet, Germany is especially strong in the fields of security and confidentiality from the American view point.
As one of three representatives of German universities, Prof. Peter Marwedel was invited to give a lecture. In his lecture he talked about the possibilities of CPS- and IoT-Systems but also emphasized the necessity to consider efficient resource usage and resource constraints during implementation. This is especially the case in applications with big data volumes and complex algorithms, he said as he referred to the collaborative research center SFB 876. Because of technical difficulties, the lecture was recorded again in an uninterrupted version.The video is available on Youtube.
The workshop also produced some opportunities to add aspects of resource efficiency and big data volumes to future consideration as subject areas.
more...

Nano-Tera.ch: Electronic Technology for Health Management
Electronic-health or E-health is a broad area of engineering that leverages transducer, circuit and systems technologies for applications to health management and lifestyle. Scientific challenges relate to the acquisition of accurate medical information from various forms of sensing inside/outside the body and to the processing of this information to support or actuate medical decisions. E-health systems must satisfy safety, security and dependability criteria and their deployment is critical because of the low-power and low-noise requirements of components interacting with human bodies. E-health is motivated by the social and economic goals of achieving better health care at lower costs and will revolutionize medical practice in the years to come. The Nano-Tera.ch program fosters the use of advance nano and info technologies for health and environment monitoring. Research issues in these domains within nano-Tera.ch will be shown as well as practical applications that can make a difference in everyday life.
Bio
Giovanni De Micheli is Professor and Director of the Institute of Electrical Engineering and of the Integrated Systems Centre at EPF Lausanne, Switzerland. He is program leader of the Nano-Tera.ch program. Previously, he was Professor of Electrical Engineering at Stanford University.He holds a Nuclear Engineer degree (Politecnico di Milano, 1979), a M.S. and a Ph.D. degree in Electrical Engineering and Computer Science (University of California at Berkeley, 1980 and 1983).
Prof. De Micheli is a Fellow of ACM and IEEE and a member of the Academia Europaea. His research interests include several aspects of design technologies for integrated circuits and systems, such as synthesis for emerging technologies, networks on chips and 3D integration. He is also interested in heterogeneous platform design including electrical components and biosensors, as well as in data processing of biomedical information. He is author of: Synthesis and Optimization of Digital Circuits, McGraw-Hill, 1994, co-author and/or co-editor of eight other books and of over 600 technical articles. His citation h-index is 85 according to Google Scholar. He is member of the Scientific Advisory Board of IMEC (Leuven, B), CfAED (Dresden, D) and STMicroelectronics.
Dr. Lee presented his recent research about proximal point algorithms to solve nonsmooth convex penalized regression problems, in the 8th International Conference on the ERCIM WG on Computational and Methodological Statistics (CMStatistics 2015), London UK, Dec 12-14 (http://www.cmstatistics.org/CMStatistics2015/), in the session EO150: Convex optimization in statistics. Dr. Lee was invited by the session organizer Prof. Keith Knight from Department of Statistics, University of Toronto.
Accelerated proximal point methods for solving penalized regression problems
Efficient optimization methods to obtain solutions of penalized regression problems, especially in high dimensions, have been studied quite extensively in recent years, with their successful applications in machine learning, image processing, compressed sensing, and bioinformatics, just to name a few. Amongst them, proximal point methods and their accelerated variants have been quite competitive in many cases. These algorithms make use of special structures of problems, e.g. smoothness and separability, endowed by the choices of loss functions and regularizers. We will discuss two types of first-order proximal point algorithms, namely accelerated proximal gradient descent and accelerated proximal extra gradient techniques, focusing on the latter, in the context of Lasso and generalized Dantzig selector.
On 8th of December Alexander Schramm becomes an adjunct professor. The faculty director of the medical faculty, Prof. Dr. Jan. Buer, award him for his work on the subject of "Experimental Oncology". So he can continue his research on molecular causes for development of tumors during the childhood, as a part of the CRC876.

The National Acadamy of Science and Engineering advises society and governments in all questions regarding the future of technology. Acatech is one of the most important academies for novel technology research. Additionally, acatech provides a platform for transfer of concepts to applications and enables the dialogue between science and industry. The members work together with external researchers in interdisciplinary projects to ensure the practiability of recent trends. Internationally oriented, acatech wants to provide solutions for global problems and new perspectives for technological value added in Germany.
By the appointment of Katharina Morik as member of acatech, the acadamy recognizes her research profile, her achievements as speaker of the collaborative research center SFB 876, her international reputation and innovative research in machine learning.
From Average Treatment Effects to Batch Learning from Bandit Feedback
Log data is one of the most ubiquitous forms of data available, as it can be recorded from a variety of systems (e.g., search engines, recommender systems, ad placement) at little cost. The interaction logs of such systems (e.g., an online newspaper) typically contain a record of the input to the system (e.g., features describing the user), the prediction made by the system (e.g., a recommended list of news articles) and the feedback (e.g., number of articles the user read). This feedback, however, provides only partial-information feedback -- aka ''contextual bandit feedback'' -- limited to the particular prediction shown by the system. This is fundamentally different from conventional supervised learning, where ''correct'' predictions (e.g., the best ranking of news articles for that user) together with a loss function provide full-information feedback.
In this talk, I will explore approaches and methods for batch learning from logged bandit feedback (BLBF). Unlike the well-explored problem of online learning with bandit feedback, batch learning with bandit feedback does not require interactive experimental control of the underlying system, but merely exploits log data collected in the past. The talk explores how Empirical Risk Minimization can be used for BLBF, the suitability of various counterfactual risk estimators in this context, and a new learning method for structured output prediction in the BLBF setting. From this, I will draw connections to methods for causal inference in Statistics and Economics.
Joint work with Adith Swaminathan.
Bio
Thorsten Joachims is a Professor in the Department of Computer Science and the Department of Information Science at Cornell University. His research interests center on a synthesis of theory and system building in machine learning, with applications in information access, language technology, and recommendation. His past research focused on support vector machines, text classification, structured output prediction, convex optimization, learning to rank, learning with preferences, and learning from implicit feedback. In 2001, he finished his dissertation advised by Prof. Katharina Morik at the University of Dortmund. From 1994 to 1996 he was a visiting scholar with Prof. Tom Mitchell at Carnegie Mellon University. He is an ACM Fellow, AAAI Fellow, and Humboldt Fellow.
Waiting Time Models for Mutual Exclusivity and Order Constraints in Cancer Progression
In recent years, high-throughput sequencing technologies have generated an unprecedented amount of genomic cancer data, opening the way to a more profound understanding of tumorigenesis. In this regard, two fundamental questions have emerged: 1) which alterations drive tumor progression? and 2) what are the evolutionary constraints on the order in which these alterations occur? Answering these questions is crucial for targeted therapeutic decisions, which are often based on the identification of early genetic events. During this talk, I will present two models, TiMEx: a waiting time model for mutually exclusive cancer alterations, and pathTiMEx: a waiting time model for the joint inference of mutually exclusive cancer pathways and their dependencies in tumor progression. We regard tumorigenesis as a dynamic process, and base our model on the temporal interplay between the waiting times to alterations, characteristic for every gene and alteration type, and the observation time. We assume that, in tumor development, alterations can either occur independently, or depend on eachother by being part of the same pathway or by following particular progression paths. By inferring these two types of potential dependencies simultaneously, we jointly addresses the two fundamental questions of identifying important cancer genes and progression, on the basis of the same cancer dataset. On biological cancer datasets, TiMEx identifies gene groups with stronger functional biological relevance than previous methods, while also proposing many new candidates for biological validation. Additionally, the results of pathTiMEx on tumor progression are highly consistent with the literature in the case of colorectal cancer and glioblastoma.
Bio
Simona Constantinescu is a graduate student at ETH Zurich, in Switzerland, in Niko Beerenwinkel's group. Her main research interest is the design of models and algorithms with application to cancer genomics data. Particularly, she is working on projects related to inferring the temporal progression and mutual exclusivity in cancer, evolutionary dynamics of cancer, and toxicogenomics. Simona obtained a Master's Degree in Computational Biology and Bioinformatics (Department of Computer Science) from ETH Zurich, and degrees in Mathematics and Economic Informatics from the University of Bucharest. During her Master studies, she was awarded an ETH Excellence Scholarship.
Significant Pattern Mining
Pattern Mining is steadily gaining importance in the life sciences: Fields like Systems Biology, Genetics, or Personalized Medicine try to find patterns, that is combinations of (binary) features, that are associated with the class membership of an individual, e.g. whether the person will respond to a particular medical treatment or not.
Finding such combinations is both a computational and a statistical challenge. The computational challenge arises from the fact that a large space of candidate combinations has to be explored. The statistical challenge is due to each of these candidates representing
one hypothesis that is to be tested, resulting in an enormous multiple testing problem. While there has been substantial effort in making the search more efficient, the multiple testing problem was deemed intractable for many years. Only recently, new results started to emerge in data mining, which promise to lead to solutions for this multiple testing problem and to important applications in the biomedical domain. In our talk, we will present these recent results, including our own work in this direction.
Bio
Prof. Dr. Karsten Borgwardt is Professor of Data Mining at ETH Zürich, at the Department of Biosystems located in Basel. His work has won several awards, including the NIPS 2009 Outstanding Paper Award, the Krupp Award for Young Professors 2013 and a Starting Grant 2014 from the ERC-backup scheme of the Swiss National Science Foundation. Since 2013, he is heading the Marie Curie Initial Training Network for "Machine Learning for Personalized Medicine" with 12 partner labs in 8 countries. The business magazine "Capital" lists him as one of the "Top 40 under 40" in Science in/from Germany.
Whole Systems Energy Transparency (or: More Power to Software Developers!)
Energy efficiency is now a major (if not the major) concern in electronic systems engineering. While hardware can be designed to save a modest amount of energy, the potential for savings are far greater at the higher levels of abstraction in the system stack. The greatest savings are expected from energy consumption-aware software. This talk emphasizes the importance of energy transparency from hardware to software as a foundation for energy-aware system design. Energy transparency enables a deeper understanding of how algorithms and coding impact on the energy consumption of a computation when executed on hardware. It is a key prerequisite for informed design space exploration and helps system designers to find the optimal tradeoff between performance, accuracy and energy consumption of a computation. Promoting energy efficiency to a first class software design goal is therefore an urgent research challenge. In this talk I will outline the first steps towards giving "more power" to software developers. We will cover energy monitoring of software, energy modelling at different abstraction levels, including insights into how data affects the energy consumption of a computation, and static analysis techniques for energy consumption estimation.
Bio
Kerstin Eder is a Reader in Design Automation and Verification at the Department of Computer Science of the University of Bristol. She set up the Energy Aware COmputing (EACO) initiative (http://www.cs.bris.ac.uk/Research/eaco/) and leads the Verification and Validation for Safety in Robots research theme at the Bristol Robotics Laboratory (http://www.brl.ac.uk/vv).
Her research is focused on specification, verification and analysis techniques which allow engineers to design a system and to verify/explore its behaviour in terms of functional correctness, performance and energy efficiency. Kerstin has gained extensive expertise in verifying complex microelectronic designs at leading semiconductor design and EDA companies. She seeks novel combinations of formal verification and analysis methods with state-of-the-art simulation/test-based approaches to achieve solutions that make a difference in practice.
Her most recent work includes Coverage-Driven Verification for robots that directly interact with humans, using assertion checks and theorem proving to verify control system designs, energy modelling of software and static analysis to predict the energy consumption of programs. She is particularly interested in safety assurance for learning machines and in software design for low power.
Kerstin has co-authored over 50 internationally refereed publications, was awarded a Royal Academy of Engineering "Excellence in Engineering" prize and manages a portfolio of active research grants valued in excess of £1.7M.
She is currently Principal Investigator on the EPSRC projects "Robust Integrated Verification of Autonomous Systems" and "Trustworthy Robotic Assistants". She also leads the Bristol team working on the EC-funded Future and Emerging Technologies MINECC (Minimizing Energy Consumption of Computing to the Limit) collaborative research project ENTRA (Whole Systems Energy Transparency) which aims to promote energy efficiency to a first class software design goal.
Kerstin holds a PhD in Computational Logic, an MSc in Artificial Intelligence and an MEng in Informatics.
After a successful first edition in polish Warsaw the second workshop on "Algorithmic Challenges of Big Data" (short: ACBD) took place on September 28-30, which was organized by SFB876 and the department of computer science. ACBD focused on information compression/extraction, ressource efficient algorithms, distributed and parallel computing, sublinear algorithms and other question arising in modern data analysis.


Cache-Efficient Aggregation: Hashing Is Sorting
Abstract: For decades researchers have studied the duality of hashing and sorting for the implementation of the relational operators, especially for efficient aggregation. Depending on the underlying hardware and software architecture, the specifically implemented algorithms, and the data sets used in the experiments, different authors came to different conclusions about which is the better approach. In this paper we argue that in terms of cache efficiency, the two paradigms
are actually the same. We support our claim by showing that the complexity of hashing is the same as the complexity of sorting in the external memory model. Furthermore we make the similarity of the two approaches obvious by designing an algorithmic framework that allows to switch seamlessly between hashing and sorting during execution. The fact that we mix hashing and sorting routines in the same algorithmic framework allows us to leverage the advantages of both approaches and makes their similarity obvious. On a more practical note, we also show how to achieve very low constant factors by tuning both the hashing and the sorting routines to modern hardware. Since we observe a complementary dependency of the constant factors of the two routines to the locality of the input, we exploit our framework to switch to the
faster routine where appropriate. The result is a novel relational aggregation algorithm that is cache-efficient---independently and without prior knowledge of input skew and output cardinality---, highly parallelizable on modern multi-core systems, and operating at a speed close to the memory bandwidth, thus outperforming the state-of-the-art by up to 3.7x.
Wen-Hung Huang and Jian-Jia Chen (B2 SFB project) received the Best Paper Award of IEEE Real-Time Computing Systems and Applications. (RTCSA) Aug 19, 2015 - Aug 21, 2015, Hong Kong. The awarded paper is "Techniques for Schedulability Analysis in Mode Change Systems under Fixed-Priority Scheduling”. The paper explores a very essential scheduling property in cyber-physical systems when the execution time, relative deadline, and period of sampling can change over time according to different physical conditions. We conclude a 58.57% utilization bound for a very dynamic environment under mode-level fixed-priority scheduling.
Abstract: With the advent of cyber-physical systems, realtime tasks shall be run in different modes over time to react to the change of the physical environment. It is preferable to adopt high expressive models in real-time systems. In the light of simple implementation in kernels, fixed-priority scheduling has been widely adopted in commercial real-time systems. In this work we derive a technique for analyzing schedulability of the system where tasks can undergo mode change under fixed-priority scheduling. We study two types of fixed-priority scheduling in mode change systems: task-level and mode-level fixed-priority scheduling. The proposed tests run in polynomial time. We further show that a utilization of 58.57% can be guaranteed in implicit-deadline multi-mode systems if each mode is prioritized according to rate-monotonic policy. The effectiveness of the proposed tests is also shown via extensive simulation results.

