
The CRC 876 brings together the research areas of data analysis (data mining, machine learning, statistics) and embedded systems (cyber-physical systems) and expands them such that information from distributed, dynamic data masses becomes available for decision processes in real-time, on site. The acquisition and storage of high-throughput experiments in biomedicine, astrophysical telescopes or particle-physical experiments exceeds the capacity of todayâs computers, so that the analysis must be pushed to the edge, i.e., to the sensor. Also, the analysis of production processes that leads to direct interventions and the prediction of traffic for a better mobility management would benefit from at least a partial analysis at the data sources. The analysis of distributed, streaming data requires novel algorithms and models, that take into account the resource restrictions. Already at the start of our CRC 876, we pointed out that data analysis should inspect more closely its execution on diverse platforms. We defined resource constraints as the relation between the demands of analysing big data and the technical capabilities of a platform or device.

In the first phase of funding, the interdisciplinary collaboration within computer science was set up. Each discipline inspected the resource constraints. Resource restrictions of computers are always to be seen in relation to the data. While they are immediately noticeable in small, embedded systems, they also apply to large computer systems and centres for particularly large, high-dimensional, distributed, dynamic or complex data. This put the restrictions of energy, computing time, memory, and communication to the front of research.
In the second funding phase of the CRC 876, work on data analysis and on embedded systems have become integrated because of the common focus on resources. Energy measurements and energy harvesting have been pushed to ultra-low power-devices. At the same time, energy con sumption of main memory processes and machine learning has been investigated. A common basis of understanding between the disciplines has been established.
The third phase now aims at indicating resource requirements and quality bounds for models of learning on hardware architectures. The goal is to develop models of learning with clear characteristics of resource demands and quality guarantees so that most resource-efficient combinations of machine learning and embedded systems together with algorithmic enhancements and well tailored data storage are indicated.
After the CRC 876, users may easily select learning methods and compose workflows for diverse hardware – balancing energy, memory consumption and communication requirements on the one hand and prediction, prescription and performance on the other hand.
According to the 2017 white paper by Seagate and IDC on the Data Age 2025 data will reach 163 Zettabytes by 2025. This is also due to the trend from centralised to embedded systems. The number of embedded system devices that feed the data centre per person globally is estimated to grow from 1 in 2017 to more than 4 in 2025. The number of interactions per day per person is estimated to become 4800 in 2025. The majority of the data does not need to be stored, but only be used and then discarded. This means that data must be analysed on the fly. It requires intelligent decision making, which data to store and in which aggregated way for further use. Moreover, the trend to real-time data and their use in life-critical applications such as autonomous cars or remote medical patient devices, challenges data analysis even further.
The novel data ecosystems no longer allow to take the von Neumann architecture for granted where only compilers or application systems had to address hardware issues. Already at the start of our CRC, we have pointed out that data analysis is necessary for coping with big data and that we should inspect more closely its execution on diverse platforms. We defined resource constraints as the relation between the demands of analysing data of high volume and high velocity and the technical capabilities of a platform or device. We expressed this view by our logo and used it as the structure of the CRC.
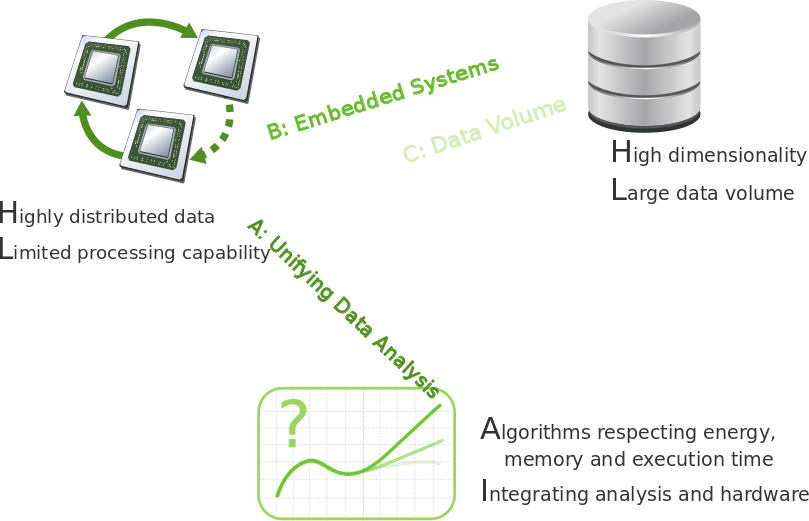
We are continuously progressing along the path we designed in the beginning. It turns out that the path fits well into the international landscape, because we already planned for a state that now starts to be recognised. Now, let us look at the CRC in a more technical perspective, summarising the current state of its research and naming the tasks for the next phase of funding. We structure the CRC contributions along the following research topics:
More information on individual research areas can be found using the links below.