As part of the ECML PKDD, in cooperation with the SFB 876, a summer school was hosted in Porto this year. For further information click here.
The Paper Online Analysis of High-Volume Data Streams in Astroparticle Physics has won the Best industrial paper award of the ECML-PKDD 2015.
On thursday the 10th of September will the paper be presented in a special session at the ECML-PKDD in Porto.
The 2nd Workshop on Algorithmic Challenges of Big Data (ACBD 2015)
September 28-30, 2015 in Dortmund, Germany
The Department of Computer Science and the SFB876 are excited to announce the second workshop on Algorithmic Challenges of Big Data. ACBD is focused on information compression/extraction, ressource efficient algorithms, distributed and parallel computing, sublinear algorithms, machine learning, and other question arising in modern data analysis.
ACBD 2015 will include invited presentations from leading researches in the field, as well as a forum for discussions.
Registration
To register, please send an email to acbd-info@ls2.cs.tu-dortmund.de. The registration deadline is September 15th. There is no registration fee.
Stephen Alstrup (University of Copenhagen)
Hannah Bast (University of Freiburg)
Jarek Byrka (University of Wroclaw)
Ioannis Caragiannis (University of Patras)
Graham Cormode (University of Warwick)
Artur Czumaj (University of Warwick)
Ilias Diakonikolas (University of Edinburgh)
Guy Even (Tel-Aviv University)
Pierre Fraigniaud (CNRS and University Paris Diderot)
Fabrizio Grandoni (IDSIA)
Giuseppe F. Italiano (University of Rome “Tor Vergata”)
Robert Krauthgamer (The Weizmann Institute of Science)
Stefano Leonardi (University of Rome “Sapienza”)
Yishay Mansour (Microsoft Research and Tel-Aviv University)
Alberto Marchetti-Spaccamela (University of Rome “Sapienza”)
Kurt Mehlhorn (Max Planck Institute for Computer Science)
Friedhelm Meyer auf der Heide (University of Paderborn)
Ulrich Meyer (Goethe University Frankfurt am Main)
Adi Rosen (CNRS and Universite Paris Diderot)
Piotr Sankowski (University of Warsaw)
Ola Svensson (EPFL)
Dorothea Wagner (Karlsruhe Institute of Technology)
TU Dortmund
Otto Hahn Straße 14, 44227 Dortmund, Germany
Christian Sohler
Alexander Munteanu
Chris Schwiegelshohn
For further information, please contact us under
acbd-info@ls2.cs.tu-dortmund.de
more...
In Learning with Label Proportions (LLP), the objective is to learn a supervised classifier when, instead of labels, only label proportions for bags of observations are known. This setting has broad practical relevance, in particular for privacy preserving data processing. We first show that the mean operator, a statistic which aggregates all labels, is sufficient for the minimization of many proper losses with linear classifiers without using labels. We provide a fast learning algorithm that estimates the mean operator via a manifold regularizer with guaranteed approximation bounds. Experiments display that our algorithms outperform the state-of-the-art in LLP, and in many cases compete with the Oracle, that learns knowing all labels. In more recent work, we show that the mean operator’s trick can be generalized, such that it is possible to learn without knowing individual feature vectors either. We can leverage this surprising result to design learning algorithms that do not need any individual example -only their aggregates- for training and for which many privacy guarantees can be proven.
Bio: Giorgio Patrini is a PhD student in Machine Learning at the Australian National University/NICTA. His main research is on understanding how learning is possible when some variables are only known as aggregates; for example, how to learn individual-level models from census-like data. His research naturally touches themes in social sciences, econometrics and privacy. He cofounded and advises Waynaut, an online travel start-up based in Milan, Italy.
Huge progress on understanding neuroblastoma tumors
Treatment of children with cancer has seen a lot of improvements in recent years. Major concern of doctors is the recurrence of tumors, often leading to worse treatment results. Researchers of the collaborative research center together with national and international colleagues now investigated differences in the genetic expressions of tumors in several different stadiums.
A current model of tumorigenesis implies that a collection of cascaded mutational events occur and that it therefore is critical to identify relevant events to better understand mechanisms underlying disease progression. For discovery, integrated analysis of high dimensional data is a key technology, which is however very challenging because of computational and statistical issues. In our work, we developed and applied an integrated data analysis technique, focusing on differences between primary (at diagnosis) and recurrent neuroblastoma cancer patients, profiled with whole-exome sequencing, mRNA expression, array CGH and DNA methylation data. Our analysis discovered characteristics of evolutionary dynamics in neuroblastoma, along with new mutational changes in relapse patients. Our results showed that this type of analysis is a promising approach to detect genetic and epigenetic changes in cancer evolution.
Research on this topic has been funded by the Deutsche Forschungsgemeinschaft (DFG) and supported by the Deutsche Konsortium für translationale Krebsforschung (DKTK) and the Mercator Research Center Ruhr (MERCUR).
An interview with a project leader, Sangkyun Lee, has been published on the TU Dortmund homepage.
more...
On 22 and 23 September the 6th Symposium "Metabolites in Process Exhaust Air and Breath Air" will take place at Reutlingen University. It is a joint event with SFB 876, the new Center of Breath Research at the University of Saarland and the B&S Analytik Dortmund. Participation is free. Prior registration is mandatory and possible until 1st august. More details can be found here.
This year the open access journal of metabolism and metabolomics Metabolites announced the recipients of the first Metabolites Best Paper Award for 2015. Paper submitted by Anne-Christin Hauschild, Dominik Kopczynski, Marianna D’Addario, Jörg Ingo Baumbach, Sven Rahmann and Jan Baumbach titled "Peak Detection Method Evaluation for Ion Mobility Spectrometry by Using Machine Learning Approaches" won this price. Supported by SFB876 and DFG it was published in Metabolites in 2013 and can be found here.
more...
Apache Flink and the Berlin Big Data Center
Data management research, systems, and technologies have drastically improved the availability of data analysis capabilities, particularly for non-experts, due in part to low-entry barriers and reduced ownership costs (e.g., for data management infrastructures and applications). Major reasons for the widespread success of database systems and today’s multi-billion dollar data management market include data independence, separating physical representation and storage from the actual information, and declarative languages, separating the program specification from its intended execution environment. In contrast, today’s big data solutions do not offer data independence and declarative specification.
As a result, big data technologies are mostly employed in newly-established companies with IT-savvy employees or in large well-established companies with big IT departments. We argue that current big data solutions will continue to fall short of widespread adoption, due to usability problems, despite the fact that in-situ data analytics technologies achieve a good degree of schema independence. In particular, we consider the lack of a declarative specification to be a major road-block, contributing to the scarcity in available data scientists available and limiting the application of big data to the IT-savvy industries. In particular, data scientists currently have to spend a lot of time on tuning their data analysis programs for specific data characteristics and a specific execution environment.
We believe that computer science research needs to bring forward the powerful concepts of declarative specification, query optimization and automatic parallelization as well as adaption to novel hardware, data characteristics and workload to current data analysis systems, in order to achieve the broad big data technology adoption and effectively deliver the promise that novel big data technologies offer. We will present the technologies that we have researched and developed in the context of Apache Flink (http://flink.apache.org ) and will give an outlook on further research and development that we are conducting at Database Systems and Information Management Group (DIMA) at TU Berlin and the Berlin Big Data Center (http://bbdc.berlin , http://www.dima.tu-berlin.de) as well as some current research challenges.
Bio
Volker Markl is a Full Professor and Chair of the Database Systems and Information Management (DIMA) group at the Technische Universität Berlin (TU Berlin). Volker also holds a position as an adjunct full professor at the University of Toronto and is director of the research group “Intelligent Analysis of Mass Data” at DFKI, the German Research Center for Artificial Intelligence. Earlier in his career, Dr. Markl lead a research group at FORWISS, the Bavarian Research Center for Knowledge-based Systems in Munich, Germany, and was a Research Staff member & Project Leader at the IBM Almaden Research Center in San Jose, California, USA. His research interests include: new hardware architectures for information management, scalable processing and optimization of declarative data analysis programs, and scalable data science, including graph and text mining, and scalable machine learning. Volker Markl has presented over 200 invited talks in numerous industrial settings and at major conferences and research institutions worldwide.
He has authored and published more than 100 research papers at world-class scientific venues. Volker regularly serves as member and chair for program committees of major international database conferences. He has been a member of the computer science evaluation group of the Natural Science and Engineering Research Council of Canada (NSERC). Volker has 18 patent awards, and he has submitted over 20 invention disclosures to date. Over the course of his career, he has garnered many prestigious awards, including the European Information Society and Technology Prize, an IBM Outstanding Technological Achievement Award , an IBM Shared University Research Grant , an HP Open Innovation Award , an IBM Faculty Award, a Trusted-Cloud Award for Information Marketplaces by the German Ministry of Economics and Technology, the Pat Goldberg Memorial Best Paper Award, and a VLDB Best Paper award. He has been speaker and principal investigator of the Stratosphere collaborative research unit funded by the German National Science Foundation (DFG), which resulted in numerous top-tier publications as well as the "Apache Flink" big data analytics system. Apache Flink is available open source and is currently used in production by several companies and serves as basis for teaching and research by several institutions in Germany, Europe and the United States. Volker currently serves as the secretary of the VLDB Endowment, is advising several companies and startups, and in 2014 was elected as one of Germany's leading "digital minds" (Digitale Köpfe) by the German Informatics Society (GI).
As part of the SFB 876, data from the LHCb experiment at CERN is analyzed by the project C5. A major challenge is to observe the variety of events and detect the most interesting ones while their occurrence is very rare. The LHCb-group has now succeeded in cooperation with a further experiment at CERN, the CMS experiment, to observe the yet rare decay of a B-meson. The decay Bs0 → μ+ μ- was detected while the 50 observed decays yield a branching ratio of about 3 ∙ 10−9 from more than 1014 proton-proton collisions. The importance of this measure, which was published in the journal Nature, is very high, since it represents an extremely sensitive test of the standard model of particle physics. The measured value is in excellent agreement with the expectations of the standard model, so that new physics models are severely limited. Through the collaboration within the SFB 876 both the quality of the data analysis and thus the sensitivity of the measurements should be increased even further.
more...
Thermal-Aware Power Budgeting and Transient Peak Computation for Dark Silicon Chip
System designers usually use TDP as power budget. However, using a single and constant value as power budget is a pessimistic approach for manycore systems.
Therefore, we proposed a new power budget concept, called Thermal Safe Power (TSP), which is an abstraction that provides safe power constraints as a function of the number of active cores. Executing cores at power values below TSP results in a higher system performance than state-of-the-art solutions, while the chip's temperature remains below the critical levels.
Furthermore, runtime decisions (task migration, power gating, DVFS, etc.) are typically used to optimize resource usages. Such decisions change the power consumption, which can result in transient temperatures much higher than steady-state scenarios. To be thermally safe, it is important to evaluate the transient peaks before making resource management decisions.
Hence, we developed a lightweight method for computing these transient peaks, called MatEx, based on analytically solving the system of thermal differential equations using matrix exponentials and linear algebra, instead of using regular numerical methods.
TSP and MatEx (available at http://ces.itec.kit.edu/download) are new steps towards dealing with dark silicon. TSP alleviates the pessimistic dark silicon estimations of TDP, and it enables new avenues for performance improvements. MatEx allows for lightweight transient and peak temperature computations useful to quickly predict the thermal behavior of runtime decisions.

The prestigious awards for the best PhD thesis was awarded by the society "Verein der Freunde und Förderer der ComNets-Einrichtungen" in Aachen at 03.13.2015. This society is researching on future communication networks. The Bernhard-Walke-Award, which is endowed with 1500 Euro, was given to Dr.-Ing. Björn Dusza, for his PhD Thesis with the Title "Context-Aware Battery Lifetime Modeling for Next Generation Wireless Networks". He was working on that subject as an employee at the chair for communication networks (Prof. Dr.-Ing. C. Wietfeld) at the TU Dortmund. The thesis was a contribution to the collaborative research centre 876 "Providing Information by Resource-Constrained Data Analysis". An analysis and stochastic models were used, to research on the power consumption from LTE communication processes from end devices. The results from this thesis makes it possible for the first time, that a network operators could measure the influence from design and assigning network ressources on the battery running time. The collaborative research centre 876 uses the results to decide whether it is better that the data from a sensor is localy analyzed or transfered to some infrastructure.

The next summer school will be hosted at the faculty of sciences of the university of Porto from 2nd to 5th of September and is collocated with ECMLPKDD 2015. It will be organize by LIAAD-INESC TEC and TU Dortmund.
For the summer school, world leading researchers in machine learning and data mining will give lectures on recent techniques for example dealing with huge amounts of data or spatio-temporal streaming data.
SFB members should register via the internal registration page.
more...

The collaborative research centre 876 has build a bridge between the data analysis and cyber-physical systems. The second phase was granted by Deutsche Forschungsgemeinschaft, so the work is continued from 2015-2018.
The coordinator, Prof. Dr. Katharina Morik, reviewed in the starting presentation the last four years. She emphasized the collaboration from the different discplines which are computer science, statistic, medicine, physics, electrical and machine engineering. The characteristic of the collaborative research centre is, that different disciplines are paired and influence each other. Only the combined undestanding of the set of problems could be the base for the next four years. The frame for the research is to extend the runtime from smartphones or to study galaxys in astrophysics.
Dr. Stefan Michaelis gave a review about the application form for the second phase of the collaborative research centre and on the resources that were available. After that Prof. Dr. Kristian Kersting and Prof. Jian-Jia Chen talked briefly about there field of research.
Prof. Dr. Kersting introduced the "Democratization Of Optimization", which are concepts for scalable and easy-to-use methods. Many problems are so complex that they can not be complete solved in acceptable time. Methods that exploit symmetries inside the data set or incorporate expert knowledge simplify a problem so it could be solved.
Prof. Dr. Jian-Jia talked about "Flexible execution models for cyber-physical systems". Computer systems have to provide a result in a predetermined time, which depends on the task. Even in the case of dynamic processes and changing execution times, the worst case running time has to be predictable. The combination of machine learning and cyber-phyiscal systems will lead to optimal execution models in the future.
Opening the SQL Kingdom to the R-ebels
Databases today appear as isolated kingdoms, inaccessible, with a unique culture and strange languages. To benefit from our field, we expect data and analysis to be brought inside these kingdoms. Meanwhile, actual analysis takes place in more flexible, specialised environments such as Python or R. There, the same data management problems reappear, and are solved by re-inventing core database concepts. We must work towards making our hard-earned results more accessible, by supporting (and re-interpreting) their languages, by opening up internals and by allowing seamless transitions between contexts. In our talk, we present our extensive work on bringing a statistical environment (R) together with a analytical data management system (MonetDB).
Thermal-Aware Design of 2D/3D Multi-Processor System-on-Chip Architectures
The evolution of process technologies has allowed us to design compact high-performance computing servers made of 2D and 3D multi-processor system-on-chip (MPSoC) architectures. However, the increase in power density, especially in 3D-stacked MPSoCs, significantly increases heat densities, which can result in degraded performance if the system overheats or in significant overcooling costs if temperature is not properly managed at all levels of abstraction. In this talk I will first present the latest approaches to capture transient system-level thermal behavior of 2D/3D MPSoC including fluidic micro-cooling capabilities, as in the case of IBM Aquasar (1st chip-level water-cooled) supercomputer. Next, I will detail a new family of model-based temperature controllers for energy-efficient 2D/3D MPSoC management. These new run-time controllers exploit both hardware and software layers to limit the maximum MPSoC temperature, and include a thermal-aware job scheduler and apply selectively dynamic frequency and voltage scaling (DVFS) to also balance the temperature across the chip in order to maximize cooling efficiency. One key feature of this new proposed family of thermal controllers is their maximum system temperature forecasting capability, which is used to dynamically compensate for the cooling system delays in reacting to temperature changes. The experiments on modeled 2- and 4-layered 2D/3D MPSoCs industrial designs show that this system-level thermal-aware design approach can enable up to 80% energy savings with respect to state-of-the-art computing severs designs. Finally, I will outline how the combination of inter-tier liquid cooling technologies and micro-fluidic fuel cells can overcome the problem of dark silicon and energy proportionality deployment in future generations of many-core servers and datacenters.
Short biography
David Atienza is associate professor of EE and director of the Embedded Systems Laboratory (ESL) at EPFL, Switzerland. He received his MSc and PhD degrees in computer science and engineering from UCM, Spain, and IMEC, Belgium, in 2001 and 2005, respectively. His research interests focus on system-level design methodologies for high-performance multi-processor Systems-on-Chip (MPSoC) and low-power embedded systems, including new thermal-aware design for 2D and 3D MPSoCs, design methods and architectures for wireless body sensor networks, and memory management. In these fields, he is co-author of more than 200 publications in prestigious journals and international conferences, several book chapters and seven U.S. patents.
He has earned several best paper awards at top venues in electronic design automation and computer and system engineering in these areas; he received the IEEE CEDA Early Career Award in 2013, the ACM SIGDA Outstanding New Faculty Award in 2012 and a Faculty Award from Sun Labs at Oracle in 2011. He is a Distinguished Lecturer (2014-2015) of the IEEE CASS, and is Senior Member of IEEE and ACM. He serves at TPC Chair of DATE 2015 and has been recently appointed as General Chair of DATE 2107.
On October 14, 2014, Peter Marwedel, received the award of the Embedded Systems Week in Delhi. The award honors the scientific works of Peter Marwedel. Prof. Balakrishnan from the Indian Institute (IIT) in Delhi awarded the prize on behalf of the ESWEEK (see photo).  ESWEEK, a cooperation between the ACM and the IEEE (see www.esweek.org), is one of the major events in the field of embedded systems, each year it took place on different continents.
ESWEEK, a cooperation between the ACM and the IEEE (see www.esweek.org), is one of the major events in the field of embedded systems, each year it took place on different continents.
On 6th of November the 3rd Westfalenkongress in Dortmund was supported by the collaborative research center SFB 876. Head of the SFB, Katharina Morik, provided the research view on Big Data Analysis during the opening panel discussion. Later, several presentations of members of the research center showed latest research results on social network analysis, mobile network communcation and road traffic control as well as efficient processing of data streams.
The video below (German only) provides a review of the congress' topics.
Programme and abstracts for the workshop on 5th December 2014 are online. Registration is still possible.
more...
The Deutsche Forschungsgemeinschaft (DFG) granted the next four years of the collaborative research center SFB 876.
Dynamic Resource Scheduling on Graphics Processors
Graphics processors offer tremendous processing power, but do not deliver peak performance, if programs do not offer the ability to be parallelized into thousands of coherently executing threads of execution. This talk focuses on this issue, unlocking the gates of GPU execution for a new class of algorithms.
We present a new processing model enabling fast GPU execution. With our model, dynamic algorithms with various degrees of parallelism at any point during execution are scheduled to be executed efficiently. The core of our processing model is formed by a versatile task scheduler, based on highly efficient queuing strategies. It combines work to be executed by single threads or groups of thread for efficient execution.
Furthermore, it allows different processes to use a single GPU concurrently, dividing the available processing time fairly between them. To assist highly parallel programs, we provide a memory allocator which can serve concurrent requests of tens of thousands of threads. To provide algorithms with the ultimate control over the execution, our execution model supports custom priorities, offering any possible scheduling policy. With this research, we provide the currently fastest queuing mechanisms for the GPU, the fastest dynamic memory allocator for massively parallel architectures, and the only autonomous GPU scheduling framework that can handle different granularities of parallelism efficiently. We show the advantages of our model in comparison to state-of-the-art algorithms in the field of rendering, visualization, and geometric modeling.
The working group "Bayes Methods" and SFB 876 jointly organise the workshop "Algorithms for Bayesian inference for complex problems". The workshop will take place on Friday, 5th of December 2014, at TU Dortmund University.
Presentations on the following topics are particularly welcome:
For further information please visit http://www.imbei.uni-mainz.de/bayes. Registration via mail including your name and affiliation to Manuela Zucknick (m.zucknick@dkfz-heidelberg.de). There is no registration fee.
more...
The Westfalenkongress presents the SFB 876 in a Forum that is dedicated to knowledge transfer.
more...
Non-parametric Methods for Correlation Analysis in Multivariate Data
Knowledge discovery in multivariate data often is involved in analyzing the relationship of two or more dimensions. Correlation analysis with its root in statistics is one of the most effective approaches towards addressing the issue.
In this seminar, I will present some non-parametric methods for correlation analysis in multivariate data. I will focus on real-valued data where probability density functions (pdfs) are in general not available at hand. Instead of estimating them, we propose to work with cumulative distribution functions (cdfs) and cumulative entropy - a new concept of entropy for real-valued data.
For the talk, I will first discuss two methods for scalable mining of correlated subspaces in large high dimensional data. Second, I will introduce an efficient and effective non-parametric method for computing total correlation - a well-known correlation measure based on Shannon entropy. This method is based on discretization and hence, can be perceived as a technique for correlation-preserving discretization (compression) of multivariate data. Lastly, I will go beyond correlation analysis and present our ongoing research in multivariate causal inference.
CV
Hoang-Vu Nguyen is working as a PhD candidate in the Institute for Program Structures and Data Organization (IPD) - Chair Prof. Böhm, Karlsruhe Institute of Technology (KIT). Before joining KIT, he obtained his Master's and Bachelor's degrees from Nanyang Technological University (NTU), Singapore.
His research lies in the junction between theory and practice. Currently, he is focusing on scalable multivariate correlation analysis with applications in data mining. He develops efficient and practical computation methods for correlation measures, and applies them in clustering, outlier detection, mining big data, schema extraction, graph mining, time series analysis, etc.
The Pamono-sensor is a joint development of the institutes for graphical and embedded systems of the TU Dortmund University together with the ISAS - Institute for Analytical Sciences in Dortmund as part of the collaborative research center SFB 876. The sensor will be shown during the TV show "Großen Show der Naturwunder" (Great show of miracles of nature) on 24th of July at 20.15 o'clock at the ARD. Ranga Yogeshwar and Frank Elstner present the sensor together with members of project B2, Pascal Libuschewski and Alexander Zybin, while analyzing the salive of Ranga Yogeshwar on the search for viruses.
The portable sensor device is based on modern multi-core processors and uses sophisticated methods for CPU-intensive algorithms to detect viruses locally and in real-time. Time between taking of samples (blood, salive) and getting analysis results is shortened drastically. The system can therefore be used outside of laboratories where it is needed, e.g. during crisis scenarios.
more...
Algorithmic mechanism design on cloud computing and facility location
Algorithmic mechanism design is now widely studied for various scenarios. In this talk, we discuss two applications: CPU time auction and facility location problem. In CPU time auction, we designed two greedy frameworks which can achieve truthfulness (approximate-truthfulness) from the bidders while at the same time a certain global objective is optimized or nearly optimized. In facility location problem, we introduce weight to the traditional study and prove that those mechanisms that ignore weight are the best we can have. Furthermore, we also propose a new threshold based model where the solution that optimizes the social welfare is incentive compatible.
From Web 2.0 to the Ubiquitous Web

Millions of users are active in the Web 2.0 and enjoy services likeFlickr, Twitter or Facebook. These services are not only used on thecomputer at home but more frequently on smartphones which have becomemore powerful in the last years. Thus, large amounts of content but alsoof usage data are collected - partially with location information usingGPS in smartphones - which allow for various analyses e.g. on the socialrelationship of users. Enriching subjective data like human perceptionsby additional low cost sensor information (not only using smartphonesbut also virtually every device) is an important next step on the waytowards establishing the ubiquitous web. Researchers, especially frommachine learning, data mining, and social network analysis, areinterested in these kinds of data enhanced by additional sensorinformations and work on novel methods and new insides into theunderlying human relationship and interactions with the environment.
One common phenomenon of the Web 2.0 is tagging, observed in manypopular systems. As an example, we will present results on data from ourown social tagging system BibSonomy, which allows the management ofbookmarks and publications. The system is designed to supportresearchers in their daily work but it also allows the integration anddemonstration of new methods and algorithms. Beside a new rankingapproach which was integrated into BibSonomy, we present resultsinvestigating the influence of user behaviour on the emergent semanticsof tagging systems. Starting from results on simple tagging data, thetalk will present results on the combination of user data - againexpressed as tags - and sensor data - in this case air qualitymeasurements - as an example of the emergent ubiquitous web. We willdiscuss the upcoming area of combining these two information sources togain new insides, in this case on environmental conditions and theperceptions of humans.
CV
Andreas Hotho is professor at the university of Würzburg and the head of the DMIR group. Prior, he was a senior researcher at the university of Kassel. He is working in the area of Data Mining, Semantic Web and Mining of Social Media. He is directing the BibSonomy project at the KDE group of the university of Kassel. Andreas Hotho started his research at the AIFB Institute at the University of Karlsruhe where he was working on text mining, ontology learning and semantic web related topics.
Big data in machine learning is the future. But how to deal with data analysis and limited resources: Computational power, data distribution, energy or memory? From 29th of September to 2nd of October, the TU Dortmund University, Germany, will host this summer school on resource-aware machine learning. Further information and online registration at: http://sfb876.tu-dortmund.de/SummerSchool2014
Topics of the lectures include: Data stream analysis. Energy efficiency for multi-core embedded processors. Factorising huge matrices for clustering. Using smartphones to detect astro particles.
Exercises help bringing the contents of the lecture to life. All participants get the chance to learn how to transform a smartphone into an extra-terrestial particle detector using machine learning.
The summer school is open for international PhD or advanced master students, who want to learn cutting edge techniques for machine learning with constrained resources.
Excellent students may apply for a student grant supporting travel and accommodation. Deadline for application is 30th of June.
more...
Die Universität Bremen lädt wieder ein zu zwei Sommeruniversitäten für Frauen in den Ingenieurwissenschaften und in der Informatik:
Die 6. internationale Ingenieurinnen-Sommeruni vom 11. bis 22. August 2014: http://www.ingenieurinnen-sommeruni.de
sowie das 17. internationale Sommerstudium Informatica Feminale vom 18. bis 29. August 2014: http://www.informatica-feminale.de
Das Angebot der beiden Sommeruniversitäten richtet sich an Studentinnen aller Hochschularten und aller Fächer sowie an Weiterbildung interessierte Frauen. Die Sommeruniversitäten umfassen rund 60 Kurse mit Fachinhalten der Ingenieurwissenschaften und der Informatik vom Studieneinstieg über Grundlagen bis zu Spezialthemen. Workshops zu Beruf und Karriere runden das Programm ab.
Das Themenspektrum beinhaltet Lehrveranstaltungen u. a. zu Stoff- und Energieströmen, Datenschutz, Robotik und technischen Netzen, Werkstoffen und Qualitätsmanagement, agiler Softwareentwicklung, Betriebssystemen, Elektronik in Lebenswelten, Projektmanagement, akademischem Englisch, Stimmbildung und Interkulturellen Kompetenzen.
Gauss-Markov modeling and online crowdsensing for spatio-temporal processes

This talk will discuss (1) modelling and (2) monitoring of large spatio-temporal processes covering a city or country, with an application to urban traffic. (1) Gauss-Markov models are well suited for such processes. Indeed, they allow for efficient and exact inference and can model continuous variables. I will explain how to learn a discrete time Gauss-Markov model based on batch historical data using the elastic net and the graphical lasso.(2) Such processes are traditionally monitored by dedicated sensors set up by civil authorities, but sensors deployed by individuals are increasingly used due to their cost-efficiency. This is called crowdsensing. However, the reliability of these sensors is typically unknown and must be estimated. Furthermore, bandwidth, processing or cost constrains may limit the number of sensors queried at each time-step. We model this problem as the selection of sensors with unknown variance in a large linear dynamical system. We propose an online solution based on variational inference and Thompson sampling.
Bio
Francois Schnitzler is a post doctoral researcher at the Technion, working under the supervision of Professor Shie Mannor. He works on time-series modelling and event detection from heterogenous data and crowdsourcing. He obtained his PhD in September 2012 from the University of Liege, where he studied probabilistic graphical models for large probability distributions, and in particular ensemble of Markov trees.
![]()
"The IEEE International Conference on Data Mining (ICDM) has established itself as the world's premier research conference in data mining. We invite high-quality papers reporting original research on all aspects of data mining, including applications, algorithms, software, and systems."
more...
Workshop collocated with INFORMATIK 2014, September 22-26, Stuttgart, Germany.
This workshop focuses on the area where two branches of data analysis research meet: data stream mining, and local exceptionality detection.
Local exceptionality detection is an umbrella term describing data analysis methods that strive to find the needle in a hay stack: outliers, frequent patterns, subgroups, etcetera. The common ground is that a subset of the data is sought where something exceptional is going on: finding the needles in a hay stack.
Data stream mining can be seen as a facet of Big Data analysis. Streaming data is not necessarily big in terms of volume per se but instead it can be in terms of the high troughput rate. Gathering data for analyzing is infeasible so the relevant data of a data point has to be extracted when it arrives.
Submissions are possible as either a full paper or extended abstract. Full papers should present original studies that combine aspects of both the following branches of data analysis:
stream mining: extracting the relevant information from data that arrives at such a high throughput rate, that analysis or even recording of records in the data is prohibited;
local exceptionality mining: finding subsets of the data where something exceptional is going on.
In addition, extended abstracts may present position statements or results of original studies concerning only one of the aforementioned branches.
Full papers can consist of a maximum of 12 pages; extended abstracts of up to 4 pages, following the LNI formatting guidelines. The only accepted format for submitted papers is PDF. Each paper submission will be reviewed by at least two members of the program committee.
more...
Efficient Cryptography with Provable Security
We survey some recent result on efficient cryptographic protocols with the predicate of provable security, in particular focusing on symmetric authentication protocols. In turns out that in this context mathematical lattices play a crucial role for obtaining practical solutions. No deep knowledge in mathematics will be required for this talk.
On February, 25th, the regional competition of Jugend forscht will be held in Dortmund at the DASA exhibition. Jugend forscht provides a platform for young researchers of age 15-21 to present their research ideas and projects. The collaborative research center SFB 876 supports the event again by participating in the jury. This year Stefan Michaelis will evaluate the projects for the domains mathematics and computer science.
ACM SIGDA proudly announces that 2014 ACM SIGDA Distinguished Service Award will be presented to Dr. Peter Marwedel in recognition for his multiple years of service maintaining and chairing the DATE PhD Forum.
The award will be presented at the opening ceremony of the DATE 2014, March 25 in Dresden (Germany).
OpenML: Open science in machine learning
Research in machine learning and data mining can be speeded uptremendously by moving empirical research results out of people'sheads and labs, onto the network and into tools that help us structureand alter the information. OpenML is a collaborative open scienceplatform for machine learning. Through plugins for the major machinelearning environments, OpenML allows researchers to automaticallyupload all their experiments and organize them online. OpenMLautomatically links these experiments to all related experiments, andadds meta-information about the used datasets and algorithms. As such,all research results are searchable, comparable and reusable in manydifferent ways. Beyond the traditional publication of results inpapers, OpenML offers a much more collaborative, dynamic and fasterway of doing research.
Supervised learning of link quality estimates in wireless networks

Systems composed of a large number of relatively simple, and resource-constrained devices can be designed to interact and cooperate with each other in order to jointly solve tasks that are outside their own individual capabilities. However, in many applications, the emergence of the collective behavior of these systems will depend on the possibility and quality of communication among the individuals. In the particular case of wireless data communication, a fundamental and challenging problem is the one of estimating and predicting the quality of wireless links.
In this talk, I will describe our work and experiences in using supervised learning based methods to model the complex interplay among the many different factors that affect the quality of a wireless link. Finally, I will discuss application scenarios in which the prediction models are used by network protocols to derive real-time robust estimates of link qualities, and by mobile robots to perform spatial predictions of wireless links for path planning.
CV
Eduardo Feo received his masters degrees in Software Systems Engineering at RWTH Aachen and in Informatics at University of Trento, Italy. Currently he is working as a Ph.D. candidate at the Dalle Molle Institute for Artificial Intelligence in Lugano, Switzerland on the topic Mission Planning in Heterogeneous Networked Swarms. The work is funded by the project SWARMIX - Synergistic Interactions of Swarms of Heterogeneous Agents.
His research interests include
"The british magazine 'Physics World' awards the first observations of high-energy cosmic neutrinos by the Ice-Cube-Neutrinotelescope as the "Breakthough of the Year 2013". Scientists from Dortmund are involved."
more...
The collaborative research center SFB 876 is back from the two day fair Wissenswerte in Bremen. During the event the SFB's research has been presented with the larger scope of Big Data - small devices. Experiments and demonstrations enabled a clear view on both ends of the spectrum for science journalists.
Project A4 - Plattform presented waste of energy in recent mobile network technology with visible excess heat. Especially during fairs and conferences the problem of suboptimal energy management in mobile devices becomes obvious with the need to recharge often. Project B2 - Nano brought the complete system setup to Bremen and showed the full range of research challenges, from camera and detector technology to data analysis.
For big and complex data the projects C1 - DimRed and C3 - RaumZeit delivered the background. The mere amount of data points per patient in contrast to the low number of severe incidences per year depcited how important a reliable and stable analysis is for neuroblastoma risk prognosis.
Highly relevant are also the big data analysis results in C3, as just recently the detection of high-energetic neutrinos has been confirmed by the IceCube collaboration.
 |
 |
 |
MDL for Pattern Mining
Pattern mining is arguably the biggest contribution of data mining to data analysis with scaling to massive volumes as a close contender. There is a big problem, however, at the very heart of pattern mining, i.e., the pattern explosion. Either we get very few – presumably well-known patterns – or we end up with a collection of patterns that dwarfs the original data set. This problem is inherent to pattern mining since patterns are evaluated individually. The only solution is to evaluate sets of patterns simultaneously, i.e., pattern set mining.
In this talk I will introduce one approach to solve this problem, viz., our Minimum Description Length (MDL) based approach with the KRIMP algorithm. After introducing the pattern set problem I will discuss how MDL may help us. Next I introduce the heuristic algorithm called KRIMP. While KRIMP yields very small pattern sets, we have, of course, to validate that the results are characteristic pattern sets. We do so in two ways, by swap randomization and by classification.
Time permitting I will then discuss some of the statistical problems we have used the results of KRIMP for, such as data generation, data imputation, and data smoothing.
Short Biography
Since 2000, Arno is Chair of Algorithmic Data Analysis at Utrecht University. After doing his PhD and some years as a postdoc as a database researcher, he switched his attention to data mining in 1993 and he still hasn’t recovered. His research has been mostly in the area of pattern mining and since about 8 years in pattern set mining. In the second half of the nineties he was a co-founder of and chief-evangelist and sometimes consultant at Data Distilleries, which by way of SPSS is now a part of IBM. He has acted as PC-member, vice chair or even PC chair of many of the major conferences of the field for many years. Currently he is also on the editorial board of DMKD and KAIS.

With their contribution "Smart Constellation Selection for Precise Vehicle Positioning in Urban Canyons using a Software-Defined Receiver Solution" Brian Niehoefer , Florian Schweikowski and Christian Wietfeld were awarded with the coveted Best Student Paper Award at the 20th IEEE Symposium on Communications and Vehicular Technology ( SCVT ) .
The contribution, originated within the Collaborative Research Project 876 (Sonderforschungsbereich 876), sub-project B4 , deals with a resource-efficient accuracy improvement for Global Navigation Satellite Systems (GNSS). Implementation and performance of the so-called SCS was quantified using a developed software-defined GNSS receiver in more than 500 measurements with two geo-reference points on the campus of the technical university of Dortmund. Thereby the main objective is to achieve an improved positioning accuracy of objects in order to increase the performance and possible scenarios for relying applications. Examples would be a more detailed traffic prediction by detecting lane-specific events (e.g. daily road works, etc.) or more accurate swarm mobilities of Unmanned Aerial Vehicles (UAVs).
The Wissenswerte fair in Bremen is the larget German conference and exhibition for journalists and science. The research center SFB 876 will present the projects A4, B2, C1 and C3 with experiments and results during the fair on 25th and 26th of November 2014.
Would you expect, that some amounts of data are transported faster by ship than by satellite? Which algorithms are needed to cope with these quantities of data? And how much energy do they need? Which algorithms heats up computers beyond function - and which keeps them cool? Where are the parallels between cancer treatment and astro physics?
Questions like these will be answered by the project teams during the Wissenswerte.
more...
Indirect Comparison of Interaction Graphs
Motivation: Over the past years, testing for differential coexpression of genes has become more and more important, since it can uncover biological differences where differential expression analysis fails to distinguish between groups. The standard approach is to estimate gene graphs in the two groups of interest by some appropriate algorithm and then to compare these graphs using a measure of choice. However, different graph estimating algorithms often produce very different graphs, and therefore have a great influence on the differential coexpression analysis.
Results: This talk presents three published proposal and introduces an indirect approach for testing the differential conditional independence structures (CIS) in gene networks. The graphs have the same set of nodes and are estimated from data sampled under two different conditions. Out test uses the entire pathplot in a Lasso regression as the information on how a node connects with the remaining nodes in the graph, without estimating the graph explicitly. The test was applied on CLL and AML data in patients with different mutational status in relevant genes. Finally, a permutation test was performed to assess differentially connected genes. Results from simulation studies are also presented.
Discussion: The strategy presented offers an explorative tool to detect nodes in a graph with the potential of a relevant impact on the regulatory process between interacting units in a complex process. The findings introduce a practical algorithm with a theoretical basis. We see our result as the first step on the way to a meta-analysis of graphs. A meta-analysis of graphs is only useful if the graphs available for aggregation are homogeneous. The assessment of homogeneity of graphs needs procedures like the one presented.
Using dynamic chain graphs to model high-dimensional time series: an application to real-time traffic flow forecasting
This seminar will show how the dynamic chain graph model can deal with the ever-increasing problems of inference and forecasting when analysing high-dimensional time series. The dynamic chain graph model is a new class of Bayesian dynamic models suitable for multivariate time series which exhibit symmetries between subsets of series and a causal drive mechanism between these subsets. This model can accommodate non-linear and non-normal time series and simplifies computation by decomposing a multivariate problem into separate, simpler sub-problems of lower dimensions. An example of its application using real-time multivariate traffic flow data as well as potential applications of the model in other areas will be also discussed.
German newspaper "Süddeutsche" reports on breath analysis done in project B1. How can innovative breath analysis support disease identification and treatment? What can we derive of increased levels of acetone or ammonia in human breath?
more...
The slides for the talk by Albert Bifet on Mining Big Data in Real Time are now available for download:
Big Data is a new term used to identify datasets that we can not managewith current methodologies or data mining software tools due to their large size and complexity. Big Data mining is the capability of extracting useful information from these large datasets or streams of data. New mining techniques are necessary due to the volume, variability, andvelocity, of such data.
more...
Mit über 7.000 Beschäftigten in Forschung, Lehre und Verwaltung und ihrem einzigartigen Profil gestaltet die Technische Universität Dortmund Zukunftsperspektiven: Das Zusammenspiel von Ingenieur- und Naturwissenschaften, Gesellschafts- und Kulturwissenschaften treibt technologische Innovationen ebenso voran wie Erkenntnis- und Methodenfortschritt, von dem nicht nur die mehr als 30.000 Studierenden profitieren.
more...
Mining Big Data in Real Time

Big Data is a new term used to identify datasets that we can not managewith current methodologies or data mining software tools due to their large size and complexity. Big Data mining is the capability of extracting useful information from these large datasets or streams of data. New mining techniques are necessary due to the volume, variability, andvelocity, of such data. In this talk, we will focus on advanced techniquesin Big Data mining in real time using evolving data stream techniques:
We will present the MOA software framework with classification, regression, and frequent pattern methods, the upcoming SAMOA distributed streaming software, and finally we will discuss someadvanced state-of-the-art methodologies in stream mining based in the use of adaptive size sliding windows.
Albert Bifet
Researcher in Big Data stream mining at Yahoo LabsBarcelona. He is the author of a book on Adaptive Stream Mining and Pattern Learning and Mining from Evolving Data Streams. He is one of the project leaders of MOA software environment for implementing algorithms and running experiments for online learning from evolving data streams at theWEKA Machine Learning group at University of Waikato, New Zealand.
Eine Experimentierplattform für die automatische Parallelisierung von R-Programmen
Die Skriptsprache R ist bei Anwendern aus Wissenschaft und Technik wegen ihrer Interaktivität und ihrer guten Bibliotheken beliebt. Für die schnelle Verarbeitung großer Datenmengen, wie sie etwa bei der Genomanalyse in der Bioinformatik anfallen, ist der R-Interpretierer allerdings zu langsam. Es wäre wünschenswert, die hohe Leistung der modernen Mehrkernprozessoren für R nutzen zu können – aber ohne von den Anwendern verlangen zu müssen, daß sie parallele Programme schreiben.
Im Vortrag zeige ich, mit welchen Techniken sich R-Programme zur Laufzeit automatisch parallelisieren lassen, und das transparent für den Anwender. Unsere Experimentierplattform ALCHEMY erlaubt es, ein R-Programm in kombinierbaren Stufen zur Laufzeit zu analysieren, zu parallelisieren und auf parallelen Backends auszuführen. Am Beispiel von Techniken zur automatischen Schleifenparallelisierung, die wir als Module in ALCHEMY realisiert haben, zeigen sich typische Abwägungen, die bei der R-Parallelisierung zu beachten sind. Unsere Messungen belegen, daß sich bei großen Datenmengen der Laufzeitaufwand für die R-Parallelisierung bereits auf einem handelsüblichen Mehrkernprozessor lohnt.
Biographie
Dr. Frank Padberg leitet die Forschergruppe "Automatische Parallelisierung" (APART) am KIT, die gemeinsam vom KIT und Siemens getragen wird. Neben der Parallelisierung forscht er an Techniken zur automatischen Fehlererkennung, Methoden der Software-Zuverlässigkeit, der mathematischen Optimierung von Softwareprozessen und schlanken Entwicklungstechniken. Dr. Padberg wurde in den Communications ACM unter den "Top 50 International Software Engineering Scholars" gelistet.
CPSweek is the meeting point for leading researchers in the thriving area of cyber-physical systems. Topics of CPSweek cover a large range of scientific areas, spanning topics from computer science, physics, embedded systems, electrical engineering, control theory, as well as application disciplines such as systems biology, robotics, and medicine, to name just a few.
CPSWeek 2014 will include a workshop and tutorial day on April 14, 2014. Each workshop will provide an arena for presentations and discussions about a special topic of relevance to CPSWeek. Each tutorial will present in-depth content in a mini-course format aimed primarily at students, researchers, or attendees from industry.
Submission deadline for workshop and tutorial proposals: 29. September 2013
more...
The International Conference on Extending Database Technology is a leading international forum for database researchers, practitioners, developers, and users to discuss cutting-edge ideas, and to exchange techniques, tools, and experiences related to data management. Data management is an essential enabling technology for scientific, engineering, business, and social communities. Data management technology is driven by the requirements of applications across many scientific and business communities, and runs on diverse technical platforms associated with the web, enterprises, clouds and mobile devices. The database community has a continuing tradition of contributing with models, algorithms and architectures, to the set of tools and applications enabling day-to-day functioning of our societies. Faced with the broad challenges of today's applications, data management technology constantly broadens its reach, exploiting new hardware and software to achieve innovative results.
EDBT 2014 invites submissions of original research contributions, as well as descriptions of industrial and application achievements, and proposals for tutorials and software demonstrations. We encourage submissions relating to all aspects of data management defined broadly, and particularly encourage work on topics of emerging interest in the research and development communities.
Deadline: 15. October 2013
more...
The paper Spatio-Temporal Random Fields: Compressible Representation and Distributed Estimation by Nico Piatkowski (A1), Sankyun Lee (C1) and Katharina Morik is the winner of this year's ECMLPKDD 2013 machine learning best student paper award. The ceremony takes place on Monday, September 23rd, in Prague (www.ecmlpkdd2013.org).
 |
 |
 |
| Nico Piatkowski | Sangkyun Lee | Katharina Morik |
The Open Source Satellite Simulator (OS³), developed as part of the SFB 876 at the Communication Networks Institute has been officially integrated into the INET framework for Omnet++.
OS³ provides a modular system for addressing satellite specific communication testing and research. The simulator enables high accuracy results due to its inclusion of recent satellite orbits and atmospheric parameters influencing signal transmission during startup. Beside the modularity and extensibility of OS³ the graphical user interface enables a easy learning curve for adapting the system to the user's needs.
The inclusion of OS³ into the INET framework provides an important milestone for dissemination. Omnet++ is a widely adopted solution for simulating communication networks and builds together with INET the de-facto research standard for simulation of mobile networks.
more...
The publication about Gamma-Hadron-Separation in the MAGIC Experiment by Tobias Voigt, Roland Fried, Michael Backes and Wolfgang Rhode (SFB-project C3) has been granted with the Best Application Paper Award at the 36th annual conference of the GfKI (German Classification Society).
Abstract
The MAGIC-telescopes on the canary island of La Palma are two of the largest Cherenkov telescopes in the world, operating in stereoscopic mode since 2009. A major step in the analysis of MAGIC data is the classification of observations into a gamma-ray signal and hadronic background.
In this contribution we introduce the data which is provided by the MAGIC telescopes, which has some distinctive features. These features include high class imbalance and unknown and unequal misclassification costs as well as the absence of reliably labeled training data. We introduce a method to deal with some of these features. The method is based on a thresholding approach and aims at minimization of the mean square error of an estimator, which is derived from the classification. The method is designed to fit into the special requirements of the MAGIC data.
In enger Zusammenarbeit mit dem Technion (Israel Institute of Technology) entstand basierend auf dem *streams* Framework ein System zur Echtzeitanalyse von Fußball-Daten für den Wettbewerb der diesjährigen DEBS Konferenz. Aufgabe der Challenge war die Berechnung von Statistiken über das Lauf- und Spielverhalten der Spieler, die mit Bewegungs- und Ortungssensoren des RedFIR Systems (Fraunhofer) augestattet wurden.
Im Rahmen des Wettbewerbs entwickelte der Lehrstuhl 8 zusammen mit dem Technion das "TechniBall" System auf Basis des *streams* Frameworks von Christian Bockermann. TechniBall ist in der Lage, die erforderlichen Statistiken deutlich schneller als in Echtzeit (mehr als 250.000 Events pro Sekunde) zu verarbeiten und wurde vom Publikum des Konferenz zum Gewinner des DEBS Challenge 2013 gekürt.
2 papers from SFB-authors accepted -- one of them in the journal track where only 14 out of 182 submissions made it!
The 2013 KDnuggets Software Poll was marked by a battle between RapidMiner and R for the first place. Surprisingly, commercial and free software maintained parity, with about 30% using each exclusively, and 40% using both. Only 10% used their own code - is analytics software maturing? Real Big Data is still done by a minority - only 1 in 7 used Hadoop or similar tools, same as last year.
The 14th annual KDnuggets Software Poll attracted record participation of 1880 voters, more than doubling 2012 numbers.
KDnuggets Annual Software Poll
more...
New Algorithms for Graphs and Small Molecules:
Exploiting Local Structural Graph Neighborhoods and Target Label Dependencies
In the talk, I will present recently developed algorithms for predicting properties of graphs and small molecules: In the first part of the talk, I will present several methods exploiting local structural graph (similarity) neighborhoods: local models based on structural graph clusters, locally weighted learning, and the structural cluster kernel. In the second part, I will discuss methods that exploit label dependencies to improve the prediction of a large number of target labels, where the labels can be just binary (multi-label classification) or can again have a feature vector attached. The methods make use of Boolean matrix factorization and can be used to predict the effect of small molecules on biological systems.
The goal of the International Conference on Mobile Ubiquitous Computing, Systems, Services and Technologies, UBICOMM 2013, is to bring together researchers from the academia and practitioners from the industry in order to address fundamentals of ubiquitous systems and the new applications related to them. The conference will provide a forum where researchers shall be able to present recent research results and new research problems and directions related to them. The conference seeks contributions presenting novel research in all aspects of ubiquitous techniques and technologies applied to advanced mobile applications.
Deadline: 17. May 2013
more...
The IEEE International Conference on Data Mining (ICDM) has established itself as the world's premier research conference in data mining. The 13th ICDM conference (ICDM '13) provides a premier forum for the dissemination of innovative, practical development experiences as well as original research results in data mining, spanning applications, algorithms, software and systems. The conference draws researchers and application developers from a wide range of data mining related areas such as statistics, machine learning, pattern recognition, databases and data warehousing, data visualization, knowledge-based systems and high performance computing. By promoting high quality and novel research findings, and innovative solutions to challenging data mining problems, the conference seeks to continuously advance the state of the art in data mining. As an important part of the conference, the workshops program will focus on new research challenges and initiatives, and the tutorials program will cover emerging data mining technologies and the latest developments in data mining.
Deadline: 21. Juni 2013
more...
Algorithms and Systems for Analyzing Graph-Structured Data
Data analysis, data mining and machine learning are centrally focused on algorithms and systems for producing structure from data. In recent years, however, it has become obvious that it is just as important to look at the structure already present in the data in order to produce the best possible models. In this talk, we will give an overview of a line of research we have been pursuing towards this goal over the past years, focusing in particular on algorithms for efficient pattern discovery and prediction with graphs, applied to areas such as molecule classification or mobility analysis. Especially for the latter, we will also briefly outline how visual approaches can greatly enhance the utility of algorithmic approaches.

Good news for collaborative research center 876: Peter Marwedel, vice-chair of SFB 876, received a top award for his work. He was selected as the recipient of the EDAA lifetime achievement award 2013 by the European Design and Automation Association (EDAA). The Lifetime Achievement Award is given to individuals who made outstanding contributions to the state of the art in electronic design, automation and testing of electronic systems in their life. In order to be eligible, candidates must have made innovative contributions which had an impact on the way electronic systems are being designed.
This selection of Peter Marwedel reflects his work on

The award was openly announced and handed over at this year’s DATE conference in Grenoble on March 19th. The press release for this announcement is available on the website of EDAA.
EDAA is a professional society supporting electronic design automation in particular in Europe. EDAA is the main sponsor of the successful DATE conference.
The EDAA Lifetime Achievement Award can be considered to be the top scientific award in the area of electronic design automation. Past recipients of the award are Kurt Antreich (TU Munich, 2003), Hugo De Man (IMEC, Leuven, 2004), Jochen Jess (TU Eindhoven, 2005), Robert Brayton (UC Berkeley, 2006), Tom W. Williams (Synopsys Inc., Mountain View, California, 2007), Ernest S. Kuh (UC Berkeley, 2008), Jan M. Rabaey (UC Berkeley, 2009), Daniel D. Gajski (UC Irvine, 2010), Melvin A. Breuer (University of Southern California, Los Angeles, 2011) and Alberto L. Sangiovanni-Vincentelli (UC Berkeley, 2012). This means that, so far, only three scientists working at European institutions had received the award. It also means that the quality of research performed at TU Dortmund is at par with that at top universities in the world.
Our collaborative research center is very proud of this international recognition of our vice chair.
Empirical analysis of statistical algorithms often demands time-consuming experiments which are best performed on high performance computing clusters. For this purpose we developed two R packages which greatly simplify working in batch computing environments.
The package BatchJobs implements the basic objects and procedures to control a batch cluster within R. It is structured around cluster versions of the well-known higher order functions Map, Reduce and Filter from functional programming. An important feature is that the state of computation is persistently available in a database. The user can query the status of jobs and then continue working with a desired subset.
The second package, BatchExperiments, is tailored for the still very general scenario of analyzing arbitrary algorithms on problem instances. It extends BatchJobs by letting the user define an array of jobs of the kind "apply algorithm A to problem instance P and store results". It is possible to associate statistical designs with parameters of algorithms and problems and therefore to systematically study their influence on the results.
More details, the source code, installation instructions and much more can be found on the project's web site.
more...
Transactions chasing Instruction Locality on multicores
For several decades, online transaction processing (OLTP) has been one ofthe main applications that drive innovations in the data managementecosystem and in turn the database and computer architecture communities.Despite fundamentally novel approaches from industry and various researchproposals from academia, the fact that OLTP workloads cannot properlyexploit the modern micro-architectural features of the commodity hardwarehas not changed for the last 15 years. OLTP wastes more than half of itsexecution cycles to memory stalls and, as a result, OLTP performancedeteriorates and the underlying modern hardware is largely underutilized.In this talk, I initially present the findings of our recent workloadcharacterization studies, which advocate that the large instructionfootprint of the transactions is the dominant factor in the lowutilization of the existing micro-architectural resources. However, theworker threads of an OLTP system usually execute similar transactions inparallel, meaning that threads running on different cores share anon-negligible amount of instructions. Then, I show an automated way toexploit the instruction commonality among transactional threads andminimize instruction misses. By spreading the execution of a transactionover multiple cores in an adaptive way through thread migration, we enableboth an ample L1 instruction cache capacity and re-use of commoninstructions by localizing them to cores as threads migrate.
Curriculum Vitae
Pinar Tozun is a fourth year PhD student at Ecole Polytechnique Federalede Lausanne (EPFL) working under supervision of Prof. Anastasia Ailamakiin Data-Intensive Applications and Systems (DIAS) Laboratory. Her researchfocuses on scalability and efficiency of transaction processing systems onmodern hardware. Pinar interned at University of Twente (Enschede, TheNetherlands) during summer 2008 and Oracle Labs (Redwood Shores, CA)duringSummer 2012. Before starting her PhD, she received her BSc degree inComputer Engineering department of Koc University in 2009 as the topstudent.
Case-Based Reasoning:
Was ist es und wie kann man es gebrauchen?
Zum Ausgangspunkt fangen wir ganz einfach an: Wir wollen aus Erfahrungen Nutzen ziehen. Was sind hier Fälle und wie gebraucht man sie für Schlussweisen? Wir haben Fragen und erwarten Antworten. Frühere Situationen der Erfahrungen sind fast nie identisch mit aktuellen Situationen. Da ist mit Logik und Gleichheit nicht viel zu machen, Approximation ist wichtig. Der zentrale Begriff ist viel mehr die Ähnlichkeit, von der es freilich eine Unendlichkeit von Formen gibt und die wir diskutieren werden. Hier erörtern wir die Semantik von Ähnlichkeitsmaßen und die Beziehung zu Nutzenfunktionen.
Eine essentielle Erweiterung: Ähnlichkeit direkt zwischen Problemen und Lösungen. Hier werden Erfahrungen nicht mehr direkt verwendet, aber die Techniken sind unverändert. Eine Demo als kleiner Einschub: Wir wollen ein Auto kaufen.
Die Frage, was ein System als CBR-System qualifiziert, beantworten wir durch die Gegenwart eines Prozessmodelles und der Wissenscontainer. Diese werden vorgestellt. Dabei haben wir mit verschiedenen Schwierigkeiten zu kämpfen: Mehrere Formen von Unsicherheit, große Datenmengen, Subjektivität, verschiedene Repräsentationsformen wie Texte, Bilder und gesprochene Sprache.
R2: Biologist friendly web-based genomics analysis & visualization platform
Making the ends meet
Jan Koster (Dept. Oncogenomics, Academic Medical Center, University of Amsterdam , Amsterdam, the Netherlands)
High throughput datasets, such as microarrays are often analyzed by (bio) informaticians, and not the biologist that performed the experiment(s). With the biologist in mind as the end-user, we have developed the freely accessible online genomics analysis and visualization tool, R2 (http://r2.amc.nl).
Within R2, researchers with little or no bioinformatics skills can start working with mRNA, aCGH, ChIP-seq, methylation, up to whole genome sequence data and form/test their own hypothesis.
R2 consists of a database, storing the genomic information, coupled to an extensive set of tools to analyze/visualize the datasets. Analyses within the software are highly connected, allowing quick navigation between various aspects of the data mining process.
In the upcoming lecture, I will give an overview of the platform, provide some insights into the structure of R2, and show some examples on how we have made the ends meet to provide our users with a biologist friendly experience.
During the 14th of March Wouter Duiversteijn was visiting the collaborative research center. Beside the talks with our researchers, he presented his work on Exceptional Model Mining.
Contents of the presentation: Exceptional Model Mining - Identifying Deviations in Data
more...
Patterns that Matter -- MDL for Pattern Mining
by Matthijs van Leeuwen

Pattern mining is one of the best-known concepts in the field of exploratory data mining. A big problem, however, is that humongous amounts of patterns can be mined even from very small datasets. This hinders the knowledge discovery process, as it is impossible for domain experts to manually analyse so many patterns.
In this seminar I will show how compression can be used to address the pattern explosion. We argue that the best pattern set is that set of patterns that compresses the data best. Based on an analysis from MDL (Minimum Description Length) perspective, we introduce a heuristic algorithm, called Krimp, that approximates the best set of patterns. High compression ratios and good classification scores confirm that Krimp constructs pattern-based summaries that are highly characteristic for the data.
Our MDL approach to pattern mining is very generic and can be used to take on a large number of problems in knowledge discovery. One such example is change detection in data streams. I will show how sudden changes in the underlying data distribution of a data stream can be detected using compression, and argue that this can be generalised to concept drift and other slower forms of change.
CV
Matthijs van Leeuwen is a post-doctoral researcher in the Machine Learning group at the KU Leuven. His main interests are pattern mining and related data mining problems; how can we identify patterns that matter? To this end, the Minimum Description Length (MDL) principle and other information theoretic concepts often proof to be very useful.
Matthijs defended his Ph.D. thesis titled 'Patterns that Matter' in February 2010, which he wrote under the supervision of prof.dr. Arno Siebes in the Algorithmic Data Analysis group (Universiteit Utrecht). He received the ECML PKDD 2009 'Best student paper award', and runner-up best student paper at CIKM 2009. His current position is supported by a personal Rubicon grant from the Netherlands Organisation for Scientific Research (NWO).
He was co-chair of MPS 2010, a Lorentz workshop on Mining Patterns and Subgroups, and IID 2012, the ECML PKDD 2012 workshop on Instant and Interactive Data Mining. Furthermore, he was demo co-chair of ICDM 2012 and is currently poster chair of IDA 2013.
Exceptional Model Mining - Identifying Deviations in Data
Finding subsets of a dataset that somehow deviate from the norm, i.e. where something interesting is going on, is an ancient task. In traditional local pattern mining methods, such deviations are measured in terms of a relatively high occurrence (frequent itemset mining), or an unusual distribution for one designated target attribute (subgroup discovery). These, however, do not encompass all forms of "interesting".
To capture a more general notion of interestingness in subsets of a dataset, we develop Exceptional Model Mining (EMM). This is a supervised local pattern mining framework, where several target attributes are selected, and a model over these attributes is chosen to be the target concept. Then, subsets are sought on which this model is substantially different from the model on the whole dataset. For instance, we can find parts of the data where:
We will discuss some fascinating real-world applications of EMM instances, for instance using the Bayesian network model to identify meteorological conditions under which food chains are displaced, and using a regression model to find the subset of households in the Chinese province of Hunan that do not follow the general economic law of demand. Additionally, we will statistically validate whether the found local patterns are merely caused by random effects. We will simulate such random effects by mining on swap randomized data, which allows us to attach a p-value to each found pattern, indicating whether it is likely to be a false discovery. Finally, we will shortly hint at ways to use EMM for global modeling, enhancing the predictive performance of multi-label classifiers and improving the goodness-of-fit of regression models.
On February, 19th, the regional competition of Jugend forscht will be held in Dortmund at the DASA exhibition. Jugend forscht provides a platform for young researchers of age 15-21 to present their research ideas and projects. For the domains mathematics and computer science Christian Bockermann of SFB-project C1 will be a member of the jury.
Peter Marwedel is honored with the EDAA (European Design and Automation Assocation) lifetime achievement award.
This award is given to individuals who made outstanding contributions to the state of the art in electronic design, automation and testing of electronic systems in their life. In order to be eligible, candidates must have made innovative contributions which had an impact on the way electronic systems are being designed.
The Award will be presented at the plenary session of the 2013 DATE Conference, to be held 18-22 March in Grenoble, France.
more...
Anwendungen der Drei-Phasen Verkehrstheorie zur intelligenten Verkehrssteuerung
Nach einer kurzen Vorstellung der Forschungsarbeiten der Daimler AG gibt der Vortrag einen Überblick über die Kerner'sche Drei-Phasen-Verkehrstheorie und einige ihrer Anwendungen. Basierend auf gemessenen Verkehrsdaten vieler Jahre werden die empirischen Eigenschaften von Verkehrszusammenbrüchen und deren Folgen dargelegt.
Das Verständnis der zeitlich-räumlichen Eigenschaften des Verkehrs führte zu Anwendungen, die bis zu einem online-Betrieb ausgebaut wurden. Aktuelle Beispiele aus dem Car-2-X-Feldversuch SIMTD zeigen und bestätigen Aussagen und Anwendungen dieser Verkehrstheorie.
Dr. Hubert Rehborn ist Manager für Group Research and Advanced Engineering Telematics System Functions and Features in der Vorentwicklung Daimler AG, Stuttgart.
Solutions to optimization problems in resource constrained systems
This talk explores topics that relate to methods and techniques applicable for solving optimization problems that emerge from resource constrained systems. It addresses both deterministic problems, characterized by crisp decision variables, and stochastic problems, where decisions are described by probability distributions.
The presentation will include an overview of the most popular solution methods and two novel methodologies: Randomized Search method for solving hard non-linear, non-convex combinatorial problems and generalized stochastic Petri net (GSPN) based framework for stochastic problems.
The second part of the talk focuses on solutions of exact problems. First, we address a problem of energy efficient scheduling and allocation in heterogeneous multi-processor systems. The solution uses GSPN framework to address the problem of scheduling and allocating concurrent tasks when execution and arrival times are described by probability distributions. Next, we present a Gaussian mixture model vector quantization technique for estimating power consumption in virtual environments. The technique uses architectural metrics of the physical and virtual machines (VM) collected dynamically to predict both the physical machine and per VM level power consumption.
Curriculum Vitae
Kresimir Mihic is a Senior Researcher in Modeling, Simulation and Optimization group, Oracle Labs. His work is in the area of optimization of complex systems, with specific interest in discrete optimization techniques and applications thereof on non-linear, non-convex multi-objective problems, for static and dynamic cases. Kresimir received D.Engr in Electrical Engineering from Stanford University in 2011.
The book Managing and Mining Sensor Data has been published as an ebook and will be available as hardcover from 28th of February 2013. The book has been supported by the collaborative research center by the authors Marco Stolpe (project B3, Artificial Intelligence) and the guest researcher Kanishka Bhaduri. They contributed the chapter on Distributed Data Mining in Sensor Networks.
Especially sensor networks provide data at different, distributed locations. For an efficient analysis new technologies need to calculate results even if communication ressources are constrained.
more...
Database Joins on Modern Hardware
Computing hardware today provides abundant compute performance. But various I/O bottlenecks—which cannot keep up with the exponential growth of Moore's Law—limit the extent to which this performance can be harvested for data-intensive tasks, database tasks in particular. Modern systems try to hide these limitations with sophisticated techniques such as caching, simultaneous multi-threading, or out-of-order execution.
In the talk I will discuss whether/how database join algorithms can benefit from these sophisticated techniques. As I will show in the talk, database alone is not good enough to hide its own limitations. But once database algorithms are made aware of the hardware characteristics, they achieve unprecedented performance, pairing hundreds of millions of database tuples per second.
The work reported in this work has been conducted in the context of the Avalanche project at ETH Zurich and funded by the Swiss National Science Foundation (SNSF).
Algorithms and Systems for Analyzing Graph-Structured Data
Data analysis, data mining and machine learning are centrally focused on algorithms and systems for producing structure from data. In recent years, however, it has become obvious that it is just as important to look at the structure already present in the data in order to produce the best possible models. In this talk, we will give an overview of a line of research we have been pursuing towards this goal over the past years, focusing in particular on algorithms for efficient pattern discovery and prediction with graphs, applied to areas such as molecule classification or mobility analysis. Especially for the latter, we will also briefly outline how visual approaches can greatly enhance the utility of algorithmic approaches.
OS³, the Open Source Satellite Simulator, was developed as a framework for simulating various kinds of satellite-based communication, based on OMNeT++. The objective is to create a platform that makes evaluating satellite communication protocols as easy as possible. OS³ will also be able to automatically import real satellite tracks and weather data to simulate conditions at a certain point in the past or in the future, and offer powerful visualization.
OS³ will enable a comfortable analysis of complex screnarios which may be infeasible to test in reality. Starting anywhere from calculating attenuation losses for earth-bound receivers up to complex mobility scenarios, the variety of topics is only limited by creativity. For example, users will be able to test new protocols or satellite orbits and evaluate the resulting performance pertaining to SNR, bit error rate, packet loss, round trip time, jitter, reachability, and other measures.
Since OS³ will be released under a public license and will include a comprehensive documentation, users always have the possibilty to add customizations. Yet another advantage is that users will be able to share their code with the community and improve the overall quality of OS³ even further. Because OS³ is operating system independent, employing OS³ is feasible for anyone who is restricted to a specific operating system.
more...
Resource-aware computing has become a more and more active research topic. Combining this with the increasing interest in data mining, particularly mining big data, puts our research centre at a successful track!
Distributed data usage control is about what happens to data once it is
given away ("delete after 30 days;" "notify me if data is forwarded;"
"copy at most twice"). In the past,
we have considered the problem in terms of policies,
enforcement and guarantees from two perspectives:
The German newspaper "Ruhr Nachrichten" has published an article about the Virus-Sensor developed within project B2 of the SFB 876. The full article can be found on their website.
more...
As nowadays massive amounts of data are stored in database systems, it
becomes more and more difficult for a database user to exactly retrieve
data that are relevant to him: it is not easy to formulate a database
query such that, on the one hand, the user retrieves all the answers that
interest him, and, on the other hand, the user does not retrieve too much
irrelevant data.
A flexible query answering mechanism automatically searches for
informative answers: it offers the user information that is close to (but
not too far away from) what the user intended. In this talk, we show how
to apply generalization operators to queries; this results in a set of
logically more general queries which might have more answers than the
original query.
A similarity-based or a weight-based strategy can be used to obtain only
answers close to the user's interest.
The German newspaper "Westdeutsche Allgemeine Zeitung" has published an article about Katharina Morik. The full article can be found on their website.
more...
Resource-Efficient Processing and Communication in Sensor/Actuator Environments
The future of computer systems will not be dominated by personal computer like hardware platforms but by embedded and cyber-physical systems assisting humans in a hidden but omnipresent manner. These pervasive computing devices can, for example, be utilized in the home automation sector to create sensor/actuator networks supporting the inhabitants of a house in everyday life.
The efficient usage of resources is an important topic at design time and operation time of mobile embedded and cyber-physical systems. Therefore, this thesis presents methods which allow an efficient use of energy and processing resources in sensor/actuator networks. These networks comprise different nodes cooperating for a smart joint control function. Sensor/actuator nodes are typical cyber-physical systems comprising sensors/actuators and processing and communication components. Processing components of today’s sensor nodes can comprise many-core chips.
This thesis introduces new methods for optimizing the code and the application mapping of the aforementioned systems and presents novel results with regard to design space explorations for energy-efficient and embedded many-core systems. The considered many-core systems are graphics processing units. The application code for these graphics processing units is optimized for a particular platform variant with the objectives of minimal energy consumption and/or of minimal runtime. These two objectives are targeted with the utilization of multi-objective optimization techniques. The mapping optimizations are realized by means of multi-objective design space explorations. Furthermore, this thesis introduces new techniques and functions for a resource-efficient middleware design employing service-oriented architectures. Therefore, a service-oriented architecture based middleware framework is presented which comprises a lightweight service orchestration. In addition to that, a flexible resource management mechanism will be introduced. This resource management adapts resource utilization and services to an environmental context and provides methods to reduce the energy consumption of sensor nodes.
Submission deadline for WESE Workshop on Embedded and Cyber-Physical Systems Education at ESWEEK is now August 7th, 2012. For further information see http://esweek.acm.org .
The Johnson-Lindenstrauss Transform and Applications to Dimensionality Reduction
The Johnson-Lindenstrauss transform is a fundamental dimensionality reduction technique with a wide range of applications in computer science. It is given by a projection matrix that maps vectors in Rˆd to Rˆk, where k << d, while seeking to approximately preserve their norm and pairwise distances. The classical result states that k = O(1/fˆ2 log 1/p) dimensions suffice to approximate the norm of any fixed vector in Rˆn to within a factor of 1 + f with probability at least 1-p, where 0 < p,f < 1. This is a remarkable result because the target dimension is independent of d. The projection matrix is itself produced by a random process that is oblivious to the input vectors. We show that the target dimension bound is optimal up to a constant factor, improving upon a previous result due to Noga Alon. This based on joint work with David Woodruff (SODA 2011).
BIO: Dr. T.S. Jayram is a manager in the Algorithms and Computation group at IBM Almaden Research Center and currently visiting IBM India Research Lab. He is interested in the theoretical foundations of massive data sets such as data streams, and has worked on both the algorithmic aspects and their limitations thereof. The latter has led to new techniques for proving lower bounds via the information complexity paradigm. For work in this area, he has received a Research Division Accomplishment Award in Science from IBM and was invited to give a survey talk on Information Complexity at PODS 2010.
The textbook "Embedded System Design: Embedded Systems Foundations of Cyber-Physical Systems" by Prof. Dr. Peter Marwedel gets very good reviews. Embedded System Design starts with an introduction into the area and a survey of specification models and languages for embedded and cyber-physical systems. It provides a brief overview of hardware devices used for such systems and presents the essentials of system software for embedded systems, like real-time operating systems. The book also discusses evaluation and validation techniques for embedded systems. Furthermore, the book presents an overview of techniques for mapping applications to execution platforms. Due to the importance of resource efficiency, the book also contains a selected set of optimization techniques for embedded systems, including special compilation techniques. The book closes with a brief survey on testing.
Here some comments:
"This is a nice book, structured and orgnized very well. It will give you a clear understanding of design of embedded system along the way. This book is far more clear and better than the "Introduction to Embedded Systems: A Cyber-Physical Systems Approach" which is published by a Berkeley professor. I would hope that my graduate school could use this book as the primary textbook in future semesters on teaching embedded system design, instead of the "Introduction to Embedded Systems: A Cyber-Physical Systems Approach". "
"My grad school class used this book to supplement and get a different type of explanation to specifically tricky concepts. We did not use it as the main book so it was not read in it's entirety. But was very different than our primary book (author is a professor from Berkley), so it served its purpose and I am glad I bought it."
more...
There has been a spectacular advance in our capability to acquire data and in many cases the data may arrive very rapidly. Applications processing this data have caused a renewed focus on efficiency issues of algorithms. Further, many applications can work with approximate answers and/or with probabilistic guarantees. This opens up the area of design of algorithms that are significantly time and space efficient compared to their exact counterparts.
The workshop will be held in the campus of the Technical University of Dortmund, in the Department of Computer Science, as part of the SFB 876. It is planned as a five-day event from 23rd to 27 of July and consists of only invited talks from leading experts on the subject.
The workshop aims at bringing together leading international scientists to present and discuss recent advances in the area of streaming algorithms. In the context of the sponsoring collaborative research center on the more general topic of data analysis under resource-restrictions, such algorithms are being developed as well as applied to large-scale data sets. The workshop will give all participants the opportunity to learn from each others' knowledge and to cooperate in further research on interesting theoretical as well as applied topics related to streaming algorithms.
more...
Individuell bewegen - Das Internet der Dinge und Dienste in der Logistik
Der Vortrag Individuell bewegen - Das Internet der Dinge und Dienste gibt einen groben Überblick über den Entwicklungsstand der Forschung und Entwicklung im Bereich der hoch dezentralisierten, echtzeitfähigen Steuerung intralogistischer Systeme im Zusammenspiel mit dem überlagerten, Cloud-basierten Internet der Dienste.
Internet der Dinge
Das Internet der Dinge ist für die Logistik zunächst mit der Einführung von AutoID- Technologien und der Speicherung von Informationen am Gut oder Ladehilfsmittel - jenseits der reinen Identifikation - verbunden. Damit werden Material- und Informationsfluss vereint, Schnittstellen überbrückt und die Individualität der logistischen Entscheidungsfindung im Echtzeitbereich ermöglicht. Zentrales Ziel adäquater Entwicklungen ist die Beherrschung der ständig steigenden Komplexität logistischer Netze durch hochgradige Dezentralisierung und Autonomie der unterlagerten, echtzeitnahen Steuerungsebene. Der Bezug zum SFB 876 ergibt sich u. A. durch die Notwendigkeit, Datenmengen zu beschränken und zugleich sinnvolle, dezentrale Entscheidungen zu ermöglichen. Eine physische Umsetzung findet das Internet der Dinge in den Schwärmen autonomer Fahrzeuge der Zellularen Transportsysteme, die ebenfalls kurz im Vortrag vorgestellt werden.
Internet der Dienste
Die normative Auftragssteuerung auf Basis serviceorientierter Architekturen ist der zweite wesentliche Schritt in Richtung eines neuen, wandelbaren Logistikmanagements. Das Internet der Dienste soll Flexibilität und Dynamik jenseits starrer Prozessketten gewährleisten, aber zugleich die Standardisierung von IT und Logistik-Services ermöglichen. Im Vortrag werden einige Grundgedanken umrissen, die zum Fraunhofer-Innovationscluster Logistics Mall - Cloud Computing for Logistics führten und es wird versucht, ein Gesamtbild des Internets der Dinge und Dienste für die Logistik zu zeichnen.
The summer school is organized by the PhD students of the Integrated Research Training Group (IRTG), which is part of the University’s Collaborative Research Center (CRC) SFB 944. Within the CRC, several research groups of the biology and physics departments from the Universities of Osnabrück and Münster work closely together with a common interest in studying microcompartments as basic functional units of a variety of cells. The aim of the Summer School is to bring together distinguished scientists from different disciplines for intense scientific discussions on this topic.
Our International Summer School will take place as a conference in the Bohnenkamp-Haus at the Botanical Garden from September 21st to 22nd, 2012. The panel of invited speakers is intended to represent the variety of topics and approaches, but also the common interest in studying the function and dynamics of cellular microcompartments. Interested students and scientists from Osnabrück and elsewhere are cordially invited to join the sessions. For the PhD students of our CRC, it will be a unique opportunity to get into contact with outstanding international scientists to discuss science and share insights.
more...
Privacy Preserving Publishing of Spatio-temporal Data Sets
Spatio-temporal datasets are becoming more and more popular due to the widespread usage of GPS enabled devices, wi-fi location technologies, and location based services that rely on them. However, location, as a highly sensitive data type also raises privacy concerns. This is due to the fact that our location can be used to infer a lot about us. Therefore special attention must be paid when publishing spatio-temporal data sets. In this seminar, I will first make a general introduction to privacy preserving data publishing and then talk about some research issues regarding privacy-preserving publishing of spatio-temporal data sets together with the proposed solutions.
The European Soccer Championship 2012 has begun and everybody wants to know who will win it. A team of graduates of the collaborative research center SFB 876 tries to answer this already before each match.
Using their Data Mining skills, they predict the outcomes of the matches in a series of Blog-Posts during the championship. Everybody is invited to follow the articles to see the evolution from raw data to prediction. Beside the prediction of the winning team itself, the whole process of retrieving data, training learning models and generating results is covered as well.
Join us on the journey and see, whether technology will succeed or soccer stays unpredictable as before.
more...
In der Fakultät für Informatik der Technischen Universität Dortmund ist baldmöglichst eine Universitätsprofessur W2 (Praktische Informatik) Data Mining zu besetzen.
Bewerberinnen und Bewerber sollen sich in Forschung und Lehre schwerpunktmäßig der Analyse sehr großer Datenmengen, z. B. mit Spezialisierung im Bereich des Relationalen Lernens und Anwendungen in den Lebenswissenschaften widmen und darin international in besonderem Maße wissenschaftlich ausgewiesen sein. Die Mitwirkung am SFB 876, Verfügbarkeit von Information durch Analyse unter Ressourcenbeschränkung, wird erwartet, ebenso wie eine angemessene Beteiligung an der grundständigen Lehre in den Studiengängen der Fakultät für Informatik, bei der Förderung des wissenschaftlichen Nachwuchses und an der Selbstverwaltung der Technischen Universität Dortmund.
Bewerbungen mit den üblichen Unterlagen werden erbeten bis zum 07.06.2012 an die
Dekanin der Fakultät für Informatik,
Prof. Dr. Gabriele Kern-Isberner,
Technische Universität Dortmund,
44221 Dortmund,
Tel.: 0231 755-2121,
Fax: 0231 755-2130,
E-Mail: dekan.cs@udo.edu
Route Planning: Energy-efficient, Constraint-respecting, and fast!
While the classical problem of computing shortest paths in a graph is still an area of active research, the growing interest in energy-efficient transportation has created a large number of new and interesting research questions in the context of route planning.
How can I find the energy-optimal path from A to B for my electric vehicle (EV)? Where are the best locations for battery switch stations such that I can get anywhere with my EV? What is the shortest path from A to B which does not exceed a total height difference of 200m? For some of these problems we exhibit their inapproximability, for others we present very efficient algorithms.
Every year Informatica Feminale offers compact teachings in Informatics (Computer Science) for women students of all types of universities and colleges as well as for women professionals interested in further training. Entering higher education, developing student careers, transition into labor market and lifelong academic learning are equally in the field of vision. Inter/national lecturers and students meet at the Summer University in Bremen to exchange, experiment and find new concepts for Informatics and related disciplines in higher education.
The 15th International Summer University is held at the University of Bremen from Monday, 20th of August 2012 until Friday, 31st of August 2012. more...
Algorithmic Tools for Spectral Image Annotation and Registration
Annotating microspectroscopic images by overlaying them with stained microscopic images is an essential task required in many applications of vibrational spectroscopic imaging. This talk introduces two novel tools applicable in this context. First, an image registration approach is presented that allows to locate (register) a spectral image within a larger H+E stained image, which is an essential prerequisite to annotate the spectral image. The second part introduces the interactive Lasagne annotation tool that allows to explore spectral images by highlighting regions sharing high spectral similarity using distance geometry.
New Lower Bounds and Algorithms in Distributed Computing
We study several classical graph-problems such as computing all pairs shortest paths, as well as the related problems of computing the diameter, center and girth of a network in a distributed setting. The model of distributed computation we consider is: in each synchronous round, each node can transmit a different (but short) message to each of its neighbors. For the above mentioned problems, the talk will cover algorithms running in time O(n), as well as lower bounds showing that this is essentially optimal. After extending these results to approximation algorithms and according lower bounds, the talk will provide insights into distributed verification problems. That is, we study problems such as verifying that a subgraph H of a graph G is a minimum spanning tree and it will turn out that in our setting this can take much more time than actually computing a minimum spanning tree of G. As an application of these results we derive strong unconditional time lower bounds on the hardness of distributed approximation for many classical optimization problems including minimum spanning tree, shortest paths, and minimum cut. Many of these results are the first non-trivial lower bounds for both exact and approximate distributed computation and they resolve previous open questions. Our result implies that there can be no distributed approximation algorithm for minimum spanning tree that is significantly faster than the current exact algorithm, for any approximation factor.
We now have an access to the Foundations and Trends in Machine Learning journal. Each issue has a 50~100 page tutorial/survey written by research leaders, covering important topics in machine learning.
more...
Leysin, Switzerland, 1-6 July 2012
Deadline for grant application: 25 April, 2012
Deadline for registration: 15 May, 2012
The 2nd Summer School on Mobility, Data Mining, and Privacy is co-organized by the FP7/ICT project MODAP - Mobility, Data Mining and Privacy - and the COST Action IC0903 MOVE - Knowledge Discovery from Moving Objects. It is also supported by the FP7/Marie Curie project SEEK and by CUSO, a coordination body for western Switzerland universities
The specific focus of this edition is on privacy-aware social mining, i.e. how to discover the patterns and models of social complexity from the digital traces of our life, in a privacy preserving way.
more...
Modeling User Navigation on the Web
Understanding how users navigate through the Web is essential for improving user experience. In contrast to traditional approaches, we study contextual and session-based models for user interaction and navigation. We devise generative models for sessions which are augmented by context variables such as timestamps, click metadata, and referrer domains. The probabilistic framework groups similar sessions and naturally leads to a clustering of the data. Alternatively, our approach can be viewed as a behavioral clustering where each user belongs to several clusters. We evaluate our approach on click logs sampled from Yahoo! News. We observe that the incorporation of context leads to interpretable clusterings in contrast to classical approaches. Conditioning the model on the context significantly increases the predictive accuracy for the next click. Our approach consistently outperforms traditional baseline methods and personalized user models.
Christoph Borchert, researcher at the Embedded Systems Group of Prof. Olaf Spinczyk and member of the SFB 876 project A4, received the Hans-Uhde-Award for outstanding accomplishments during his academic studies. Amongst other things, his master thesis is written about Development of on aspect-oriented TCP/IP-Stack for embedded systems.
The software developed in the thesis enables memory-efficient management of TCP/IP communication sessions. The aspect oriented approach guarantees easy reconfiguration of the stack to adapt to different application scenarios.
Since 1986, the Hans-Uhde-Foundation promotes science and education. Every year, outstanding academic achievements are awarded.
Optimizing Sensing: Theory and Applications
Where should we place sensors to quickly detect contamination in drinking water distribution networks? Which blogs should we read to learn about the biggest stories on the web? These problems share a fundamental challenge: How can we obtain the most useful information about the state of the world, at minimum cost?
Such sensing problems are typically NP-hard, and were commonly addressed using heuristics without theoretical guarantees about the solution quality. In this talk, I will present algorithms which efficiently find provably near-optimal solutions to large, complex sensing problems. Our algorithms exploit submodularity, an intuitive notion of diminishing returns, common to many sensing problems; the more sensors we have already deployed, the less we learn by placing another sensor. To quantify the uncertainty in our predictions, we use probabilistic models, such as Gaussian Processes. In addition to identifying the most informative sensing locations, our algorithms can handle more challenging settings, where sensors need to be able to reliably communicate over lossy links, where mobile robots are used for collecting data or where solutions need to be robust against adversaries, sensor failures and dynamic environments.
I will also present results applying our algorithms to several real-world sensing tasks, including environmental monitoring using robotic sensors, deciding which blogs to read on the web, and detecting earthquakes using community-held accelerometers.
Big data in machine learning is the future. But how to deal with data analysis and limited resources: Computational power, data distribution, energy or memory?
From 4th to 7th of September, the TU Dortmund University, Germany, will host this summer school on resource-aware machine learning. Further information and online registration at: http://sfb876.tu-dortmund.de/SummerSchool2012
Topics of the lectures include: Mining of ubiquitous data streams, criteria for efficient model selection or dealing with energy constraints... The theoretical lessons are accompanied by exercises and practical introductions: Analysis with RapidMiner and R, massively parallel programming with CUDA. A Data Mining Competition lets you test your machine learning skills on real world smartphone data.
The summer school is open for international PhD or advanced master students, who want to learn cutting edge techniques for machine learning with constrained resources.
Excellent students may apply for a student grant supporting travel and accommodation. Deadline for application is 1st of June.
more...
The IEEE International Conference on Data Mining (ICDM) has established itself as a premier research conference in data mining. It provides a leading forum for the presentation of original research results, as well as exchange and dissemination of innovative ideas, drawing researchers and practitioners from a wide range of data mining related areas such as statistics, machine learning, pattern recognition, databases, visualization, high performance computing, and so on. By promoting novel, high quality research findings, and innovative solutions to challenging data mining problems, the conference seeks to continuously advance the state-of-the-art in data mining. Besides the technical program, the conference will feature invited talks from research and industry leaders, as well as workshops, tutorials, panels, and the ICDM data mining contest.
Dealine: June, 18th, 2012
more...
The Ditmarsch Tale of Wonders - the dynamics of lying
We propose a dynamic logic of lying, wherein a lie is an action inducing the transformation of an information structure encoding the uncertainty of agents about their beliefs. We distinguish the treatment of an outside observer who is lying to an agent that is modelled in the system, from the case of one agent who is lying to another agent, and where both are modelled in the system. We also model bluffing, how to incorporate unbelievable lies, and lying about modal formulas. For more information, see http://arxiv.org/abs/1108.2115
The buzzword of our time, “sustainability”, is closely related to a book published 40 years ago, in 1972: “The Limits to Growth” written by an MIT project team involving Donella and Dennis Meadows. Using computer models in an attempt to quantify various aspects of the future, “Limits to Growth” has shaped new modes of thinking. The book became a bestseller and is still frequently cited when it comes to analyzing growth related to finite resources.
Objectives of the Winter School In order to give fresh impetus to the debate, the Volkswagen Foundation aims to foster new think- ing and the development of different models in all areas related to the “Limits to Growth” study at the crossroads of natural and social sciences. The Winter School “Limits to Growth Revisited” is directed specifically at 60 highly talented young scholars from all related disciplines. The Foundation intends to grant this selected group of academics the opportunity to create networks with scholars from other research communities.
more...
Network Design and In-network Data Analysis for Energy-efficient Wireless Sensor Networks of Bridge-Monitoring Applications
In this talk, I will focus on the network design and in-network data analysis issues for energy-efficient wireless sensor networks (WSN) in the context of bridge monitoring applications. First, I will introduce the background of our research, a project funded by the U.S. National Science Foundation. Then I will discuss the history of the critical communication radius problem in wireless sensor network design, and explain our result of determinate upper and lower bounds of the critical radius for the connectivity of bridge-monitoring WSN in detail. Finally I will describe a distributed in-network data analysis algorithm for energy-efficient WSN performing iterative modal identification in bridge-monitoring applications.
Together with Kanishka Bhaduri and Hillol Kargupta, Katharina Morik has edited a special issue of the international journal Data Mining and KnowledgeDiscovery. The special issue on Data Mining for Sustainability including a comprehensive introduction is now online at http://www.springerlink.com/.
more...
In der Fakultät für Informatik der Technischen Universität Dortmund ist baldmöglichst eine Universitätsprofessur W3 (Technische Informatik) Methodik eingebetteter Systeme (Nachfolge Peter Marwedel) zu besetzen.
Bewerberinnen und Bewerber sollen sich in Forschung und Lehre schwerpunktmäßig der Rechner- und Systemarchitektur, deren Optimierung (z. B. bzgl. der Energieeffizienz) oder deren Anwendung (z. B. in der Logistik) widmen und darin international in besonderem Maße wissenschaftlich ausgewiesen sein. Die Mitwirkung am SFB 876, Verfügbarkeit von Information durch Analyse unter Ressourcenbeschränkung, wird erwartet, ebenso wie eine angemessene Beteiligung an der grundständigen Lehre in den Studiengängen der Fakultät für Informatik, bei der Förderung des wissenschaftlichen Nachwuchses und an der Selbstverwaltung der Technischen Universität Dortmund.
Bewerbungen mit den üblichen Unterlagen werden erbeten bis zum 16.02.2012 an die
Dekanin der Fakultät für Informatik,
Prof. Dr. Gabriele Kern-Isberner,
Technische Universität Dortmund,
44221 Dortmund,
Tel.: 0231 755-2121,
Fax: 0231 755-2130,
E-Mail: dekan.cs@udo.edu
In der Fakultät für Informatik der Technischen Universität Dortmund ist baldmöglichst eine Universitätsprofessur W3 (Praktische Informatik) Datenbanken und Informationssysteme (Nachfolge Joachim Biskup) zu besetzen.
Bewerberinnen und Bewerber sollen in Forschung und Lehre schwerpunktmäßig das Gebiet Datenbanken und Informationssysteme vertreten, idealerweise mit Schwerpunkt in der Verwaltung sehr großer Datenmengen, und darin international in besonderem Maße wissenschaftlich ausgewiesen sein. Die Mitwirkung am SFB 876, Verfügbarkeit von Information durch Analyse unter Ressourcenbeschränkung, wird erwartet, ebenso wie eine angemessene Beteiligung an der grundständigen Lehre in den Studiengängen der Fakultät für Informatik, bei der Förderung des wissenschaftlichen Nachwuchses und an der Selbstverwaltung der Technischen Universität Dortmund.
Bewerbungen mit den üblichen Unterlagen werden erbeten bis zum 16.02.2012 an die
Dekanin der Fakultät für Informatik,
Prof. Dr. Gabriele Kern-Isberner,
Technische Universität Dortmund,
44221 Dortmund,
Tel.: 0231 755-2121,
Fax: 0231 755-2130,
E-Mail: dekan.cs@udo.edu
KI 2012, the 35th German Conference on Artificial Intelligence, taking place in Saarbrücken (Germany) from September 24th to 27th, invites original research papers, as well as workshop and tutorial proposals from all areas of AI, its fundamentals, its algorithms, and its applications. Together with the main conference, it aims at organizing a small number of high-quality workshops suitable for a large percentage of conference participants, including graduate students as well as experienced researchers and practitioners.
more...
The slides of the presentation by Piero Bonatti on Confidentiality policies on the semantic web: Logic programming vs. Description logics are now available for Download.
Presentation abstract:
An increasing amount of information is being encoded via ontologies and knowledge representation languages of some sort. Some of these knowledge bases are encoded manually, while others are generated automatically by information extraction techniques. In order to protect the confidentiality of this information, a natural choice consists in encoding access control policies with the ontology language itself. This approach led to so-called "semantic web policies".
more...
The first year SFB 876 ends with a selection of presentations during our Christmas Topical Seminar:
The christmas party of the faculty for computer science starts afterwards in front of the lecture hall.
Shortly after the installation on 11th October FACT (First G-APD Cherenkov Telescope) yielded the first data. These data is used in projekt C3. FACT was developed in collaboration with the TU Dortmund University of Wuerzburg, ETH Zurich and others. It is able to take 109 pictures per second. Further details can be found in the article.
more...
The international summer university will take place from August 20th to August 31st 2012 in the Department for Mathematics and Informatics.
Women experts from science and practice may submit their contributions concerning
recent or basic topics from the field of Computer Sciences until January 31st
2012. Proposals from the broad array of Informatics and its interdisciplinary
relations are welcome. We are also looking for lecturers with contributions
concerning studying, working and career. Informatica Feminale is part of the
regular course program at University of Bremen. Therefore, teaching assignment can
be given to lecturers. A program committee will make the selection of
contributions. Course languages are German and English.
There will be several possibilities for lectures and presentations during the
summer university for which we also search for contributions. Presentations with a
length of 30 to 60 minutes from lecturers of all fields are welcome.
We would like to point out the carrer fair 'Jobforum' of both Informatica Feminale
and Ingenieurinnen-Sommeruni on August 22nd 2012 for interested human resource
representatives. Furthermore there will be various chances to talk to graduates
during the whole summer university.
Informatica Feminale a place for experimentation, with the intention to develop
and imply new impulses in Informatics (Computer Science). It is also aiming at
professional networking of students as well as the extra occupational training of
women computer scientists on an academic level.
Please forward this Call for Contributions to interested colleagues, co-workers
and students.
Further information and the application form can be found here:
All female students who will soon write their theses, women interested in doing a PhD, PhD-students and those who are already postdocs are invited to the event female.2.enterprises on December 6th 2011, from 9.30 am to 4 pm, at the TechnologieZentrumDortmund.
This event offers detailed and personal insight and contact to companies, having talks with experts, and taking part in workshops for earning softskills.
The Cross-Layer Multi-Dimensional Design Space of Power, Reliability, Temperature and Voltage in Highly Scaled Geometries This talk addresses this notion of error-awareness across multiple abstraction layers – application, architectural platform, and technology – for next generation SoCs. The intent is to allow exploration and evaluation of a large, previously invisible design space exhibiting a wide range of power, performance, and cost attributes. To achieve this one must synergistically bring together expertise at each abstraction layer: in communication/multimedia applications, SoC architectural platforms, and advanced circuits/technology, in order to allow effective co-design across these abstraction layers. As an example, one may investigate methods to achieve acceptable QoS at different abstraction levels as a result of intentionally allowing errors to occur inside the hardware with the aim of trading that off for lower power, higher performance and/ or lower cost. Such approaches must be validated and tested in real applications. An ideal context for the convergence of such applications are handheld multimedia communication devices in which a WCDMA modem and an H.264 encoder must co-exist, potentially with other applications such as imaging. These applications have a wide scope, execute in highly dynamic environments and present interesting opportunities for tradeoff analysis and optimization. We also demonstrate how error awareness can be exploited at the architectural platform layer through the implementation of error tolerant caches that can operate at very low supply voltage.
Fay: Extensible Distributed Software Tracing from OS Kernels to Clusters
In this talk, I present Fay, a flexible platform for the efficient collection, processing, and analysis of software execution traces. Fay provides dynamic tracing through use of runtime instrumentation and distributed aggregation within machines and across clusters. At the lowest level, Fay can be safely extended with new tracing primitives, and Fay can be applied to running applications and operating system kernels without compromising system stability. At the highest level, Fay provides a unified, declarative means of specifying what events to trace, as well as the aggregation, processing, and analysis of those events.
We have implemented the Fay tracing platform for the Windows operating system and integrated it with two powerful, expressive systems for distributed programming. I will demonstrate the generality of Fay tracing, by showing how a range of existing tracing and data-mining strategies can be specified as Fay trace queries. Next, I will present experimental results using Fay that show that modern techniques for high-level querying and data-parallel processing of disaggregated data streams are well suited to comprehensive monitoring of software execution in distributed systems. Finally, I will show how Fay automatically derives optimized query plans and code for safe extensions from high-level trace queries that can equal or even surpass the performance of specialized monitoring tools.
more...Am 9. Dezember findet an der TU Dortmund eine Tagung von DPPD (Dortmunder politisch-philosophische Diskurse) mit dem Thema "Freiheit und Sicherheit" statt. Es wird dabei unter anderem auch um die Aspekte des Datenschutzes gehen. Es beginnt um 10 Uhr und endet gegen 16 Uhr. Für weitere Details zum Tagesablauf, Wegbeschreibung und Anmeldung siehe Flyer.
more...Confidentiality policies on the semantic web: Logic programming vs. Description logics. An increasing amount of information is being encoded via ontologies and knowledge representation languages of some sort. Some of these knowledge bases are encoded manually, while others are generated automatically by information extraction techniques. In order to protect the confidentiality of this information, a natural choice consists in encoding access control policies with the ontology language itself. This approach led to so-called "semantic web policies". The semantic web is founded on two knowledge representation languages: description logics and logic programs. In this talk we compare their expressive power as *policy* representation languages, and argue that logic programming approaches are currently more mature than description logics, although this picture may change in the near future.
more...Examining of possible approaches to the signal quantification for PAMONO-method
Tim Ruhe will present joint work with Katharina Morik within the IceCube collaboration (member: Wolfgang Rhode) at the International conference Astronomical Data Analysis Software & Systems XXI taking place in Paris, 6-10 November 2011. The title is "Data Mining Ice Cubes".
more...The Cross-Layer Multi-Dimensional Design Space of Power, Reliability, Temperature and Voltage in Highly Scaled Geometries This talk addresses this notion of error-awareness across multiple abstraction layers – application, architectural platform, and technology – for next generation SoCs. The intent is to allow exploration and evaluation of a large, previously invisible design space exhibiting a wide range of power, performance, and cost attributes. To achieve this one must synergistically bring together expertise at each abstraction layer: in communication/multimedia applications, SoC architectural platforms, and advanced circuits/technology, in order to allow effective co-design across these abstraction layers. As an example, one may investigate methods to achieve acceptable QoS at different abstraction levels as a result of intentionally allowing errors to occur inside the hardware with the aim of trading that off for lower power, higher performance and/ or lower cost. Such approaches must be validated and tested in real applications. An ideal context for the convergence of such applications are handheld multimedia communication devices in which a WCDMA modem and an H.264 encoder must co-exist, potentially with other applications such as imaging. These applications have a wide scope, execute in highly dynamic environments and present interesting opportunities for tradeoff analysis and optimization. We also demonstrate how error awareness can be exploited at the architectural platform layer through the implementation of error tolerant caches that can operate at very low supply voltage.
more...Time series data arise in diverse applications and their modeling poses several challenges to the data analyst. This track is concerned with the use of time series models and the associated computational methods for estimating them and assessing their fit. Special attention will be given to more recently proposed methods and models whose development made possible to attack data structures that cannot be modeled by standard methodology. Examples can arise from finance, marketing, medicine, meteorology etc.
more...Compressive Sensing (sparse recovery) predicts that sparse vectors can be recovered from what was previously believed to be highly incomplete linear measurements. Efficient algorithms such as convex relaxations and greedy algorithms can be used to perform the reconstruction. Remarkably, all good measurement matrices known so far in this context are based on randomness. Recently, it was observed that similar findings also hold for the recovery of low rank matrices from incomplete information, and for the matrix completion problem in particular. Again, convex relaxations and random are crucial ingredients. The talk gives an introduction and overview on sparse and low rank recovery with emphasis on results due to the speaker.
Cartification: from Similarities to Itemset Frequencies
Abstract:
Suppose we are given a multi-dimensional dataset. For every point in the dataset, we create a transaction, or cart, in which we store the k-nearest neighbors of that point for one of the given dimensions. The resulting collection of carts can then be used to mine frequent itemsets; that is, sets of points that are frequently seen together in some dimensions. Experimentation shows that finding clusters, outliers, cluster centers, or even subspace clustering becomes easy on the cartified dataset using state-of-the-art techniques in mining interesting itemsets.
The Next Generation of Data Mining (NGDM) Event Series explores emerging issues in the field of data mining by bringing researchers and practitioners from different fields. NGDM 2011 is co-located with ECML PKDD 2011.
more...The Maxine Research Virtual Machine The Maxine project is run at Oracle Labs and aims at providing a JVM that is binary compatible with the standard JVM while being implemented (almost) completely in Java. Since the open source release of the Maxine VM, it has progressed to the point where it can now run application servers such as Eclipse and Glassfish. With the recent addition of a new compiler that leverages the mature design behind the HotSpot server compiler (aka C2), the VM is on track to deliver performance on par with the HotSpot VM. At the same time, its adoption by VM researchers and enthusiasts is increasing. That is, we believe the productivity advantages of system level programming in Java are being realized. This talk will highlight and demonstrate the advantages of both the Maxine architecture and of meta-circular JVM development in general.
more...The annual ACM SIGKDD conference is the premier international forum for data mining researchers and practitioners from academia, industry, and government to share their ideas, research results and experiences. KDD-2011 will feature keynote presentations, oral paper presentations, poster sessions, workshops, tutorials, panels, exhibits, demonstrations, and the KDD Cup competition. KDD-2011 will run from August 21-24 in San Diego, CA and will feature hundreds of practitioners and academic data miners converging on the one location.
more...As part of project C1 - Feature selection in high dimensional data for risk prognosis in oncology - several new feature selection algorithms have been developed and publicly released. During his visit at the SFB, Viswanath Sivakumar implemented these algorithms as an extension to Rapidminer. The implementations are available for download on Sourceforge: RM-Featselext
A report about the SFB's work including presentation of exemplary projects has been published in the newsletter of the MODAP-Project, privacy on the move. MODAP focuses on preserving privacy for mobility data in mobile networks. The newsletter can be found as a PDF on the MODAP website.
more...Large media collections rapidly evolve in the World Wide Web. In addition to the targeted retrieval as is performed by search engines, browsing and explorative navigation is an important issue. Since the collections grow fast and authors most often do not annotate their web pages according to a given ontology, automatic structuring is in demand as a prerequisite for any pleasant human–computer interface. In this paper, we investigate the problem of finding alternative high-quality structures for navigation in a large collection of high-dimensional data. We express desired properties of frequent termset clustering (FTS) in terms of objective functions. In general, these functions are conflicting. This leads to the formulation of FTS clustering as a multi-objective optimization problem. The optimization is solved by a genetic algorithm. The result is a set of Pareto-optimal solutions. Users may choose their favorite type of a structure for their navigation through a collection or explore the different views given by the different optimal solutions.We explore the capability of the new approach to produce structures that are well suited for browsing on a social bookmarking data set.
more...The workshop is about „IT-Applications in the Ion Mobility Spectrometry – State of the technology, challenges and new features“. At the focus are TB1 as well as the cooperation with TU Dortmund, B&S Analytik, KIST Europe and MPII / University of Saarbrücken. The workshop starts on 3.8.2011 at 3pm and ends on 4.8.2011 at 1pm. It takes place at KIST Europe, Campus E7 1, 66123 Saarbrücken. For information on the work at KIST Europe and how to get there please visit www.kist-europe.com.
more...The slides of Gerd Brewka's speech on "Multi-Context Systems: Integrating Heterogeneous Knowledge Bases" are now available.
more...Prof. Peter Marwedel (Part Project Manager of the SFB 876 Part Projekts A3, A4 and B2) runs a tutorial on "Embedded System Foundations of Cyber-Physical Systems" in Beijing on August 8th 2011. For further information see http://www.artist-embedded.org/artist/Schedule,2321.html .
more...The next workshop on embedded system education will take place in Taipei on Oct. 13th, 2011 (during ESWEEK). The paper submission deadline is approaching. Please submit your paper by July 22nd. Details are enclosed.
more...
The bio.dortmund event at the 28th of September starting at 10.00 o'clock brings together regional players in bio technology. At the Leibniz-Institut für Analytische Wissenschaften ISAS Dortmund presentations and posters showcase recent research in bio technology.
The SFB 876 presents a short introduction in the data analysis in biomedical applications.
Energy-Aware COmputing (EACO) Beyond the State of the Art Purpose: To bring together researchers and engineers with interests in energy-aware computing for discussions to identify intellectual challenges that can be developed into collaborative research projects. We strive to go significantly beyond the state of the art.
more...Graphics processor (GPU) architectures: Graphics processor (GPU) architectures have evolved rapidly in recent years with increasing performance demanded by 3D graphics applications such as games. However, challenges exist in integrating complex GPUs into mobile devices because of power and energy constraints, motivating the need for energy efficiency in GPUs. While a significant amount of power optimization research effort has concentrated on the CPU system, GPU power efficiency is a relatively new and important area because the power consumed by GPUs is similar in magnitude to CPU power. Power and energy efficiency can be introduced into GPUs at many different levels: (i) Hardware component level - queue structures, caches, filter arithmetic units, interconnection networks, processor cores, etc., can be optimized for power. (ii) Algorithm level – the deep and complex graphics processing computation pipeline can be modified to be energy aware. Shader programs written by the user can be transformed to be energy aware. (iii) System level - co-ordination at the level of task allocation, voltage and frequency scaling, etc.
This workshop intends to bring together researchers from different research areas such as bioinformatics, biostatistics and systems biology, who are interested in modeling and analysis of biological systems or in the development of statistical methods with applications in biology and medicine.
more...
In October the SFB will held its internal workshop on the latest results in research. The recent advances in resource constraint data analysis will be presented as well as hands on-sessions on tools and methodology.
(Agenda download SFB876-members only)
Strategies for Scaling Data Mining Algorithms In today’s world, data is collected/generated at an normous rate in a variety of disciplines starting from mechanical systems e.g. airplanes, cars, etc., sensor networks, Earth sciences, to social networks e.g. facebook. Many of the existing data analysis algorithms do not scale to such large datasets. In this talk, first I will discuss a technique for speeding up such algorithms by distributing the workload among the nodes of a cluster of computers or a multicore computer. Then, I will present a highly scalable distributed regression algorithm relying on the above technique which adapts to changes in the data and converges to the correct result. If time permits, I also plan to discuss a scalable outlier detection algorithm which is at least an order of magnitude faster than the existing methods. All of the algorithms that I discuss will offer provable correctness guarantees compared to a centralized execution of the same algorithm. Regression Algorithms for Large Scale Earth Science Data There has been a tremendous increase in the volume of Earth Science data over the last decade. Data is collected from modern satellites, in-situ sensors and different climate models. Information extraction from such rich data sources using advanced data mining and machine learning techniques is a challenging task due to their massive volume. My research focuses on developing highly scalable machine learning/algorithms, often using distributed computing setups like parallel/cluster computing. In this talk I will discuss regression algorithms for very large data sets from the Earth Science domain. Although simple linear regression techniques are based on decomposable computation primitives, and therefore are easily parallelizable, they fail to capture the non-linear relationships in the training data. In this talk, I will describe Block-GP, a scalable Gaussian Process regression framework for multimodal data, that can be an order of magnitude more scalable than existing state-of-the-art nonlinear regression algorithms.
more...Multi-Context Systems: A Flexible Approach for Integrating Heterogeneous Knowledge Sources In this talk we give an overview on multi-context systems (MCS) with a special focus on their recent nonmonotonic extensions. MCS provide a flexible, principled account of integrating heterogeneous knowledge sources, a task that is becoming more and more relevant. By a knowledge source we mean a knowledge base (KB) formulated in any of the typical knowledge representation languages, including classical logic, description logics, modal or temporal logics, but also nonmonotonic formalisms like logic programs under answer set semantics or default logic. The basic idea is to describe the information flow among different KBs declaratively, using so-called bridge rules. The semantics of MCS is based on the definition of an equilibrium. We will motivate the need for such systems, describe what has been achieved in this area, discuss work in progress and introduce generalizations of the existing framework which we consider useful.
more...
Network Coding for resource-efficient operation of mobile clouds:
The mobile communication architecture is changing dramatically, from formerly fully centralized systems, the mobile devices are getting connected among each other forming so called mobile clouds. One of the key technologies for mobile clouds is network coding. Network coding changes the way how mobile communication systems will be designed in the future. In contrast to source or channel coding, network coding is not end to end oriented, but allows on the fly recoding. The talk will advocate the need of network coding for mobile clouds.
Graphics processor (GPU) architectures: Graphics processor (GPU) architectures have evolved rapidly in recent years with increasing performance demanded by 3D graphics applications such as games. However, challenges exist in integrating complex GPUs into mobile devices because of power and energy constraints, motivating the need for energy efficiency in GPUs. While a significant amount of power optimization research effort has concentrated on the CPU system, GPU power efficiency is a relatively new and important area because the power consumed by GPUs is similar in magnitude to CPU power. Power and energy efficiency can be introduced into GPUs at many different levels: (i) Hardware component level - queue structures, caches, filter arithmetic units, interconnection networks, processor cores, etc., can be optimized for power. (ii) Algorithm level – the deep and complex graphics processing computation pipeline can be modified to be energy aware. Shader programs written by the user can be transformed to be energy aware. (iii) System level - co-ordination at the level of task allocation, voltage and frequency scaling, etc., requires knowledge and control of several different GPU system components. We outline two strategies for applying energy optimizations at different levels of granularity in a GPU. (1) Texture Filter Memory is an energy-efficient an augmentation of the standard GPU texture cache hierarchy. Instead of a regular data cache hierarchy, we employ a small first level register based structure that is optimized for the relatively predictable memory access stream in the texture filtering computation. Power is saved by avoiding the expensive tag lookup and comparisons present in regular caches. Further, the texture filter memory is a very small structure, whose access energy is much smaller than a data cache of similar performance. (2) Dynamic Voltage and Frequency Scaling, an established energy management technique, can be applied in GPUs by first predicting the workload in a given frame, and, where sufficient slack exists, lowering the voltage and frequency levels so as to save energy while still completing the work within the frame rendering deadline. We apply DVFS in a tiled graphics renderer, where the workload prediction and voltage/frequency adjustment is performed at a tile-level of granularity, which creates opportunities for on-the-fly correction of prediction inaccuracies, ensuring high frame rates while still delivering low power.
more...The planned presentation of Prof. Bonatti has to be canceled due to personal reasons of the presenter.
more...Network Coding for resource-efficient operation of mobile clouds: The mobile communication architecture is changing dramatically, from formerly fully centralized systems, the mobile devices are getting connected among each other forming so called mobile clouds. One of the key technologies for mobile clouds is network coding. Network coding changes the way how mobile communication systems will be designed in the future. In contrast to source or channel coding, network coding is not end to end oriented, but allows on the fly recoding. The talk will advocate the need of network coding for mobile clouds.
more...
We observe that in diverse applications ranging from stock trading to traffic monitoring, data streams are continuously monitored by multiple analysts for extracting patterns of interest in real-time. Such complex pattern mining requests cover a broad range of popular mining query types, including detection of clusters, outliers, nearest neighbors, and top-k requests. These analysts often submit similar pattern mining requests yet customized with different parameter settings. In this work, we exploit classical principles for core database technology, namely, multi-query optimization, now in the context of data mining.
Emerging and envisioned applications within domains such as indoor navigation, fire-fighting, and precision agriculture still pose challenges for existing positioning solutions to operate accurately, reliably, and robustly in a variety of environments and conditions and under various application-specific constraints. This talk will first give a brief overview of efforts made in a Danish project to address challenges as mentioned above, and will subsequently focus on addressing the energy constraints imposed by Location-based Services (LBS), running on mobile user devices such as smartphones. A variety of LBS, including services for navigation, location-based search, social networking, games, and health and sports trackers, demand the positioning and trajectory tracking of smartphones. To be useful, such tracking has to be energy-efficient to avoid having a major impact on the battery life of the mobile device, since the battery capacity in modern smartphones is a scarce resource, and is not increasing at the same pace as new power-demanding features, including various positioning sensors, are added to such devices. We present novel on-device sensor management and trajectory updating strategies which intelligently determine when to sample different on-device positioning sensors (accelerometer, compass and GPS) and when data should be sent to a remote server and to which extent to simplify it beforehand in order to save communication costs. The resulting system is provided as uniform framework for both position and trajectory tracking and is configurable with regards to accuracy requirements. The effectiveness of our approach and the energy savings achievable are demonstrated both by emulation experiments using real-world data and by real-world deployments.
more...The ArtistDesign European Network of Excellence on Embedded Systems Design is organizing the 7th edition of it's highly successful "ARTIST Summer School in Europe", September 4-9th 2011 (http://www.artist-embedded.org/artist/-ARTIST-Summer-School-Europe-2011-.ht ml - funded by the European Commission). This is the seventh edition of yearly schools on embedded systems design, and is meant to be exceptional in terms of both breadth of coverage and invited speakers. This school brings together some of the best lecturers from Europe, USA and China in a 6-day programme, and will be a fantastic opportunity for interaction. It will be held in beautiful Aix-les-Bains, near Grenoble - France (see webpage for details and photos). Past participants are also encouraged to apply! The ARTIST Summer School 2011 will be held near Grenoble by the magnificent Lac du Bourget and the French Alps in the historic city of Aix-les-Bains. It features a luxury spa with full services, pool, sauna, hammam, tennis courts and open space. The social programme includes ample time for discussion, and a visit to the historic city of Annecy with a gala dinner while touring the lake of Annecy. Deadline for applications is May 15th 2011. Attendance is limited, so we will be selecting amongst the candidates. Registration fees include the technical and social programmes, 6 days' meals and lodging (2-3 persons/room) from dinner Saturday Sept 3rd through Friday 9th lunch, social programme, and bus transport from/to the St Exupéry or Geneva airports. The registration fee only partially covers the costs incurred. The remaining costs are covered by the European Commission?s 7th Framework Programme ICT. The programme will offer world-class courses and significant opportunities for interaction with leading researchers in the area:
Mapping of applications to MPSoCs is one of the hottest topics resulting
from the availability of multi-core processors. The ArtistDesign workshop on
this topic has become a key event for discussing approaches for solving the
problems. This year, the workshop will again be held back-to-back with the SCOPES workshop.
Recent technological trends have led to the introduction of multi-processor systems on a chip (MPSoCs). It can be expected that the number of processors on such chips will continue to increase. Power efficiency is frequently the driving force having a strong impact on the architectures being used. As a result, heterogeneous architectures incorporating functional units optimized for specific functions are commonly employed. This technological trend has dramatic consequences on the design technology. Techniques are required, which map sets of applications onto architectures of MPSoCs.
Deadline for Abstract Submissions is April, 22nd.
We observe that in diverse applications ranging from stock trading to traffic monitoring, data streams are continuously monitored by multiple analysts for extracting patterns of interest in real-time. Such complex pattern mining requests cover a broad range of popular mining query types, including detection of clusters, outliers, nearest neighbors, and top-k requests. These analysts often submit similar pattern mining requests yet customized with different parameter settings. In this work, we exploit classical principles for core database technology, namely, multi-query optimization, now in the context of data mining.
more...
The new Collaborative Research Center SFB 876 "Providing Information by Resource-Constrained Data Analysis" starts the new year with a kick-off colloquium.
The colloquium takes place on January 20th 2011 starting at 4 pm at auditorium E23, Otto-Hahn-Straße 14, TU Dortmund University campus.
For further information about the program and speeches please have a look at the attachment.
At this time, no futher applications for open positions at the SFB 876 are being accepted.
The DFG granted the SFB 876.


